
Path: blob/main/08. Data Visualization with Python/01. Preparing the Canada Immigration Dataset.ipynb
8174 views
Preparing the Canada Immigration Dataset with pandas
Toolkits: The course heavily relies on pandas and Numpy for data wrangling, analysis, and visualization. The primary plotting library we will explore in the course is Matplotlib.
Dataset: Immigration to Canada from 1980 to 2013 - International migration flows to and from selected countries - The 2015 revision from United Nation's website.
The dataset contains annual data on the flows of international migrants as recorded by the countries of destination. The data presents both inflows and outflows according to the place of birth, citizenship or place of previous / next residence both for foreigners and nationals. In this lab, we will focus on the Canadian Immigration data.
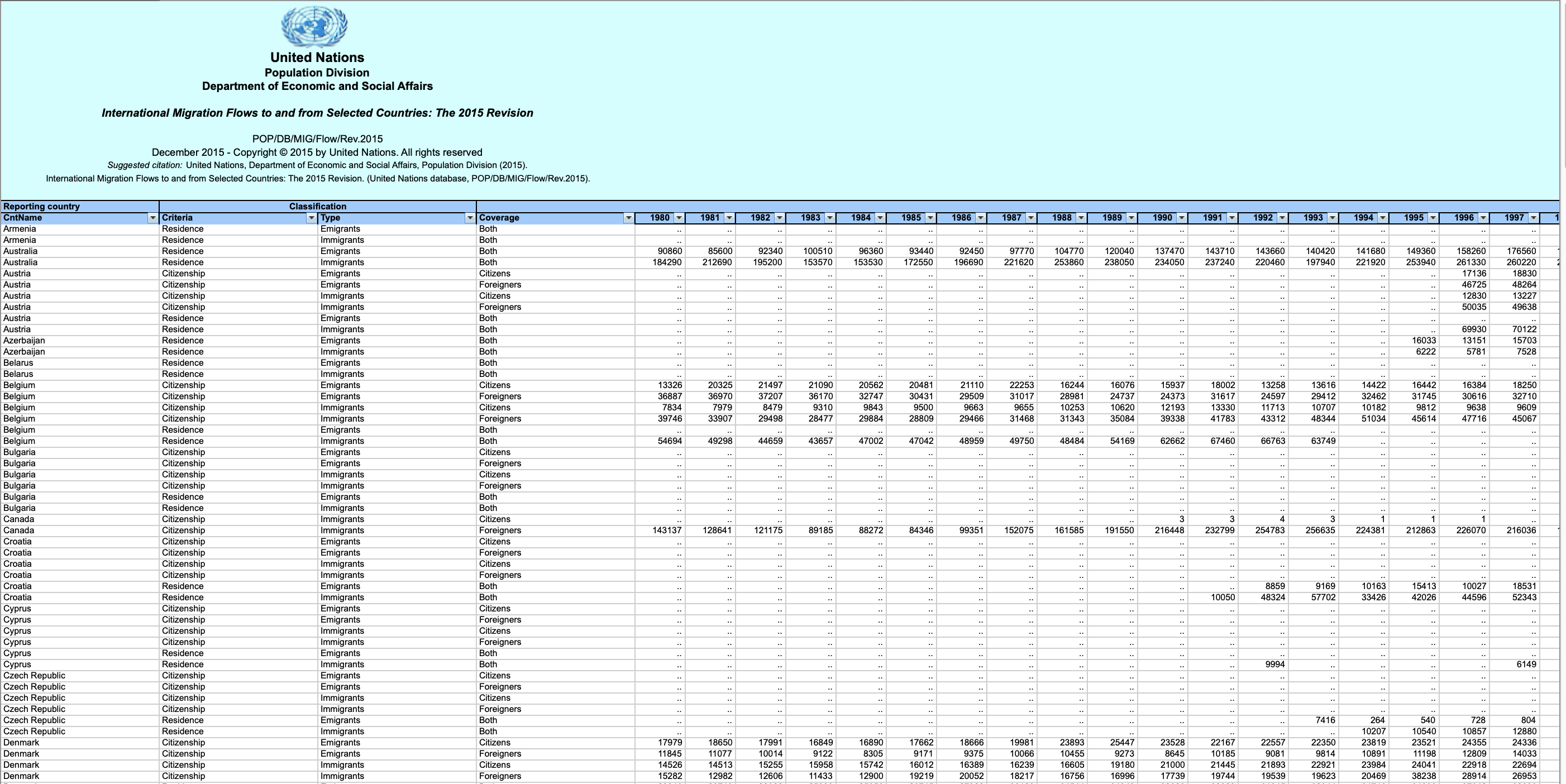
The Canada Immigration dataset can be fetched from here.
Downloading and Prepping Data
Download the dataset and read it into a pandas dataframe.
Explore the dataset
To view the dimensions of the dataframe, we use the shape instance variable of it.
When analyzing a dataset, it's always a good idea to start by getting basic information about your dataframe. We can do this by using the info() method.
This method can be used to get a short summary of the dataframe.
To get the list of column headers we can call upon the data frame's columns instance variable.
Similarly, to get the list of indices we use the .index instance variables.
Note: The default type of instance variables index and columns are NOT list.
To get the index and columns as lists, we can use the tolist() method.
Note: The main types stored in pandas objects are float, int, bool, datetime64[ns], datetime64[ns, tz], timedelta[ns], category, and object (string). In addition, these dtypes have item sizes, e.g. int64 and int32.
Cleanse the data
Let's clean the data set to remove a few unnecessary columns. We can use pandas drop() method as follows:
Let's rename the columns so that they make sense. We can use rename() method by passing in a dictionary of old and new names as follows:
For sake of consistency, let's also make all column labels of type string.
Set the country name as index - useful for quickly looking up countries using .loc method
We will also add a 'Total' column that sums up the total immigrants by country over the entire period 1980 - 2013, as follows:
Now the dataframe has an extra column that presents the total number of immigrants from each country in the dataset from 1980 - 2013. So if we print the dimension of the data, we get:
So now our dataframe has 38 columns instead of 37 columns that we had before.
Finally, let's view a quick summary of each column in our dataframe using the describe() method.