
Path: blob/main/08. Data Visualization with Python/07. Folium - Creating Maps and Visualizing Geospatial Data.ipynb
8161 views
Folium - Generating Maps and Visualizing Geospatial Data
Introduction
In this lab, we will learn how to create maps for different objectives. To do that, we will part ways with Matplotlib and work with another Python visualization library, namely Folium. What is nice about Folium is that it was developed for the sole purpose of visualizing geospatial data. While other libraries are available to visualize geospatial data, such as plotly, they might have a cap on how many API calls you can make within a defined time frame. Folium, on the other hand, is completely free.
Exploring Datasets with pandas and Matplotlib
Toolkits: This lab heavily relies on pandas and Numpy for data wrangling, analysis, and visualization. The primary plotting library we will explore in this lab is Folium.
Datasets:
San Francisco Police Department Incidents for the year 2016 - Police Department Incidents from San Francisco public data portal. Incidents derived from San Francisco Police Department (SFPD) Crime Incident Reporting system. Updated daily, showing data for the entire year of 2016. Address and location has been anonymized by moving to mid-block or to an intersection.
Immigration to Canada from 1980 to 2013 - International migration flows to and from selected countries - The 2015 revision from United Nation's website. The dataset contains annual data on the flows of international migrants as recorded by the countries of destination. The data presents both inflows and outflows according to the place of birth, citizenship or place of previous / next residence both for foreigners and nationals. For this lesson, we will focus on the Canadian Immigration data
Import Primary Modules:
Folium is a powerful Python library that helps you create several types of Leaflet maps. The fact that the Folium results are interactive makes this library very useful for dashboard building.
From the official Folium documentation page:
Folium builds on the data wrangling strengths of the Python ecosystem and the mapping strengths of the Leaflet.js library. Manipulate your data in Python, then visualize it in on a Leaflet map via Folium.
Folium makes it easy to visualize data that's been manipulated in Python on an interactive Leaflet map. It enables both the binding of data to a map for choropleth visualizations as well as passing Vincent/Vega visualizations as markers on the map.
The library has a number of built-in tilesets from OpenStreetMap, Mapbox, and Stamen, and supports custom tilesets with Mapbox or Cloudmade API keys. Folium supports both GeoJSON and TopoJSON overlays, as well as the binding of data to those overlays to create choropleth maps with color-brewer color schemes.
Let's install Folium
Folium is not available by default. So, we first need to install it before we are able to import it.
Generating the world map is straightforward in Folium. You simply create a Folium Map object, and then you display it. What is attractive about Folium maps is that they are interactive, so you can zoom into any region of interest despite the initial zoom level.
Go ahead. Try zooming in and out of the rendered map above.
You can customize this default definition of the world map by specifying the centre of your map, and the initial zoom level.
All locations on a map are defined by their respective Latitude and Longitude values. So you can create a map and pass in a center of Latitude and Longitude values of [0, 0].
For a defined center, you can also define the initial zoom level into that location when the map is rendered. The higher the zoom level the more the map is zoomed into the center.
Let's create a map centered around Canada and play with the zoom level to see how it affects the rendered map.
Let's create the map again with a higher zoom level.
As you can see, the higher the zoom level the more the map is zoomed into the given center.
Question: Create a map of Mexico with a zoom level of 4.
Another cool feature of Folium is that you can generate different map styles.
A. Stamen Toner Maps
These are high-contrast B+W (black and white) maps. They are perfect for data mashups and exploring river meanders and coastal zones.
Let's create a Stamen Toner map of canada with a zoom level of 4.
Feel free to zoom in and out to see how this style compares to the default one.
B. Stamen Terrain Maps
These are maps that feature hill shading and natural vegetation colors. They showcase advanced labeling and linework generalization of dual-carriageway roads.
Let's create a Stamen Terrain map of Canada with zoom level 4.
Feel free to zoom in and out to see how this style compares to Stamen Toner, and the default style.
Zoom in and notice how the borders start showing as you zoom in, and the displayed country names are in English.
Question: Create a map of Mexico to visualize its hill shading and natural vegetation. Use a zoom level of 6.
Let's download and import the data on police department incidents using pandas read_csv() method.
Download the dataset and read it into a pandas dataframe:
Let's take a look at the first five items in our dataset.
So each row consists of 13 features:
IncidntNum: Incident Number
Category: Category of crime or incident
Descript: Description of the crime or incident
DayOfWeek: The day of week on which the incident occurred
Date: The Date on which the incident occurred
Time: The time of day on which the incident occurred
PdDistrict: The police department district
Resolution: The resolution of the crime in terms whether the perpetrator was arrested or not
Address: The closest address to where the incident took place
X: The longitude value of the crime location
Y: The latitude value of the crime location
Location: A tuple of the latitude and the longitude values
PdId: The police department ID
Let's find out how many entries there are in our dataset.
So the dataframe consists of 150,500 crimes, which took place in the year 2016. In order to reduce computational cost, let's just work with the first 100 incidents in this dataset.
Let's confirm that our dataframe now consists only of 100 crimes.
Now that we reduced the data a little, let's visualize where these crimes took place in the city of San Francisco. We will use the default style, and we will initialize the zoom level to 12.
Now let's superimpose the locations of the crimes onto the map. The way to do that in Folium is to create a feature group with its own features and style and then add it to the sanfran_map.
You can also add some pop-up text that would get displayed when you hover over a marker. Let's make each marker display the category of the crime when hovered over.
Isn't this really cool? Now you are able to know what crime category occurred at each marker.
If you find the map to be so congested will all these markers, there are two remedies to this problem. The simpler solution is to remove these location markers and just add the text to the circle markers themselves as follows:
The other proper remedy is to group the markers into different clusters. Each cluster is then represented by the number of crimes in each neighborhood. These clusters can be thought of as pockets of San Francisco which you can then analyze separately.
To implement this, we start off by instantiating a MarkerCluster object and adding all the data points in the dataframe to this object.
Notice how when you zoom out all the way, all markers are grouped into one cluster, the global cluster, of 100 markers or crimes, which is the total number of crimes in our dataframe. Once you start zooming in, the global cluster will start breaking up into smaller clusters. Zooming in all the way will result in individual markers.
Choropleth Maps
A Choropleth map is a thematic map in which areas are shaded or patterned in proportion to the measurement of the statistical variable being displayed on the map, such as population density or per-capita income. The choropleth map provides an easy way to visualize how a measurement varies across a geographic area, or it shows the level of variability within a region. Below is a Choropleth map of the US depicting the population by square mile per state.
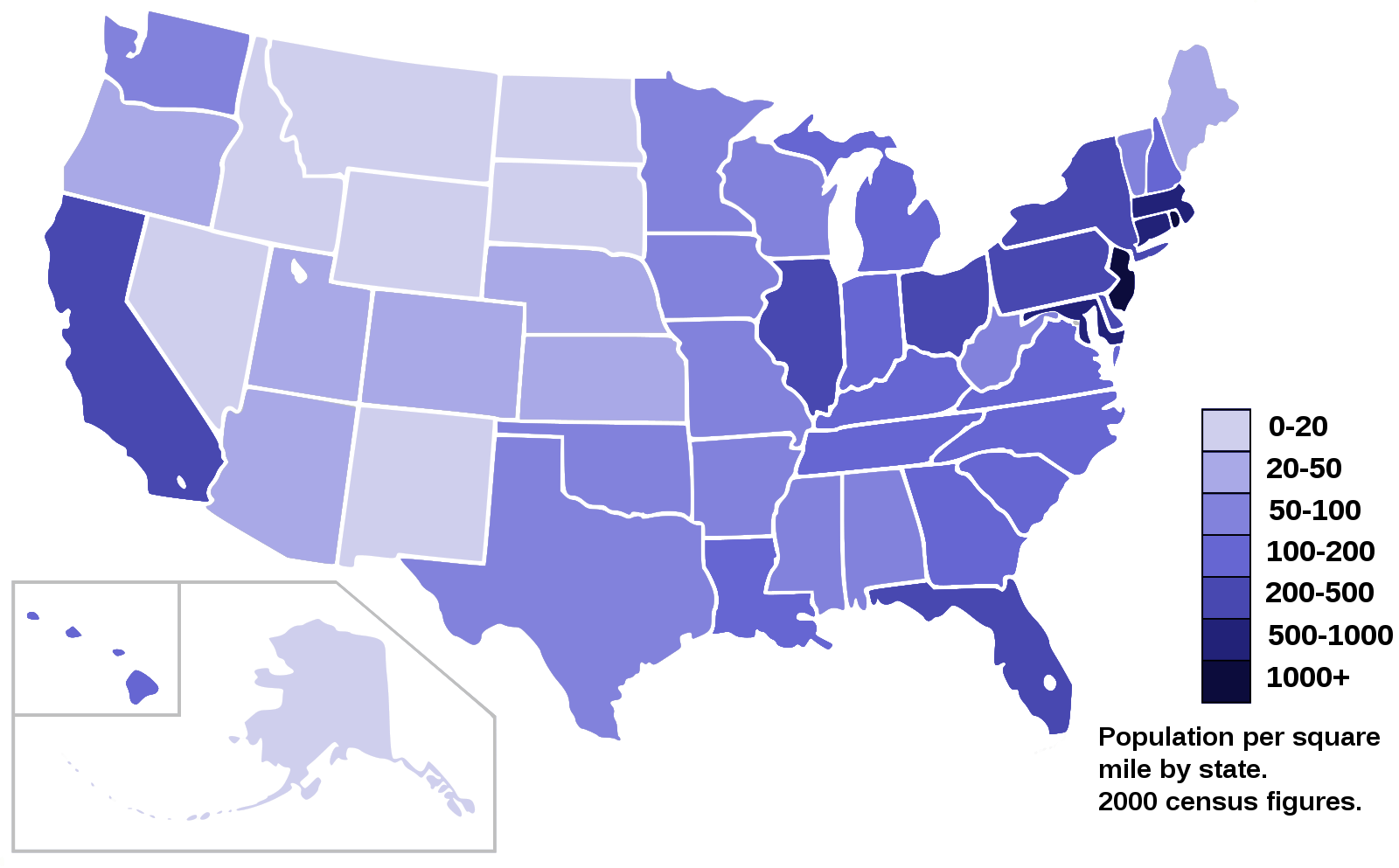
Now, let's create our own Choropleth map of the world depicting immigration from various countries to Canada.
Let's download and import our primary Canadian Immigration dataset using pandas's read_csv() method.
The file was originally downloaded from 'https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DV0101EN-SkillsNetwork/Data Files/Canada.xlsx', and then prepared in the previous notebook.
Set the country name as index - useful for quickly looking up countries using .loc method
Download the dataset and read it into a pandas dataframe:
Make a list of the years between 1980 and 2014.
In order to create a Choropleth map, we need a GeoJSON file that defines the areas/boundaries of the state, county, or country that we are interested in. In our case, since we are endeavoring to create a world map, we want a GeoJSON that defines the boundaries of all world countries. For your convenience, we will be providing you with this file, so let's go ahead and download it. Let's name it world_countries.json.
Now that we have the GeoJSON file, let's create a world map, centered around [0, 0] latitude and longitude values, with an initisal zoom level of 2.
And now to create a Choropleth map, we will use the choropleth method with the following main parameters:
geo_data, which is the GeoJSON file.data, which is the dataframe containing the data.columns, which represents the columns in the dataframe that will be used to create theChoroplethmap.key_on, which is the key or variable in the GeoJSON file that contains the name of the variable of interest. To determine that, you will need to open the GeoJSON file using any text editor and note the name of the key or variable that contains the name of the countries, since the countries are our variable of interest. In this case, name is the key in the GeoJSON file that contains the name of the countries. Note that this key is case_sensitive, so you need to pass exactly as it exists in the GeoJSON file.
As per our Choropleth map legend, the darker the color of a country and the closer the color to red, the higher the number of immigrants from that country. Accordingly, the highest immigration over the course of 33 years (from 1980 to 2013) was from China, India, and the Philippines, followed by Poland, Pakistan, and interestingly, the US.
Notice how the legend is displaying a negative boundary or threshold. Let's fix that by defining our own thresholds and starting with 0 instead of -6,918!