
Accelerating Quantum Computing: A Step-by-Step Guide to Expanding Simulation Capabilities and Enabling Interoperability of Quantum Hardware
Overview of methods of accelerating quantum simulation with GPUs
This notebook includes the following:
Introduction to CUDA-Q through two Hello World examples using
sampleandobservecalls.Guide to different backends for executing quantum circuits, emphasizing a variety of patterns of parallelization:
Statevector memory over multiple processors for simulation
Circuit sampling over multiple processors
Hamiltonian batching
Circuit cutting
Quantum hardware
Hello World Examples
In the first example below, we demonstrate how to define and sample a quantum kernel that encodes a quantum circuit.
Now it's your turn to try it out.
Exercise 1: Edit the code below to create a kernel that produces a circuit for the GHZ state with 4 qubits
The next example illustrates a few things:
Kernels can be used to define subcircuits.
cudaq.drawcan produce ascii or LaTeX circuit diagramsWe can define Hamiltonians with
spinoperators and compute expecation values withobserve.
Guide to Different Simulation Targets
The figure below illustrates a few options for accelerating statevector simulations of single quantum processor kernel executions on one CPU, one GPU, or a multi-node, multi-GPU system.
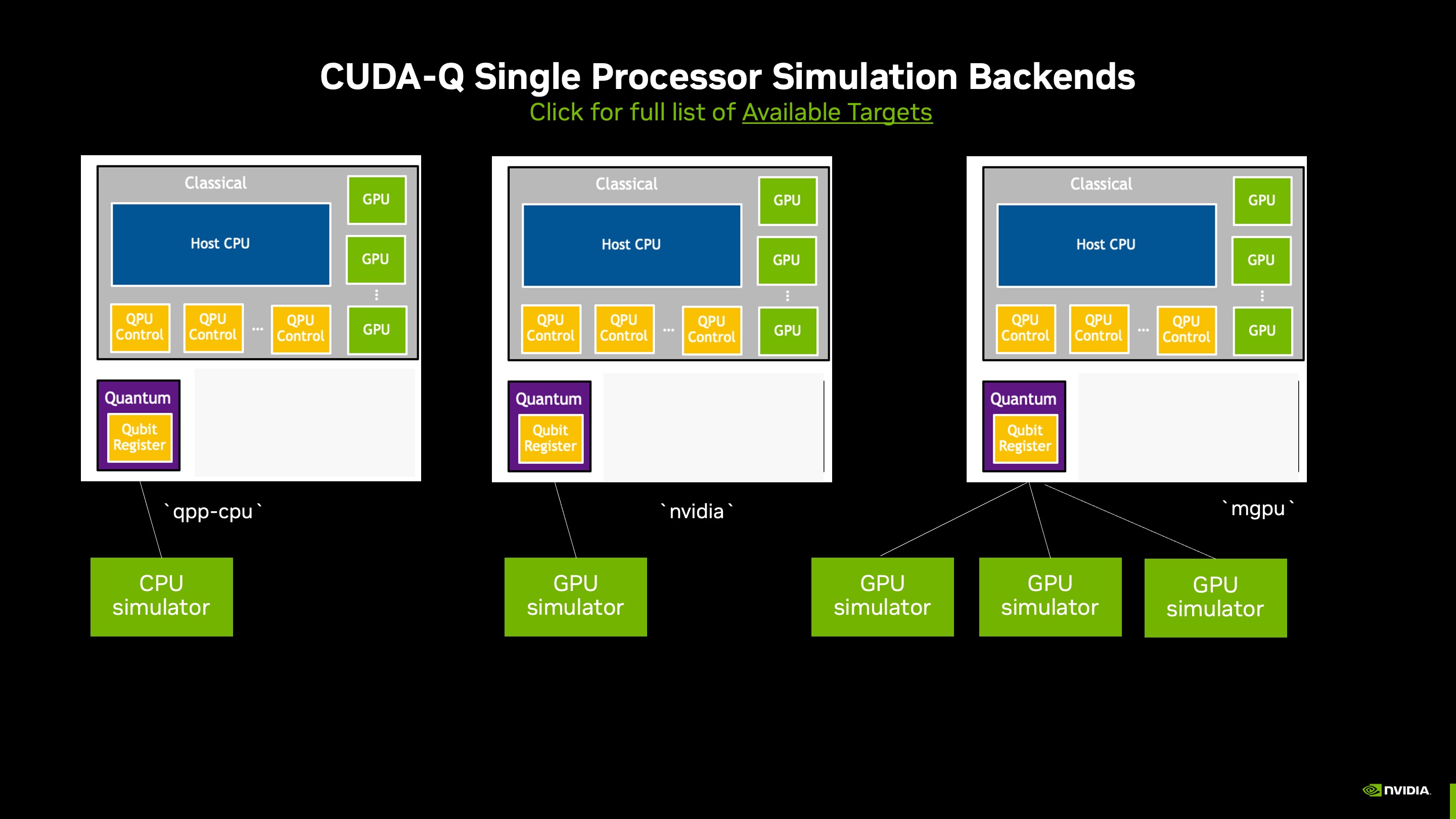
In the Hello World examples in the previous section, we saw statevector simulations of a QPU on a CPU. When GPU resources are available, we can use a single-GPU or multi-node, multi-GPU systems for fast statevector simulations. The nvidia target accelerates statevector simulations through cuStateVec library. This target offers a variety of configuration options:
Single-precision GPU simulation (default): The default of setting the target to
nvidiathrough the commandcudaq.set_target('nvidia')provides single (fp32) precision statevector simulation on one GPU.Double fp64 precision on a single-GPU: The option
cudaq.set_target('nvidia', option='fp64')increases the precision of the statevector simulation on one GPU.Multi-node, multi-GPU simulation: To run the
cuStateVecsimulator on multiple GPUs, set the target tonvidiawith themgpuoption (cudaq.set_target('nvidia', option='mgpu,fp64')) and then run the python file containing your quantum kernels within aMPIcontext:mpiexec -np 2 python3 program.py. Adjust the-nptag according to the number of GPUs you have available.
Next, we'll cover a few of the ways you can organize the distribution of quantum simulations over multiple GPU processors, whether you are simulating a single quantum processing unit (QPU) or multiple QPUs.
Single-QPU Statevector Simulations
In some cases, the memory required to hold the entire statevector for a simulation exceeds the memory of a single GPU. In these cases, we can distribute the statevector across multiple GPUs as the diagram in the image below suggests.

This is handled automatically within the mgpu option when the number of qubits in the statevector exceeds 25. By changing the environmental variable CUDAQ_MGPU_NQUBITS_THRESH prior to setting the target, you can change the threshold at which the statevector distribution is invoked.
Simulating Parallel QPU computaiton
Future quantum computers will accelerate performance by linking multiple QPUs for parallel processing. Today, you can simulate and test programs for these systems using GPUs, and with minimal changes to the target platform, the same code can be executed on multi-QPU setups once they are developed.
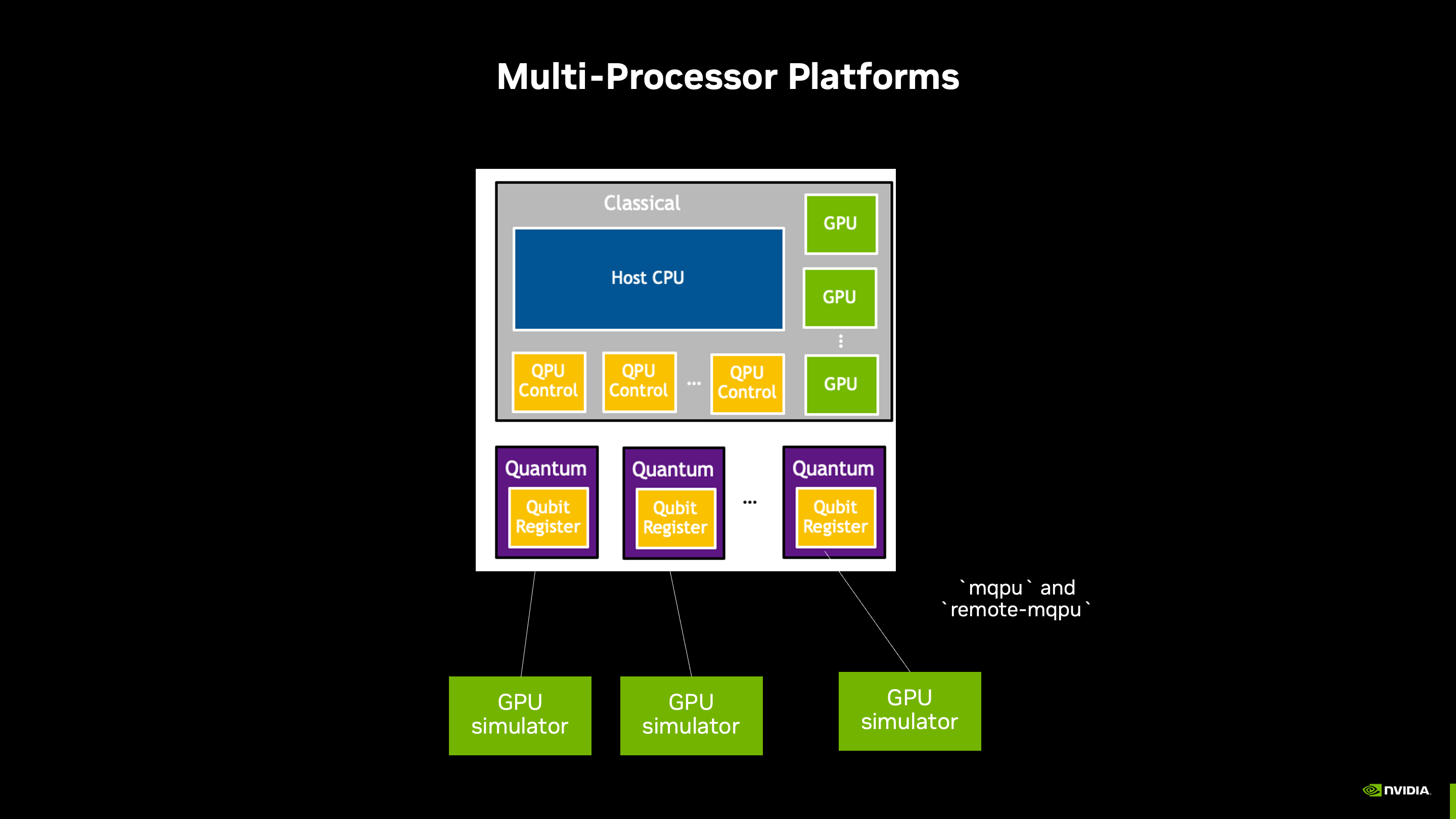
We'll examine a few multi-QPU parallelization patterns here:
Circuit sampling distributed over multiple processors
Hamiltonian batching
Circuit cutting
Circuit Sampling
One method of parallelization is to sample a circuit over several processors as illustrated in the diagram below.
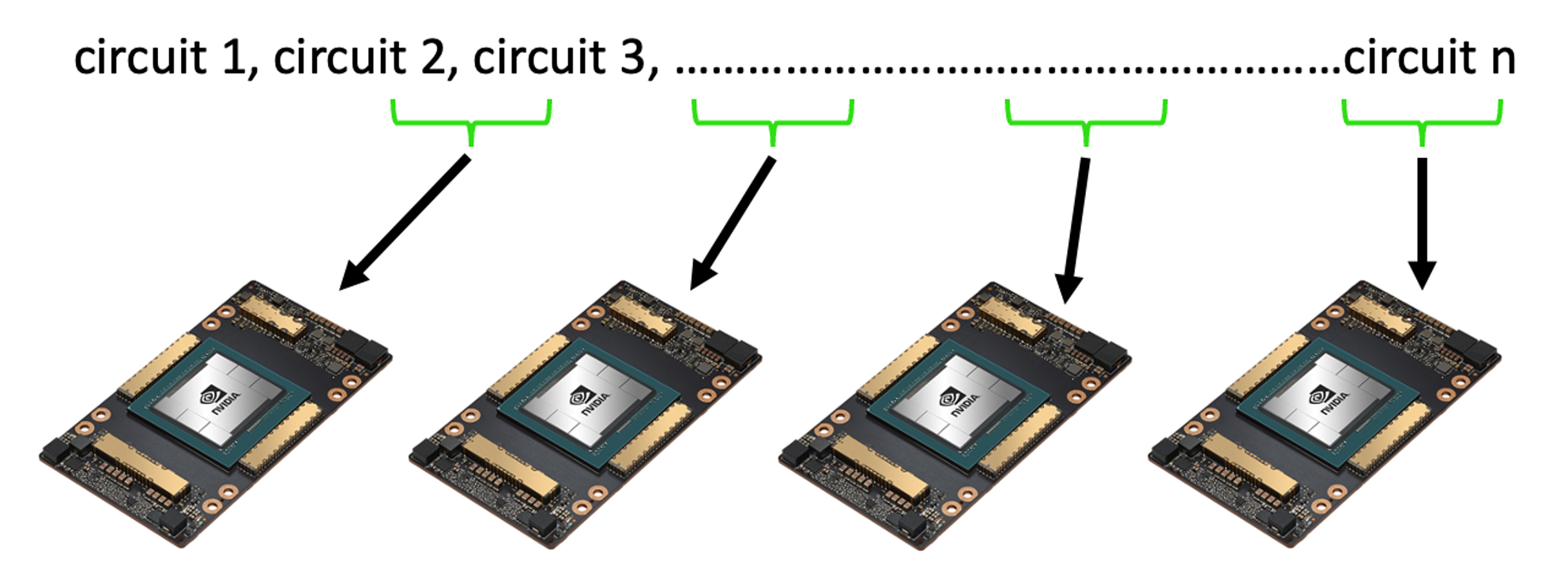
Check out the documentation for code that demonstrates how to launch asynchronous sampling tasks using sample_async on multiple virtual QPUs, each simulated by a tensornet simulator backend using the remote-mqpu target.
Hamiltonian Batching
Another method for distributing the computational load in a simulation is Hamiltonian batching. In this approach, the expectation values of the Hamiltonian's terms are calculated in parallel across several virtual QPUs, as illustrated in the image below.
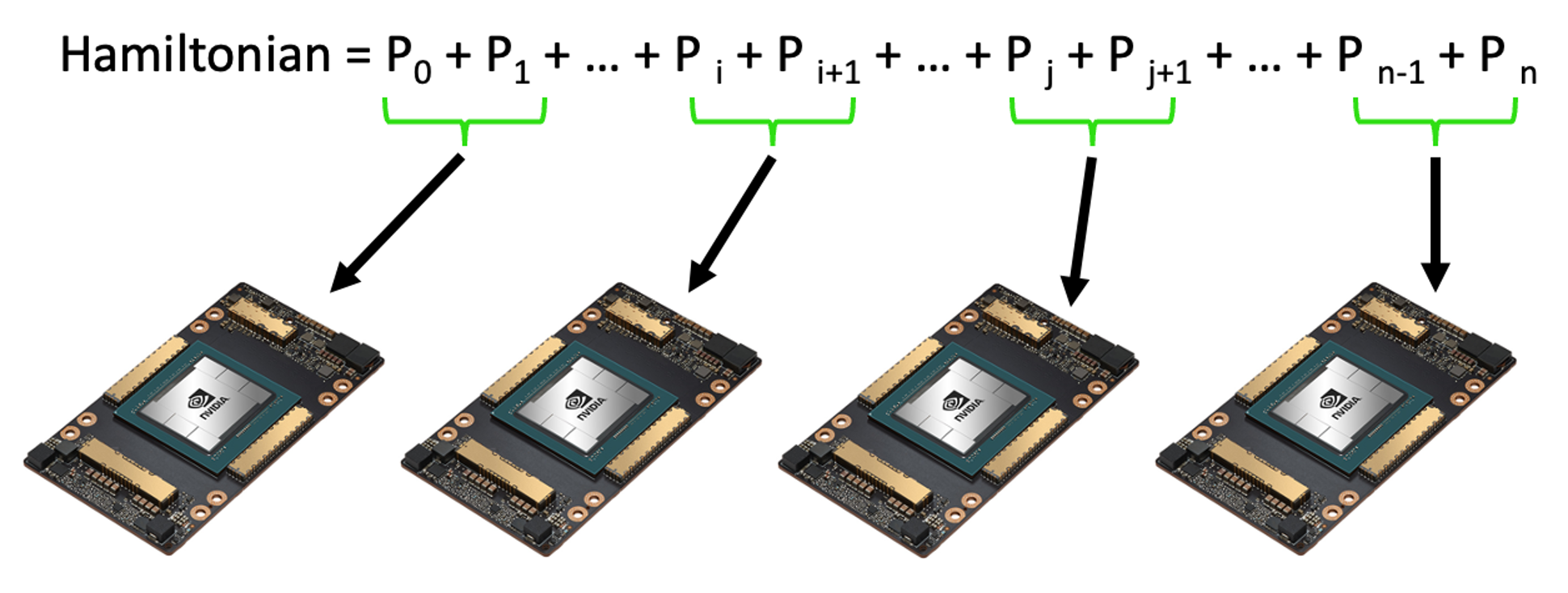
The nvidia-mqpuoption of the nvidia target along with the execution=cudaq.parallel.thread option in the observe call handles the distribution of the expectation value computations of a multi-term Hamiltonian across multiple virtual QPUs for you. Refer to the example below to see how this is carried out:
In the above code snippet, since the Hamiltonian contains four non-identity terms, there are four quantum circuits that need to be executed. When the nvidia-mqpu platform is selected, these circuits will be distributed across all available QPUs. The final expectation value result is computed from all QPU execution results.
An alternative method for orchestrating Hamiltonian batching is to use the MPI context and multiple GPUs. You can read more about this here.
Circuit cutting
Circuit cutting is a widely used technique for parallelization. One way to conceptualize circuit cutting is through the Max Cut problem. In this scenario, we aim to approximate the Max Cut of a graph using a divide-and-conquer strategy, also known as QAOA-in-QAOA or QAOA². This approach breaks the graph into smaller subgraphs and solves the Max Cut for each subgraph in parallel using QAOA (see references such as arXiv:2205.11762v1, arxiv.2101.07813v1, arxiv:2304.03037v1, arxiv:2009.06726, and arxiv:2406:17383). By doing so, we effectively decompose the QAOA circuit for the larger graph into smaller QAOA circuits for the subgraphs.
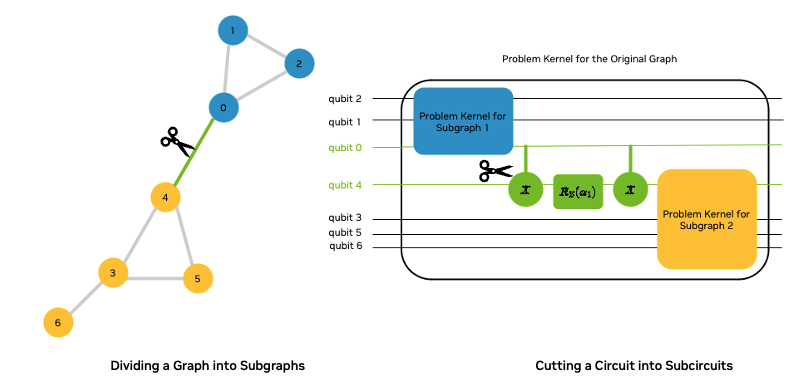
To complete the circuit cutting, we'll need to merge the results of QAOA on the subgraphs into a result for the entire graph. This requires solving another smaller optimization problem, which can also be tackled with QAOA. You can read about that in more detail in a series of interactive labs.
This example illustrates how to use the MPI context to orchestrate running @cudaq.kernel decorated functions in parallel. Additionally, a few exercises are built into this longer example to provide some practice with the CUDA-Q commands introduced earlier in this notebook. Solutions to these exercises appear in the solutions-sc24.ipynb file, but we encourage you to first attempt the exercises out yourself.
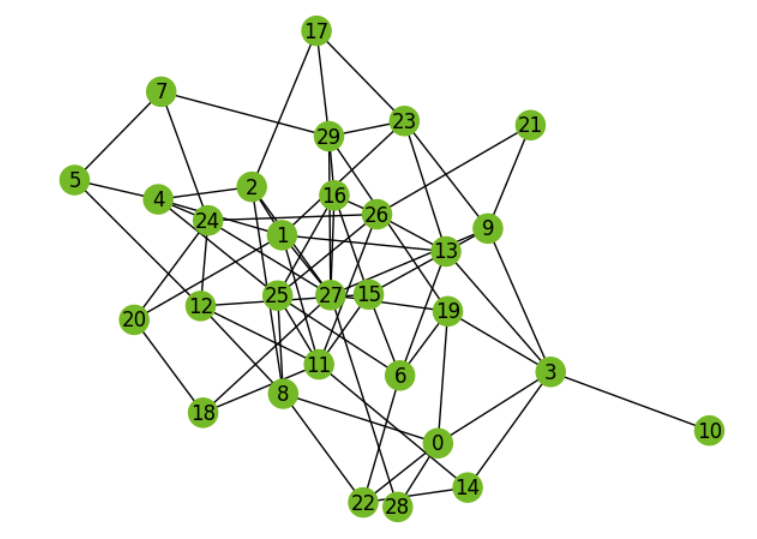
First we need to define a graph and subgraphs. Let's start with the graph drawn below.
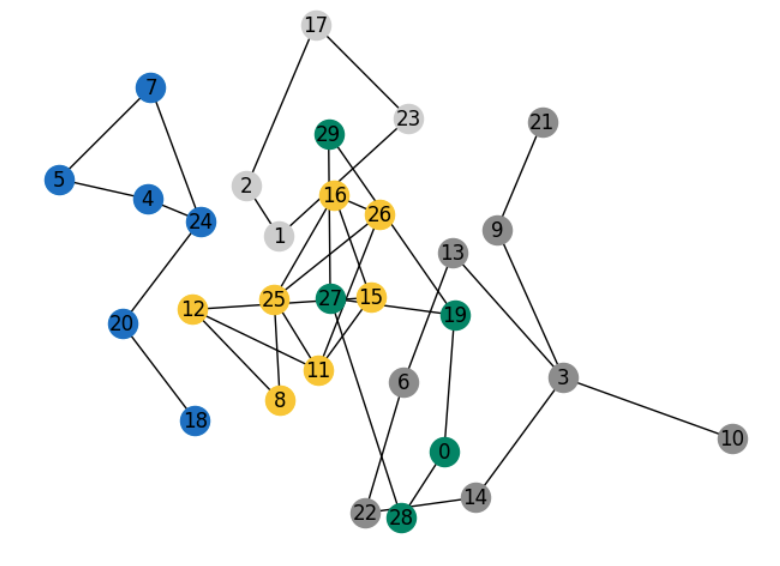
For this demonstration, we'll divide our example graph into the five subgraphs depicted below:
Execute the cell below to generate subgraphs for the divide-and-conquer QAOA.
Next, we need a helper function that will be used to map graph nodes to qubits.
Next let's create kernels to combine into the QAOA circuit:
qaoaProblemkernel adds the gate sequence depicted below for each edge in the graph
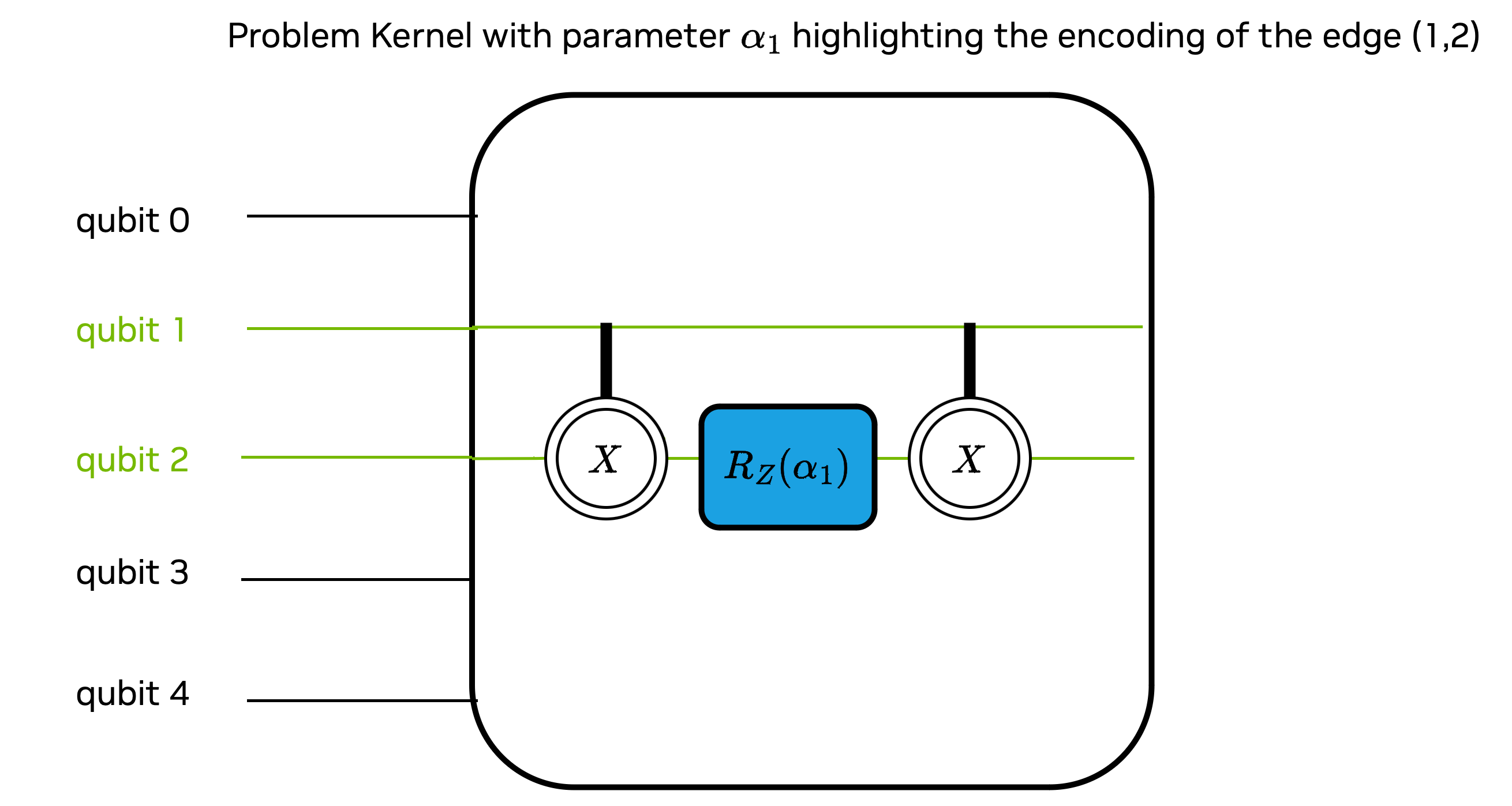
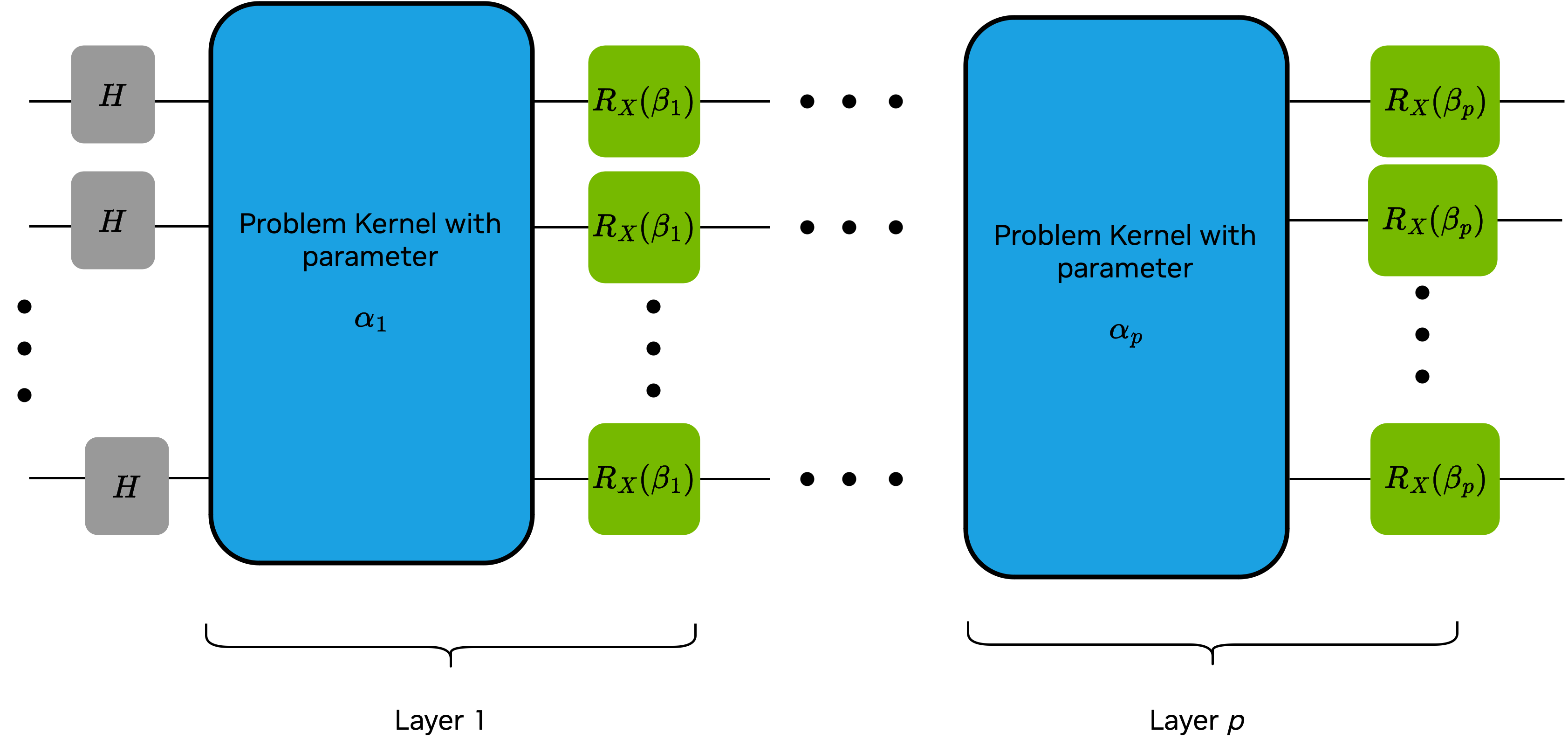
qaoaMixerapplies a parameterizedrxgate to all the qubits, highlighted in green in the diagram belowkernel_qaoabuilds the QAOA circuit drawn below using theqaoaProblemandqaoaMixer
Exercise 2: The kernel_qaoa kernel has been defined for you. Your task is edit the two ###FIX_ME###s in the code below to complete the qaoaProblem and qaoaMixer kernels.
We'll need a Hamiltonian to encode the cost function: where is the set of edges of the graph.
Now let's put this all together in a function that finds the the optimal parameters for QAOA of a given subgraph.
Before running this function in parallel, let's execute it sequentially.
Finally, we'll need to sample the kernel_qaoa circuit with the optimal parameters to find approximate max cut solutions to each of the subgraphs.
Exercise 3: Edit the FIX_ME in the code block below to sample the QAOA circuits for each of the subgraphs using the optimal parameter found above.
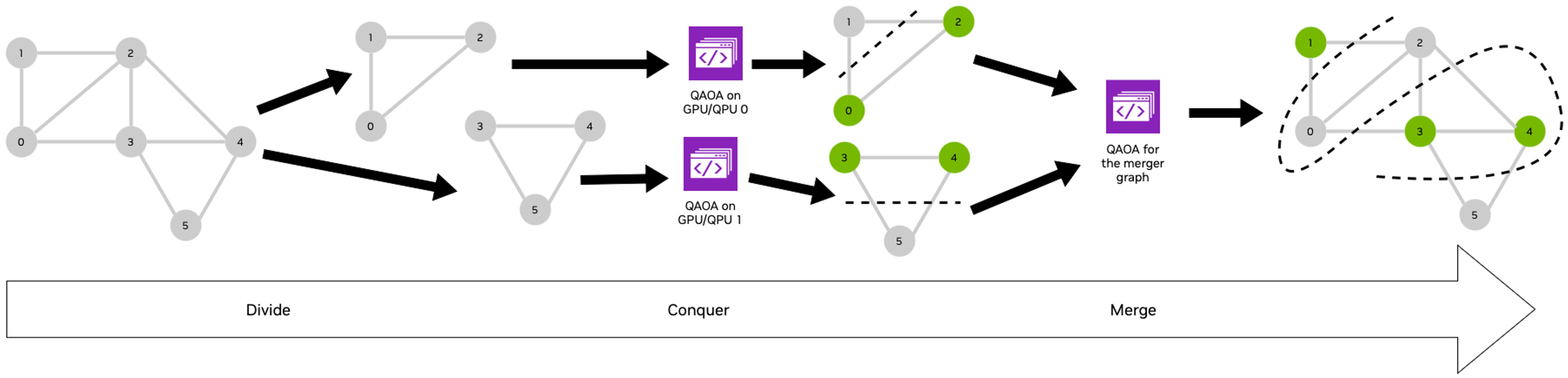
That completes the "conquer" stage of the divide-and-conquer algorithm. To learn more about how the results of the subgraph solutions are merged together to get a max cut approximation of the original graph, check out the 2nd notebook of this series of interactive tutorials. For the purposes of today's tutorial we'll set that step aside and examine how we could parallelize the divide-and-conquer QAOA algorithm using CUDA-Q and MPI.
The diagram below illustrates a strategy for implementing the divide-and-conquer QAOA across 4 processors (which could be distinct GPUs or separate processes on a single GPU). The approach involves storing subgraph data in a dictionary, where the keys represent subgraph names. These dictionary keys are distributed among the 4 processors, with each processor responsible for solving the QAOA problem for the subgraphs corresponding to its assigned keys.
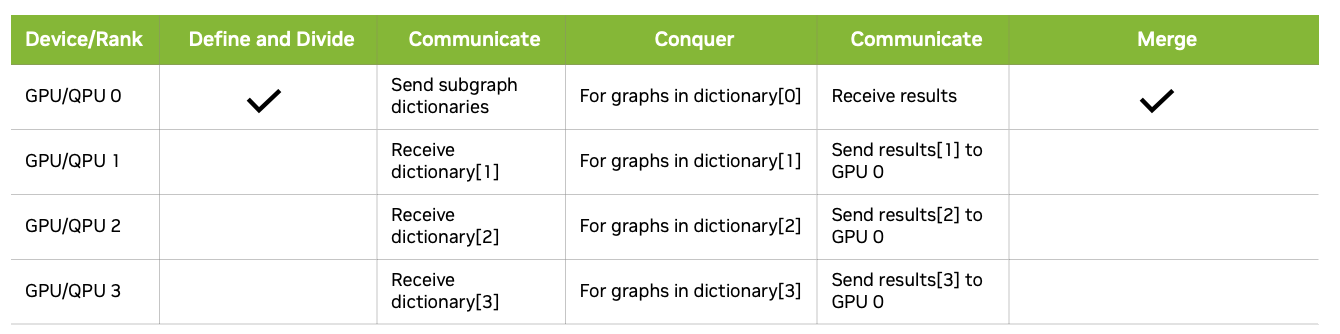
We've coded this strategy up in the one-step-qaoa.py file for you. The command line below executes the qaoa-divide-and-conquer.py file on 4 processors in parallel.
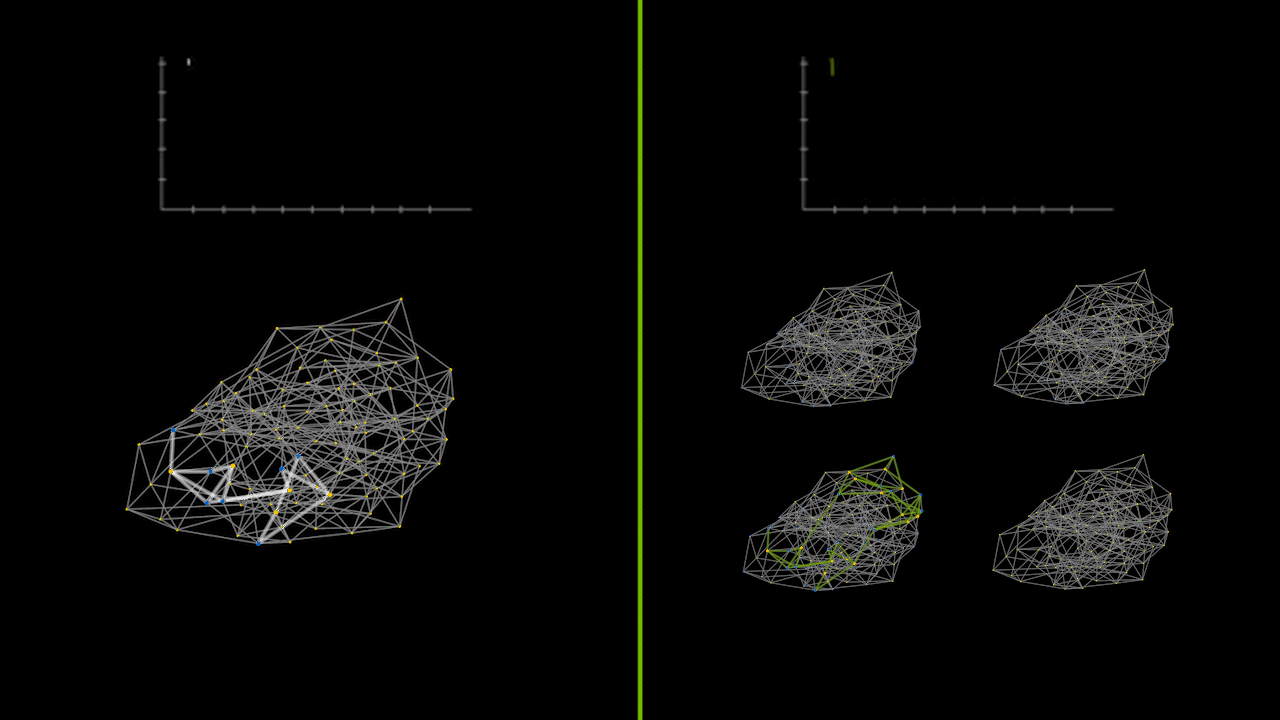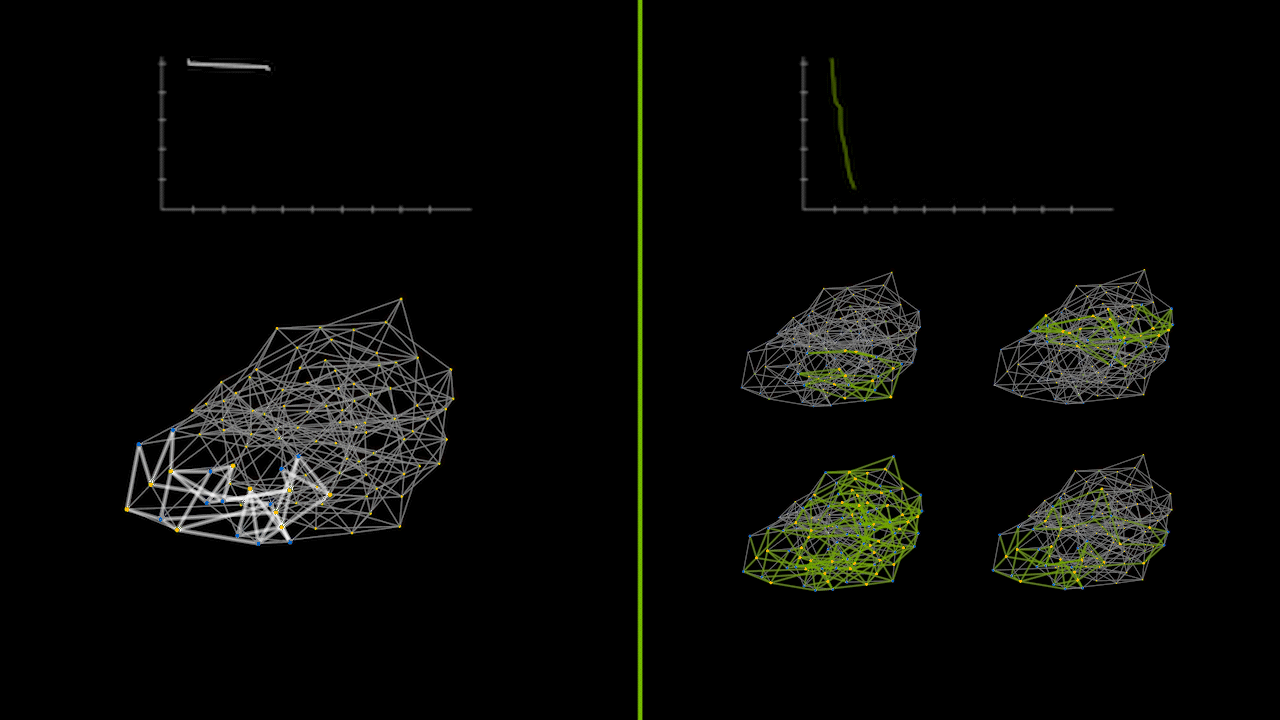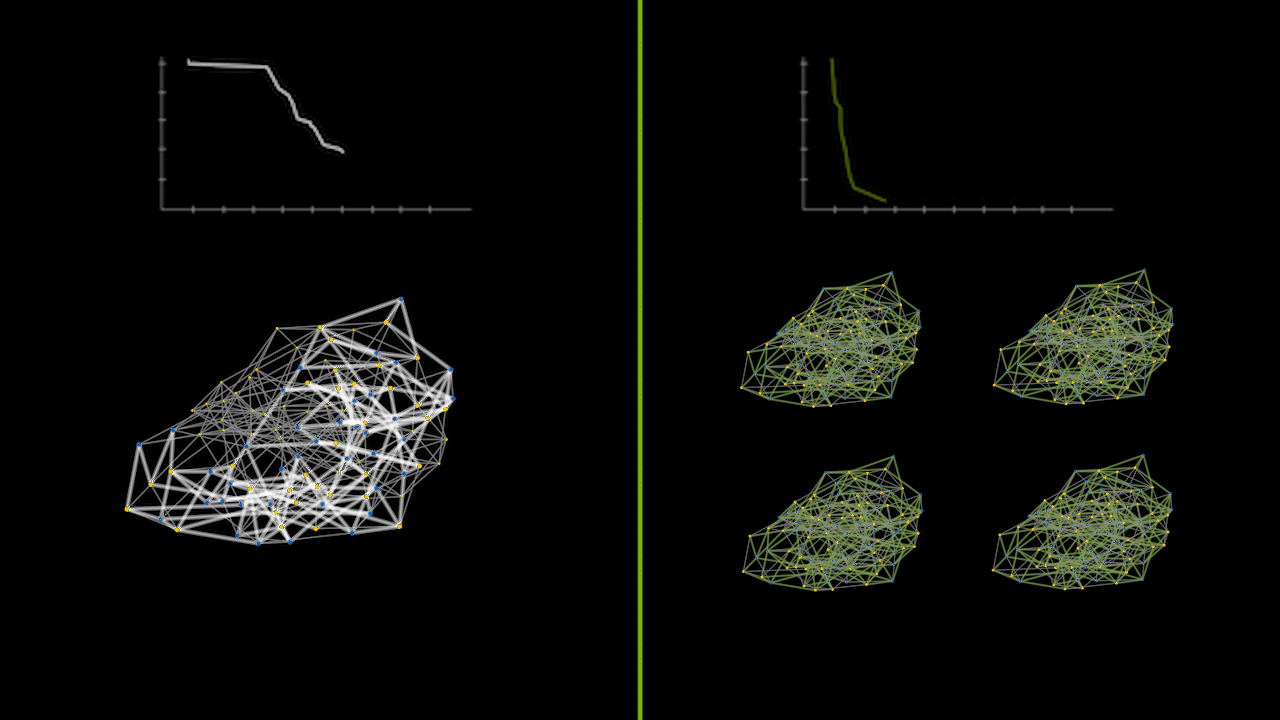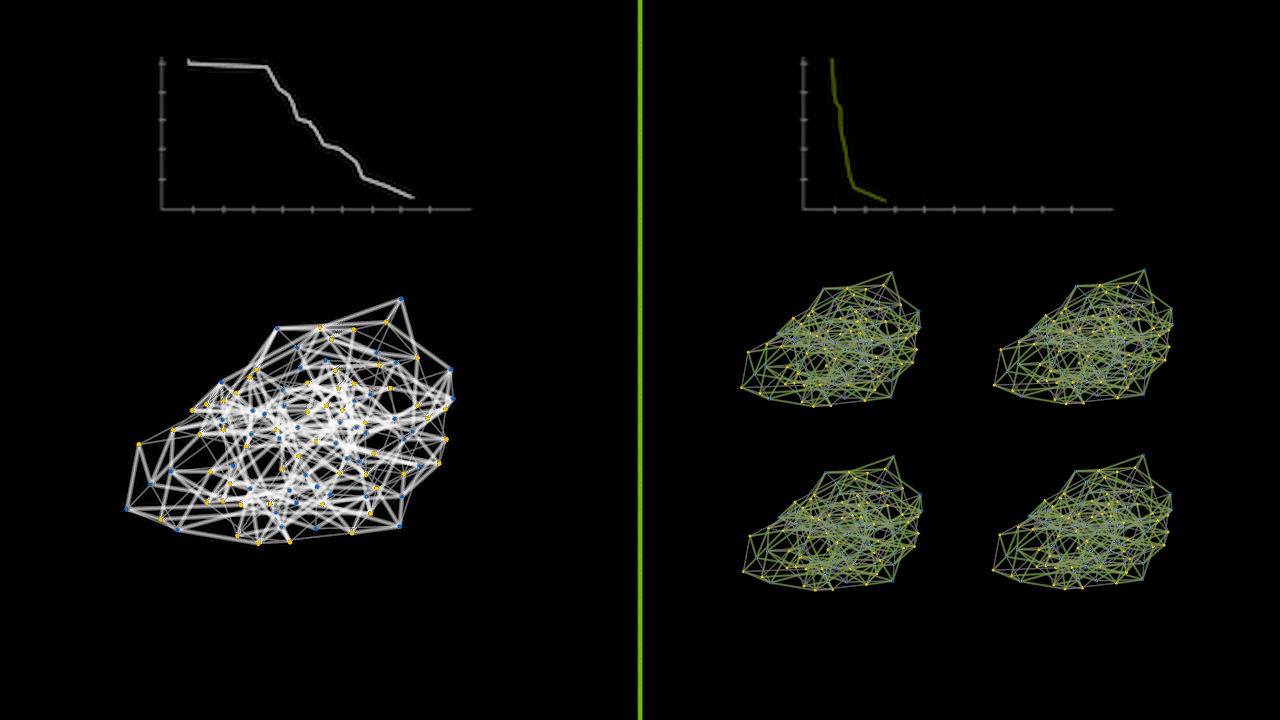
The animation below captures a small instance of a recursive divide-and-conquer QAOA running on a CPU versus a GPU in parallel. The lineplots on the top depict the error between the calculated max cut solution and the true max cut of the graph over time. The graphs on the bottom represent the max cut solutions as various subgraph problems are solved and merged together. The green graphs on the right show the parallelization of solving subgraph problems simultaneously.
Beyond Statevector Simulations
Other simulators
When using CUDA-Q on NVIDIA GPU with available CUDA runtime libraries, the default target is set to nvidia. This will utilize the cuQuantum single-GPU statevector simulator. On CPU-only systems, the default target is set to qpp-cpu which uses the OpenMP CPU-only statevector simulator.
For many applications, it's not necessary to simluate and access the entire statevector. The default simulator can be overridden by the environment variable CUDAQ_DEFAULT_SIMULATOR where tensor network, matrix product state simulators can be selected. Please refer to the table below for a list of backend simulator names along with its multi-GPU capability.
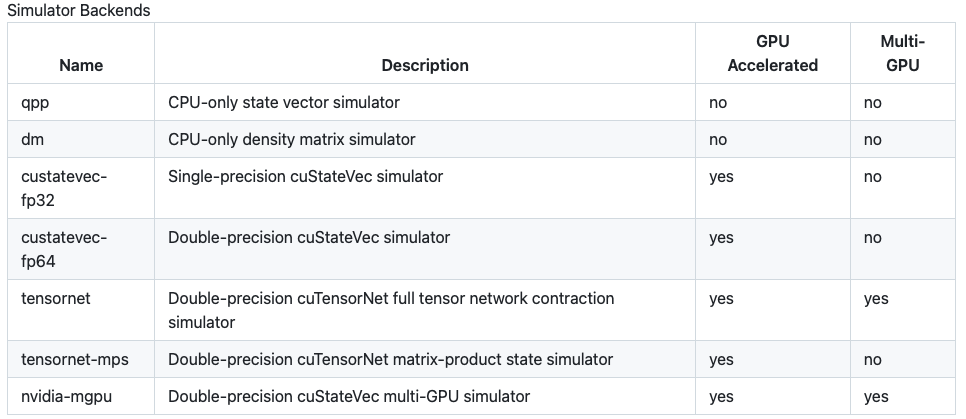
For more information about all the simulator backends available on this documentation page.
Quantum processing units
In addition to executing simulations, CUDA-Q is equipped to run quantum kernels on quantum processing units. For more information on how to execute CUDA-Q code on quantum processing units, check out the documentation.