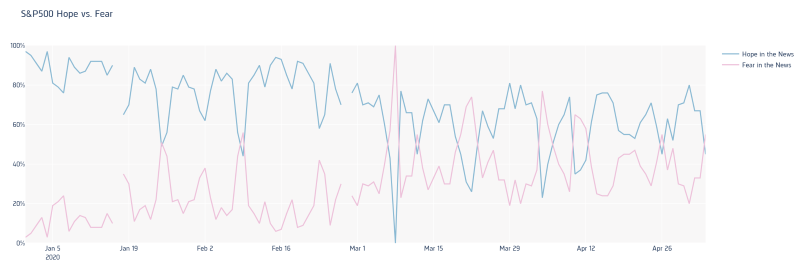
sp500 = ["MMM","ABT","ABBV","ABMD","ACN","ATVI","ADBE","AMD","AAP","AES","AFL","A","APD","AKAM","ALK","ALB","ARE","ALXN","ALGN","ALLE","AGN","ADS","LNT","ALL","GOOGL","GOOG","MO","AMZN","AMCR","AEE","AAL","AEP","AXP","AIG","AMT","AWK","AMP","ABC","AME","AMGN","APH","ADI","ANSS","ANTM","AON","AOS","APA","AIV","AAPL","AMAT","APTV","ADM","ANET","AJG","AIZ","T","ATO","ADSK","ADP","AZO","AVB","AVY","BKR","BLL","BAC","BK","BAX","BDX","BRK.B","BBY","BIIB","BLK","BA","BKNG","BWA","BXP","BSX","BMY","AVGO","BR","BF.B","CHRW","COG","CDNS","CPB","COF","CPRI","CAH","KMX","CCL","CARR","CAT","CBOE","CBRE","CDW","CE","CNC","CNP","CTL","CERN","CF","SCHW","CHTR","CVX","CMG","CB","CHD","CI","CINF","CTAS","CSCO","C","CFG","CTXS","CLX","CME","CMS","KO","CTSH","CL","CMCSA","CMA","CAG","CXO","COP","ED","STZ","COO","CPRT","GLW","CTVA","COST","COTY","CCI","CSX","CMI","CVS","DHI","DHR","DRI","DVA","DE","DAL","XRAY","DVN","FANG","DLR","DFS","DISCA","DISCK","DISH","DG","DLTR","D","DOV","DOW","DTE","DUK","DRE","DD","DXC","ETFC","EMN","ETN","EBAY","ECL","EIX","EW","EA","EMR","ETR","EOG","EFX","EQIX","EQR","ESS","EL","EVRG","ES","RE","EXC","EXPE","EXPD","EXR","XOM","FFIV","FB","FAST","FRT","FDX","FIS","FITB","FE","FRC","FISV","FLT","FLIR","FLS","FMC","F","FTNT","FTV","FBHS","FOXA","FOX","BEN","FCX","GPS","GRMN","IT","GD","GE","GIS","GM","GPC","GILD","GL","GPN","GS","GWW","HRB","HAL","HBI","HOG","HIG","HAS","HCA","PEAK","HP","HSIC","HSY","HES","HPE","HLT","HFC","HOLX","HD","HON","HRL","HST","HWM","HPQ","HUM","HBAN","HII","IEX","IDXX","INFO","ITW","ILMN","INCY","IR","INTC","ICE","IBM","IP","IPG","IFF","INTU","ISRG","IVZ","IPGP","IQV","IRM","JKHY","J","JBHT","SJM","JNJ","JCI","JPM","JNPR","KSU","K","KEY","KEYS","KMB","KIM","KMI","KLAC","KSS","KHC","KR","LB","LHX","LH","LRCX","LW","LVS","LEG","LDOS","LEN","LLY","LNC","LIN","LYV","LKQ","LMT","L","LOW","LYB","MTB","MRO","MPC","MKTX","MAR","MMC","MLM","MAS","MA","MKC","MXIM","MCD","MCK","MDT","MRK","MET","MTD","MGM","MCHP","MU","MSFT","MAA","MHK","TAP","MDLZ","MNST","MCO","MS","MOS","MSI","MSCI","MYL","NDAQ","NOV","NTAP","NFLX","NWL","NEM","NWSA","NWS","NEE","NLSN","NKE","NI","NBL","JWN","NSC","NTRS","NOC","NLOK","NCLH","NRG","NUE","NVDA","NVR","ORLY","OXY","ODFL","OMC","OKE","ORCL","OTIS","PCAR","PKG","PH","PAYX","PAYC","PYPL","PNR","PBCT","PEP","PKI","PRGO","PFE","PM","PSX","PNW","PXD","PNC","PPG","PPL","PFG","PG","PGR","PLD","PRU","PEG","PSA","PHM","PVH","QRVO","PWR","QCOM","DGX","RL","RJF","RTX","O","REG","REGN","RF","RSG","RMD","RHI","ROK","ROL","ROP","ROST","RCL","SPGI","CRM","SBAC","SLB","STX","SEE","SRE","NOW","SHW","SPG","SWKS","SLG","SNA","SO","LUV","SWK","SBUX","STT","STE","SYK","SIVB","SYF","SNPS","SYY","TMUS","TROW","TTWO","TPR","TGT","TEL","FTI","TFX","TXN","TXT","TMO","TIF","TJX","TSCO","TT","TDG","TRV","TFC","TWTR","TSN","UDR","ULTA","USB","UAA","UA","UNP","UAL","UNH","UPS","URI","UHS","UNM","VFC","VLO","VAR","VTR","VRSN","VRSK","VZ","VRTX","VIAC","V","VNO","VMC","WRB","WAB","WMT","WBA","DIS","WM","WAT","WEC","WFC","WELL","WDC","WU","WRK","WY","WHR","WMB","WLTW","WYNN","XEL","XRX","XLNX","XYL","YUM","ZBRA","ZBH","ZION","ZTS"]