
Path: blob/master/2019-fall/slides/07_classification_continued.ipynb
2707 views
DSCI 100 - Introduction to Data Science
Lecture 7 - Classification II: Evaluating & Tuning
Housekeeping
Thanks for filling out the mid-course survey! We're collecting and processing responses.
Grades are posted for Tutorial 04, Quiz 1, and Worksheet 06
Continuing with the classification problem
Recall: cancer tumour cell data, with "benign" and "malignant" labels
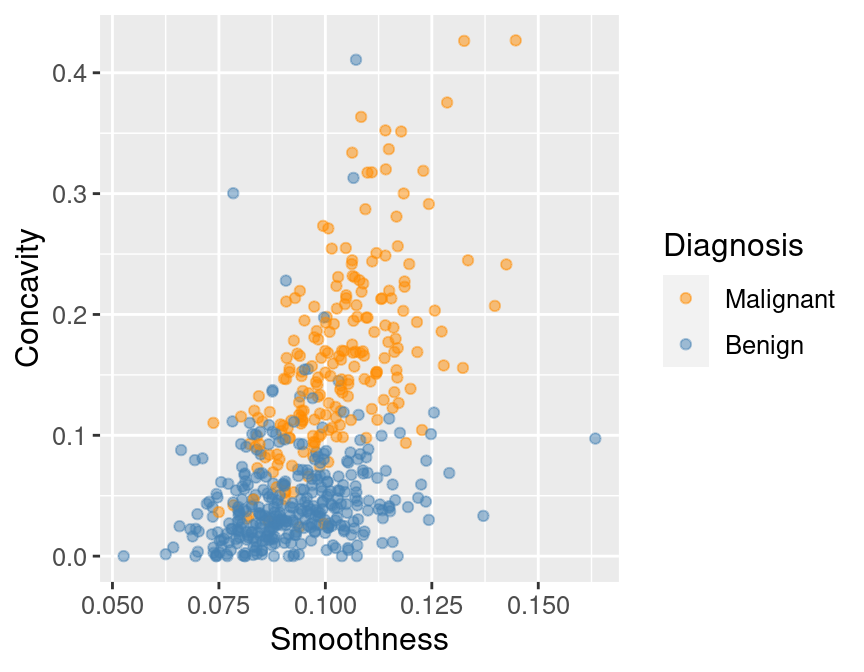
Today: unanswered questions from last week
Is our model any good? How do we evaluate it?
How do we choose
kin K-nearest neighbours classification?
Evaluating the Model
To add evaluation into our classification pipeline, we:
Split our data into two subsets: training data and testing data.

Evaluating the Model
Build the model & choose K using training data only
Compute accuracy by predicting labels on testing data only

Why?
Showing your classifier the labels of evaluation data is like cheating on a test; it'll look more accurate than it really is
Golden Rule of Machine Learning / Statistics: Don't use your testing data to train your model!

Splitting Data
There are two important things to do when splitting data.
Shuffling: randomly reorder the data before splitting
Stratification: make sure the two split subsets of data have roughly equal proportions of the different labels
Why? Discuss in your groups for 1 minute!
(caret thankfully automatically does both of these things)
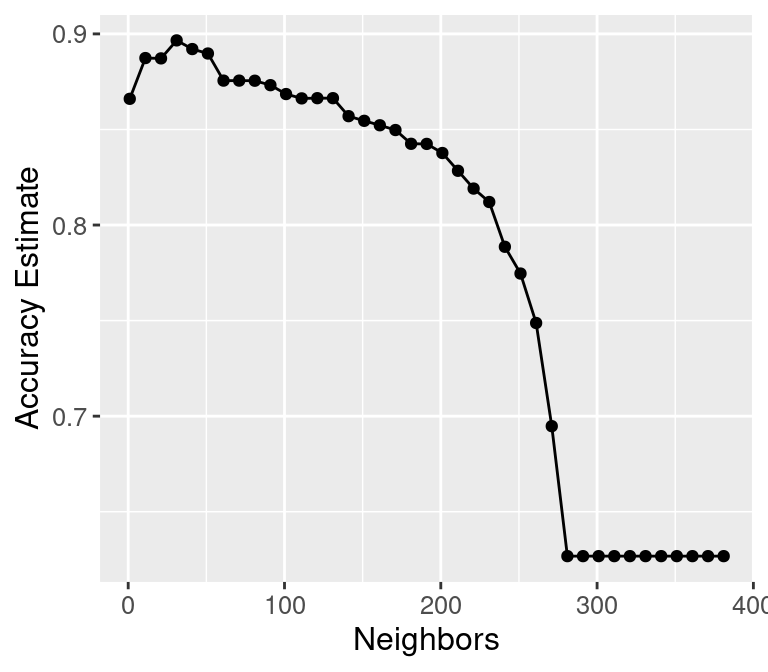
Choosing K (or, "tuning'' the model)
Want to choose K to maximize accuracy, but:
we can't use training data to evaluate accuracy (cheating!)
we can't use test data to evaluate accuracy (choosing K is part of training!)
Solution: Split the training data further into training data and validation data
2a. Choose some candidate values of K
2b. Train the model for each using training data only
2c. Evaluate accuracy for each using validation data only
2d. Pick the K that maximizes validation accuracy
Cross-Validation
We can get a better estimate of accuracy by splitting multiple ways and averaging

Underfitting & Overfitting
Overfitting: when your model is too sensitive to your training data; noise can influence predictions!
Underfitting: when your model isn't sensitive enough to training data; useful information is ignored!
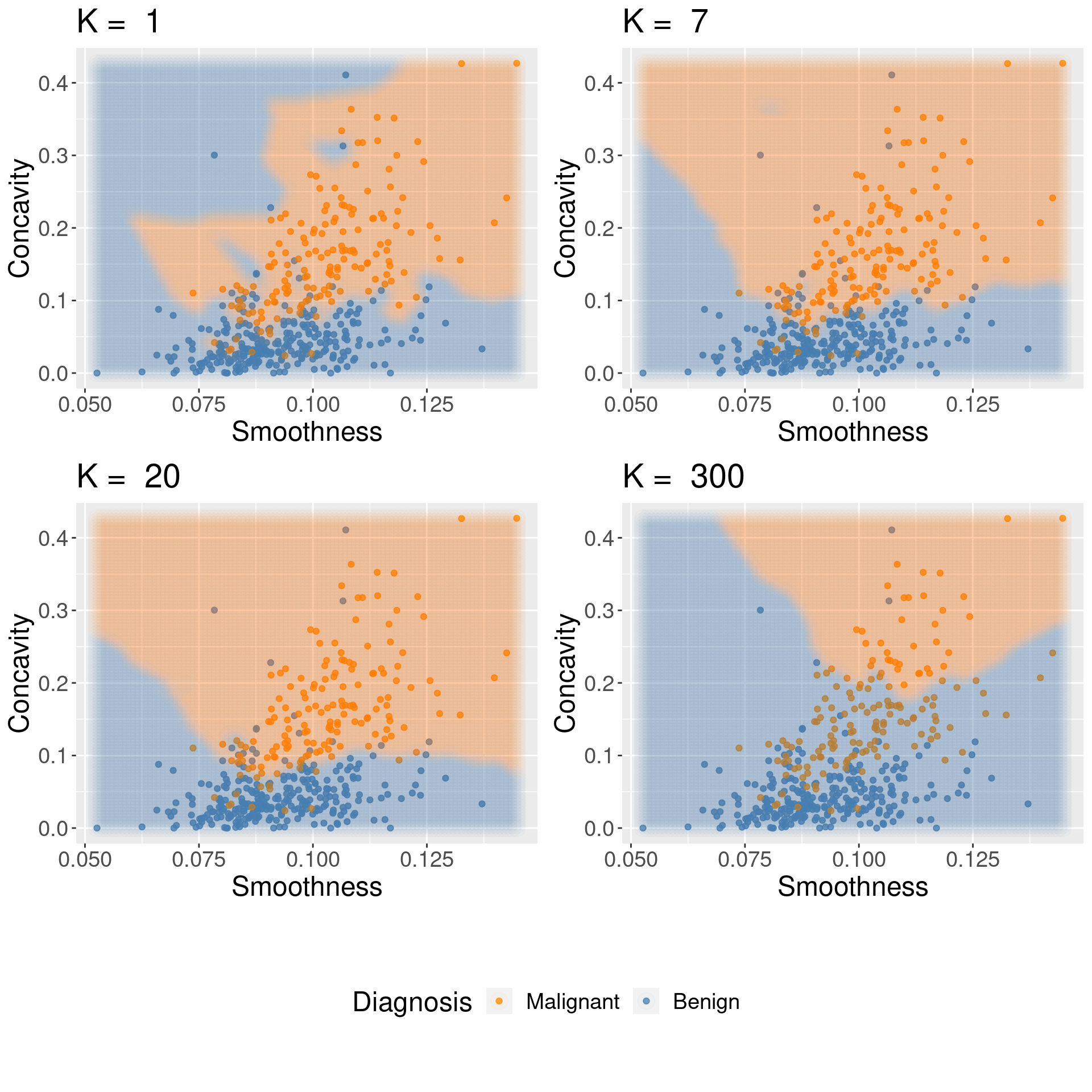
Which of these are under-, over-, and good fits? Discuss in your groups for 1 minute!
Underfitting & Overfitting
For KNN: small K overfits, large K underfits, both cause poor accuracy
The Big Picture

Worksheet Time!
...and if we've learned anything from last time,

Class Activity
In your group, discuss the following prompts. Post your group's answer on Piazza:
Explain what a test, validation and training data set are in your own words
Explain cross-validation in your own words
Imagine if we train and evaluate accuracy on all the data. How can I get 100% accuracy, always?
Why can't I use cross validation when testing?