
Path: blob/master/2019-fall/slides/08_regression1.ipynb
2707 views
DSCI 100 - Introduction to Data Science
Lecture 8 - Introduction to regression with k-nearest neighbours
2019-02-28
We're in the modelling part of the course
... and I hope you feel like this!

... not like this!

Reminder of where we are...
Follow the syllabus: https://github.com/UBC-DSCI/dsci-100#schedule
Quiz 2 on Tuesday, Nov 12
practice quiz is available on Canvas: https://canvas.ubc.ca/courses/40616/quizzes/126616
I have (and will continue to) post the solutions to the past worksheets and tutorials to help you study
like last time, follow the learning objectives when you study!
Project proposals are due on Saturday, November 9th at 6pm
The lecture before that (Thursday, November 7) will be a dedicated group project working session
Regression prediction problem
What if we want to predict a quantitative value instead of a class label?
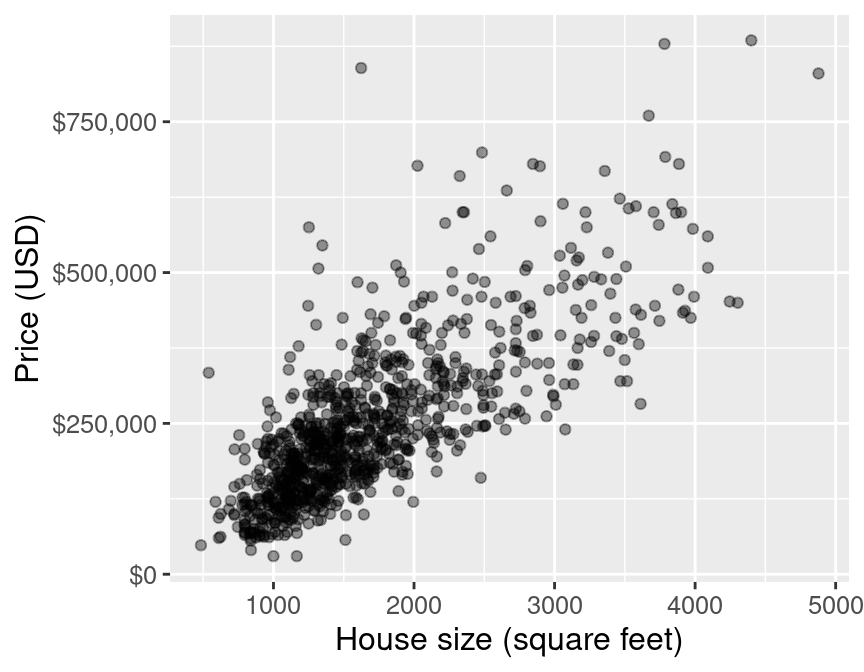
For example, the price of a 2000 square foot home (from this reduced data set):
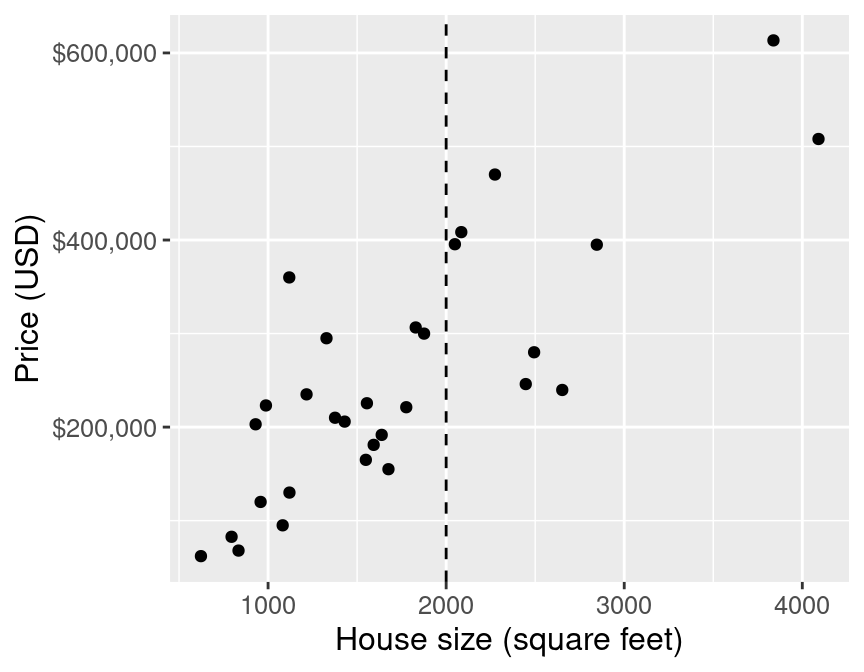
k-nn for regression
As in k-nn classification, we find the -nearest neighbours (here 5)
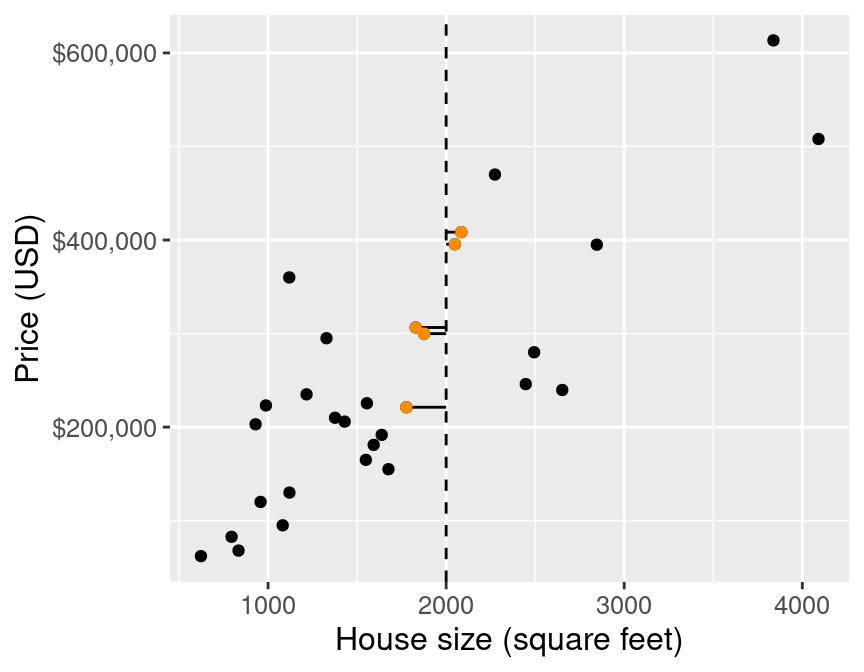
k-nn for regression
Then we average the values for the -nearest neighbours, and use that as the prediction:
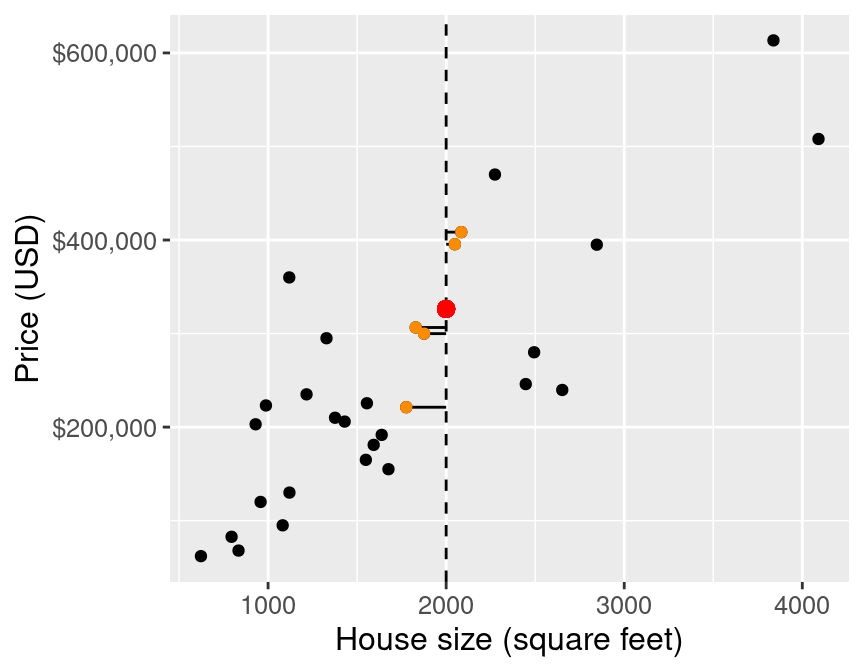
Regression prediction problem
We still have to answer these two questions:
Is our model any good?
How do we choose
k?
1. Is our model any good?
Same general strategy

But a different calculation to assess our model
The mathematical formula for calculation RMSPE is shown below:
Where:
is the number of observations
is the observed value for the observation
is the forcasted/predicted value for the observation
So if we had this predicted blue line from doing k-nn regression:

The red lines are in:

RMSPE
Not out of 1, but instead in units of the target/response variable
so, a bit harder to interpret in the context of test error
RMSE vs RMSPE
The error output we have been getting from
caretto assess how well our k-nn regression models predict is labelled asRMSE, standing for root mean squared error.
Why? What's the difference?
In statistics we try to be very precise with our language to indicate whether we are calculating the error on predicting on the training or testing data
When predicting on training data (in sample) we say RMSE. This indicates how well the model fits the data used to create it.
When predicting on validation or testing data (out of sample) we say RMSPE. This indicates how well the model does at predicting unseen data.
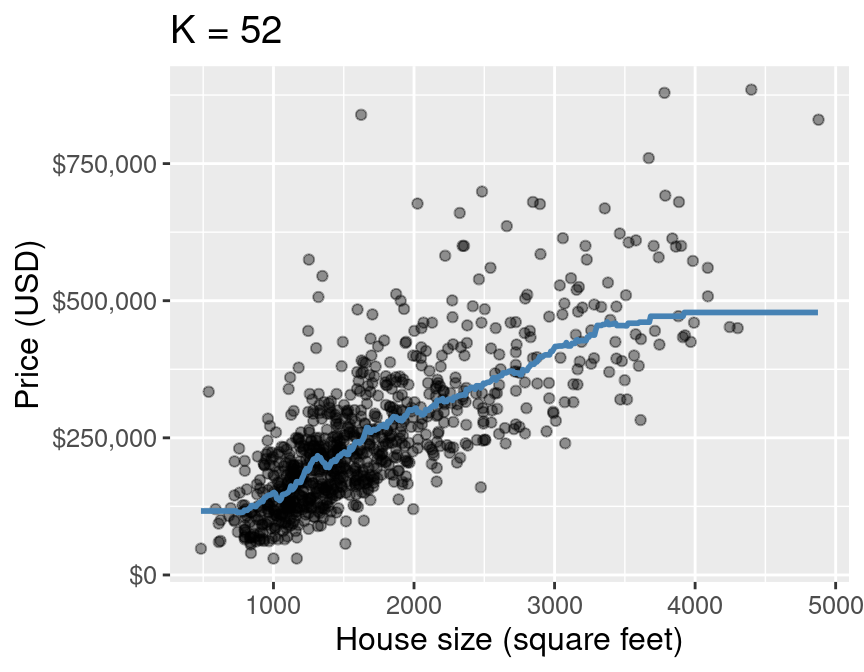
Final model from k-nn regression
For this model, RMSPE is 90112.40, how can we interpret this?
2. How do we choose k?
cross-validation
choose the model with the smallest RMSPE
How does affect k-nn regression?
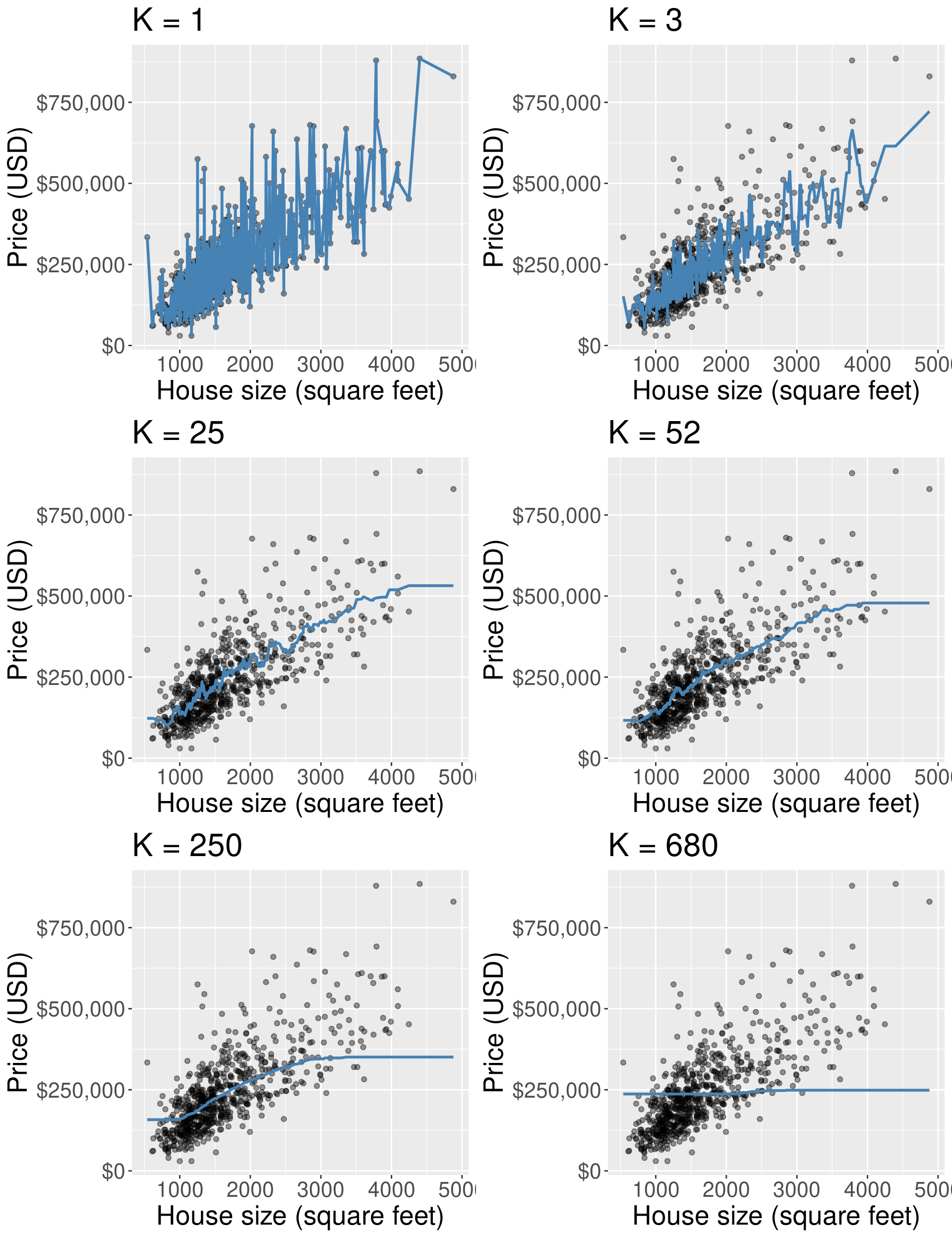
What did we learn?
Formula for RMSPE
How to do a regression
How to find optimal for knn-regression