
Path: blob/master/2019-fall/slides/09_regression2.ipynb
2707 views
DSCI 100 - Introduction to Data Science
Lecture 9 - Introduction to linear regression
First, Happy Halloween!

Upcoming in-class schedule:
Tues, Nov 5: regular tutorial session (working on Jupyter notebook homework)
Thurs, Nov 7: group project work session, attendance expected by all (not a normal lecture)
Tues, Nov 12: Quiz 2 (followed by time to work on your group project afterwards)
Upcoming due dates schedule:
Sat, Nov 2: worksheet_09 due
Wed, Nov 6: tutorial_09 due
Sat, Nov 9: group project proposal due
Details described in Canvas
Project clarification notes:
File format to be submitted should be .pdf or .html
Your exploratory data analysis should only be done on your training data
Hence, for your proposal, you will have to split your data into a training and test data set
We have not learned more advanced methods for selecting predictors for a model (this is beyond the scope of this course). Thus for this project, use domain expertise and exploratory data analysis to choose reasonable predictors.
Examples of classification questions:
What political party will someone vote for in the next US election?
Is a new patient diseased or healthy?
Is a new email spam or not?
Will a new, potential customer buy your product?
Review: Regression prediction problem
What if we want to predict a quantitative value instead of a class label?
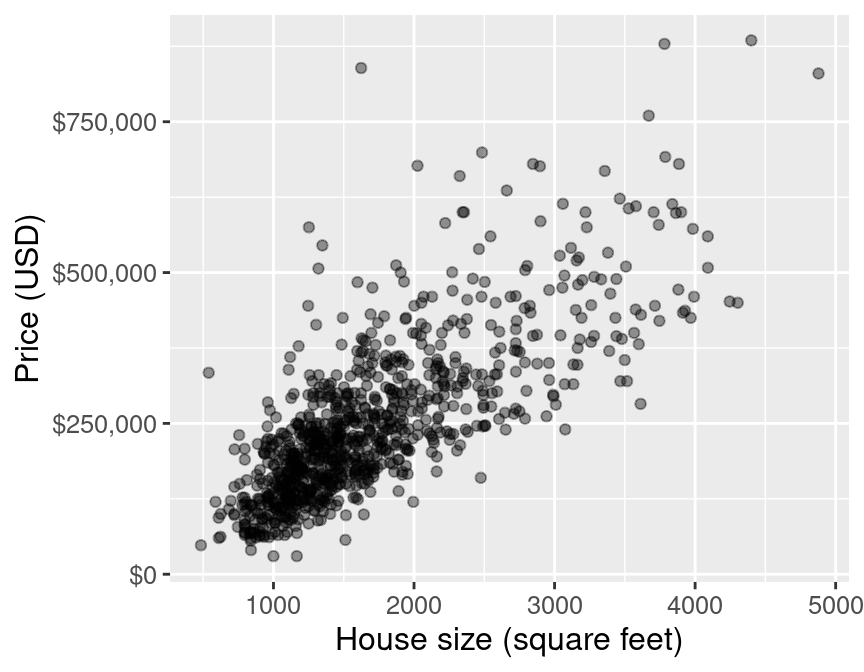
Today we will focus on another regression approach - linear regression.
For example, the price of a 2000 square foot home (from this reduced data set):
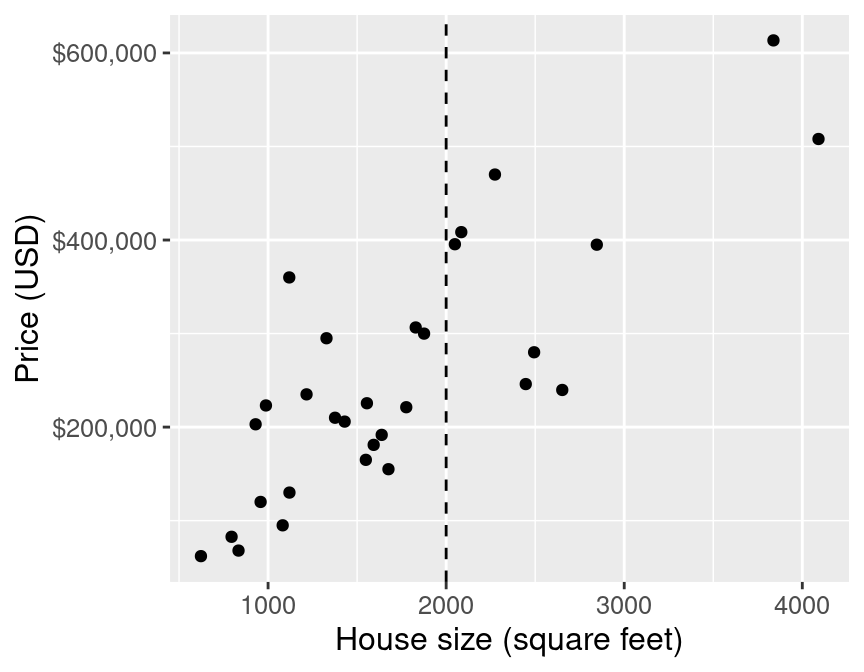
simple linear regression
First we find the line of "best-fit" through the data points:
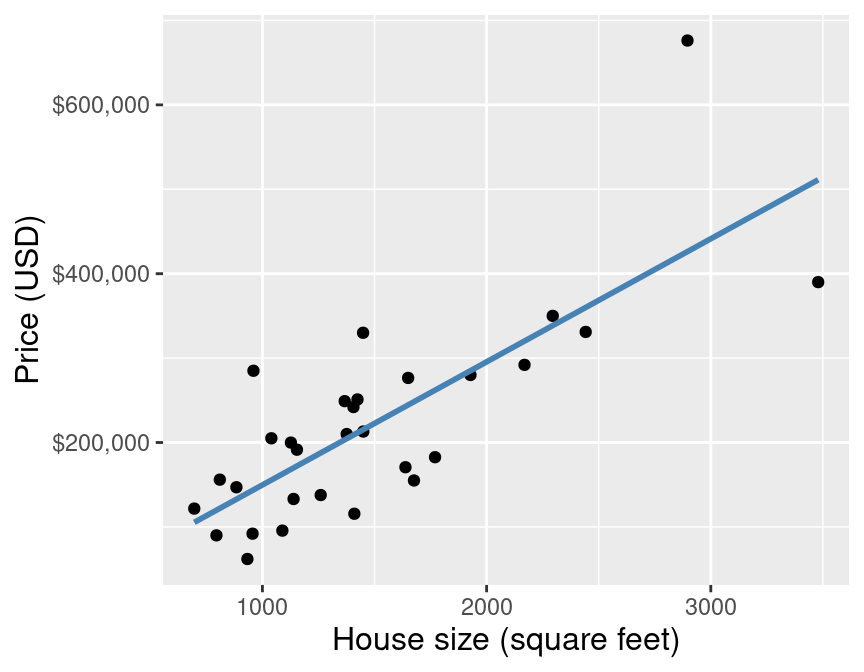
simple linear regression
And then we "look up" the value we want to predict of off of the line.
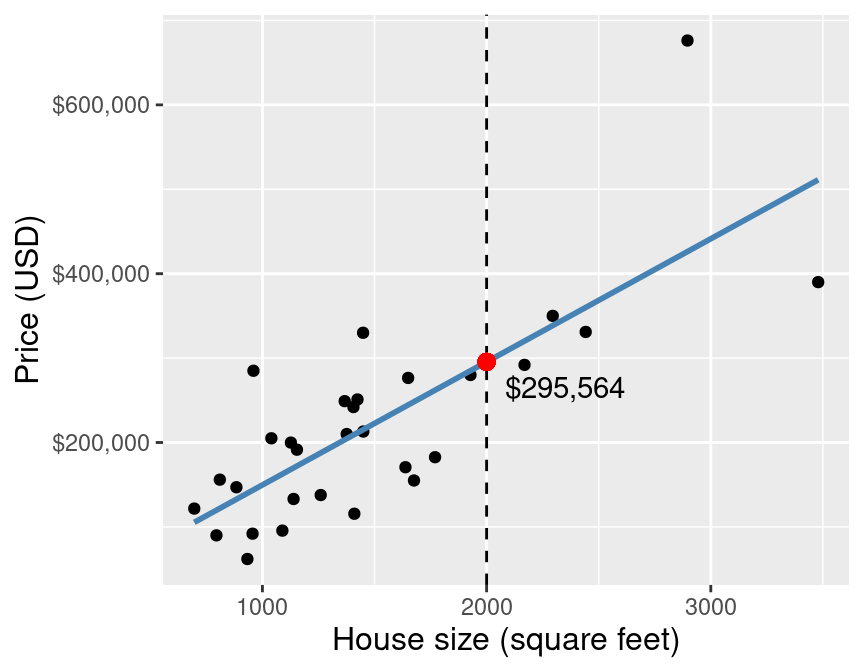
simple linear regression
How do we choose the line of "best fit"? We can draw many lines through the data:
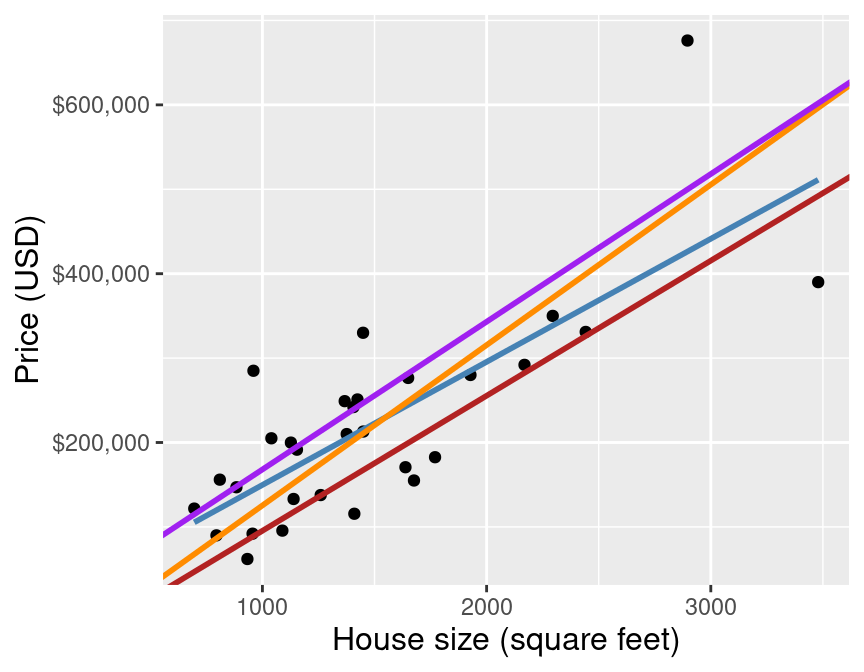
simple linear regression
We choose the line that minimzes the average vertical distance between itself and each of the observed data points
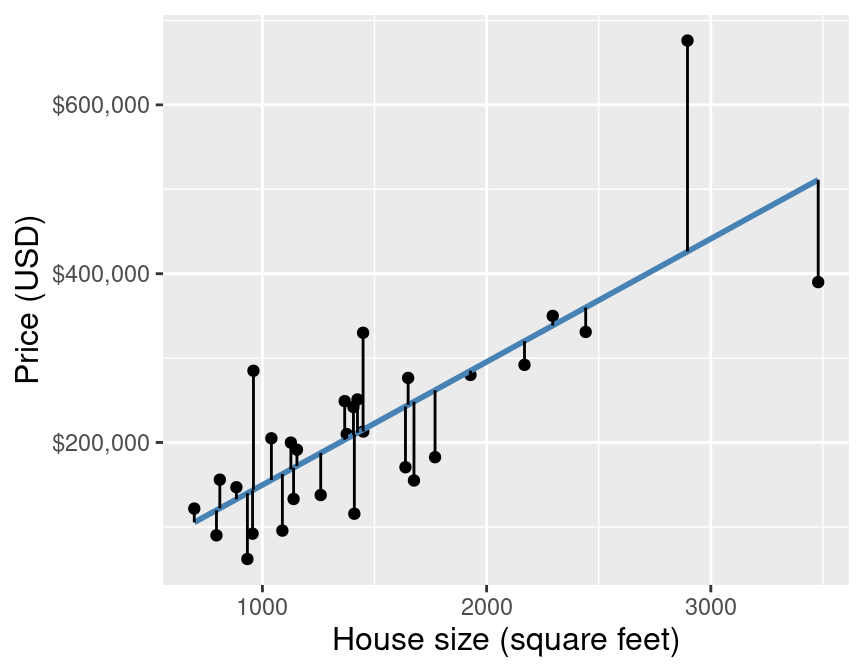
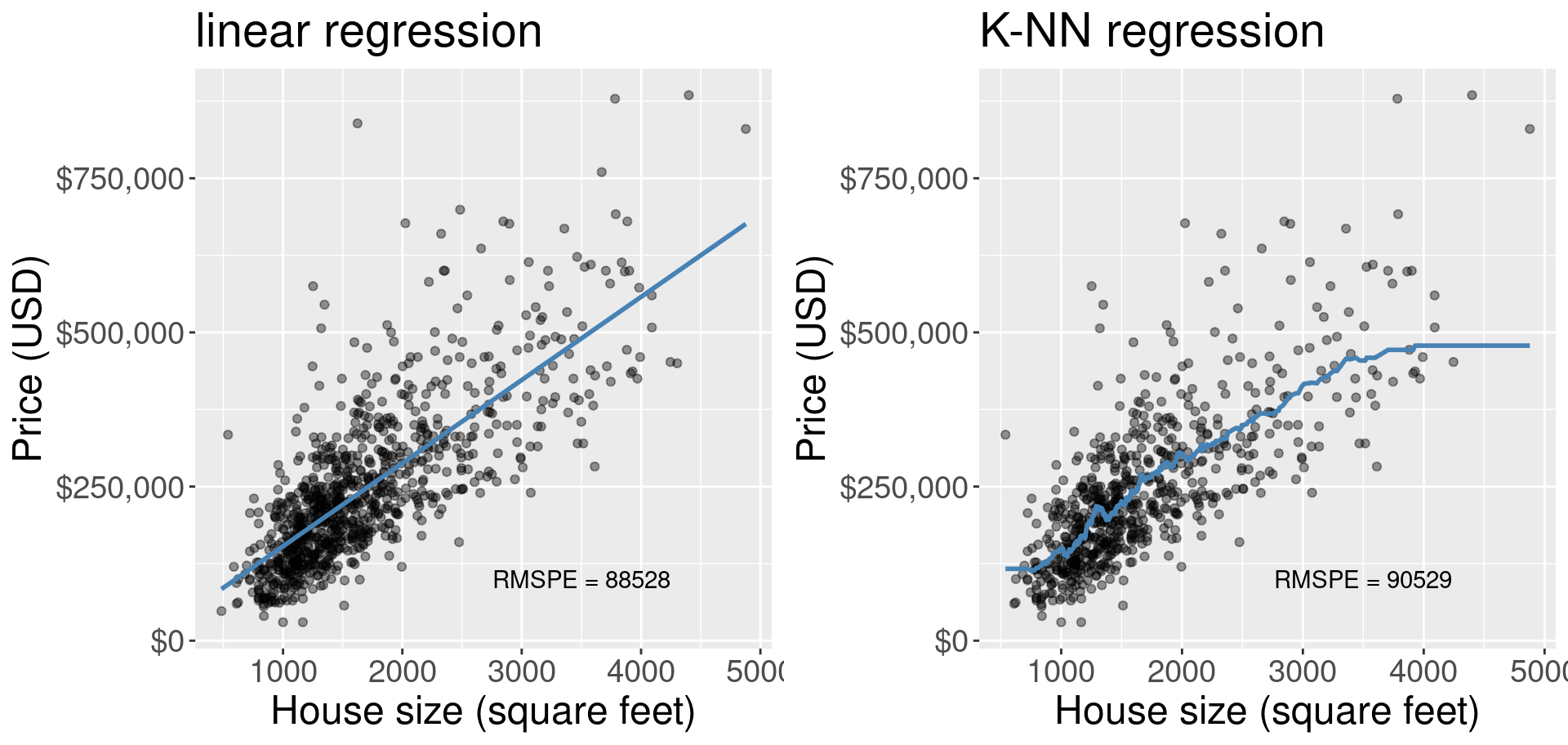
Simple linear regression vs k-nn regression
Why simple linear regression?
Advantages to restricting the model to straight line: interpretability!
Remembering that the equation for a straight line is:
Where:
is the y-intercept of the line (the value where the line cuts the y-axis)
is the slope of the line

We can then write:
And finally, fill in the values for and :
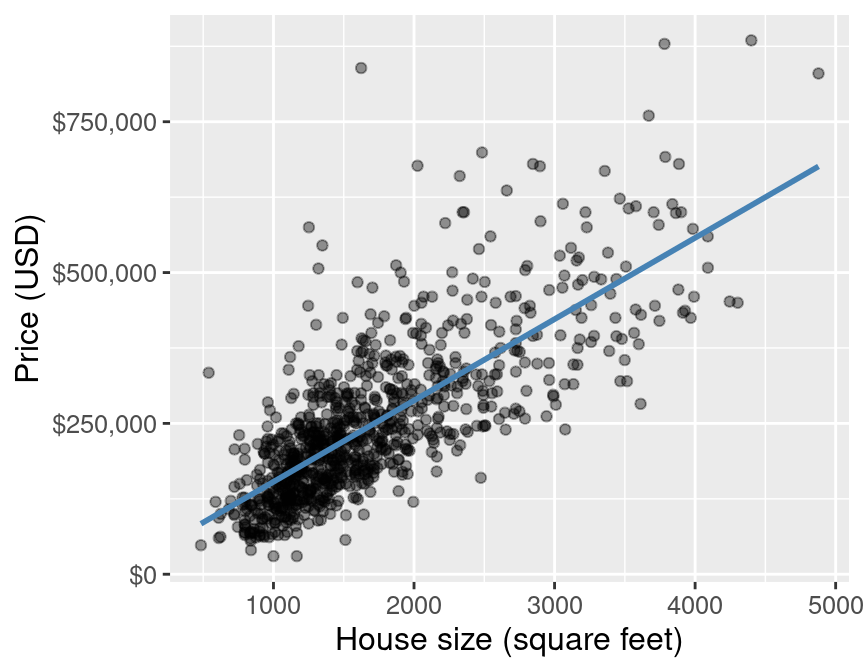
k-nn regression, as simple as it is to implement and understand, has no such interpretability from it's wiggly line.
Multivariate regression
Similar to classification, we can do prediction with regression with > 1 predictor. We can do this via k-nn or via linear regression.
But wait? How do we fit a line with two predictors?
We don't we fit a hyperplane!
View examples from the textbook:
Why not linear regression (sometimes?)
Models are not like kitten hugs

They are more like suits:
ONE SIZE DOES NOT FIT ALL!

── Attaching packages ─────────────────────────────────────── tidyverse 1.2.1 ──
✔ ggplot2 3.2.0 ✔ purrr 0.3.2
✔ tibble 2.1.3 ✔ dplyr 0.8.3
✔ tidyr 0.8.3 ✔ stringr 1.4.0
✔ readr 1.3.1 ✔ forcats 0.4.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
Be cautious with linear regression with data like this:

and this:

Class activity 1:
Which of the following problems could be solved using a regression approach?
A) We are interested in predicting CEO salary for new CEO's. We collect a set of data on a number of firms and record profit, number of employees, industry and CEO salary.
B) Whether a new patient will have a heart attack in the next 5 years based on answers to a survey about their physical health and attributes.
C) A car dealership is interested in predicting its net sales based on money spent on Google and Facebook adds.
D) The resting heart rate of a new patient based on answers to a survey about their physical health and attributes.
What did we learn
Linear regression, and how we fit the line of best fit
In multivariate regression, we don't fit a line, but a hyperplane
The difference between knn and linear regression:
interprebility of linear regression
flexibility of knn regression