
Path: blob/master/lab1/PT_Part2_Music_Generation.ipynb
907 views
 Visit MIT Deep Learning
Visit MIT Deep Learning Run in Google Colab
Run in Google Colab View Source on GitHub
View Source on GitHubCopyright Information
Lab 1: Intro to PyTorch and Music Generation with RNNs
Part 2: Music Generation with RNNs
In this portion of the lab, we will explore building a Recurrent Neural Network (RNN) for music generation using PyTorch. We will train a model to learn the patterns in raw sheet music in ABC notation and then use this model to generate new music.
2.1 Dependencies
First, let's download the course repository, install dependencies, and import the relevant packages we'll need for this lab.
We will be using Comet ML to track our model development and training runs. First, sign up for a Comet account at this link (you can use your Google or Github account). You will need to generate a new personal API Key, which you can find either in the first 'Get Started with Comet' page, under your account settings, or by pressing the '?' in the top right corner and then 'Quickstart Guide'. Enter this API key as the global variable COMET_API_KEY.
2.2 Dataset

We've gathered a dataset of thousands of Irish folk songs, represented in the ABC notation. Let's download the dataset and inspect it:
We can easily convert a song in ABC notation to an audio waveform and play it back. Be patient for this conversion to run, it can take some time.
One important thing to think about is that this notation of music does not simply contain information on the notes being played, but additionally there is meta information such as the song title, key, and tempo. How does the number of different characters that are present in the text file impact the complexity of the learning problem? This will become important soon, when we generate a numerical representation for the text data.
2.3 Process the dataset for the learning task
Let's take a step back and consider our prediction task. We're trying to train an RNN model to learn patterns in ABC music, and then use this model to generate (i.e., predict) a new piece of music based on this learned information.
Breaking this down, what we're really asking the model is: given a character, or a sequence of characters, what is the most probable next character? We'll train the model to perform this task.
To achieve this, we will input a sequence of characters to the model, and train the model to predict the output, that is, the following character at each time step. RNNs maintain an internal state that depends on previously seen elements, so information about all characters seen up until a given moment will be taken into account in generating the prediction.
Vectorize the text
Before we begin training our RNN model, we'll need to create a numerical representation of our text-based dataset. To do this, we'll generate two lookup tables: one that maps characters to numbers, and a second that maps numbers back to characters. Recall that we just identified the unique characters present in the text.
This gives us an integer representation for each character. Observe that the unique characters (i.e., our vocabulary) in the text are mapped as indices from 0 to len(unique). Let's take a peek at this numerical representation of our dataset:
We can also look at how the first part of the text is mapped to an integer representation:
Create training examples and targets
Our next step is to actually divide the text into example sequences that we'll use during training. Each input sequence that we feed into our RNN will contain seq_length characters from the text. We'll also need to define a target sequence for each input sequence, which will be used in training the RNN to predict the next character. For each input, the corresponding target will contain the same length of text, except shifted one character to the right.
To do this, we'll break the text into chunks of seq_length+1. Suppose seq_length is 4 and our text is "Hello". Then, our input sequence is "Hell" and the target sequence is "ello".
The batch method will then let us convert this stream of character indices to sequences of the desired size.
For each of these vectors, each index is processed at a single time step. So, for the input at time step 0, the model receives the index for the first character in the sequence, and tries to predict the index of the next character. At the next timestep, it does the same thing, but the RNN considers the information from the previous step, i.e., its updated state, in addition to the current input.
We can make this concrete by taking a look at how this works over the first several characters in our text:
2.4 The Recurrent Neural Network (RNN) model
Now we're ready to define and train an RNN model on our ABC music dataset, and then use that trained model to generate a new song. We'll train our RNN using batches of song snippets from our dataset, which we generated in the previous section.
The model is based off the LSTM architecture, where we use a state vector to maintain information about the temporal relationships between consecutive characters. The final output of the LSTM is then fed into a fully connected linear nn.Linear layer where we'll output a softmax over each character in the vocabulary, and then sample from this distribution to predict the next character.
As we introduced in the first portion of this lab, we'll be using PyTorch's nn.Module to define the model. Three components are used to define the model:
nn.Embedding: This is the input layer, consisting of a trainable lookup table that maps the numbers of each character to a vector withembedding_dimdimensions.nn.LSTM: Our LSTM network, with sizehidden_size.nn.Linear: The output layer, withvocab_sizeoutputs.
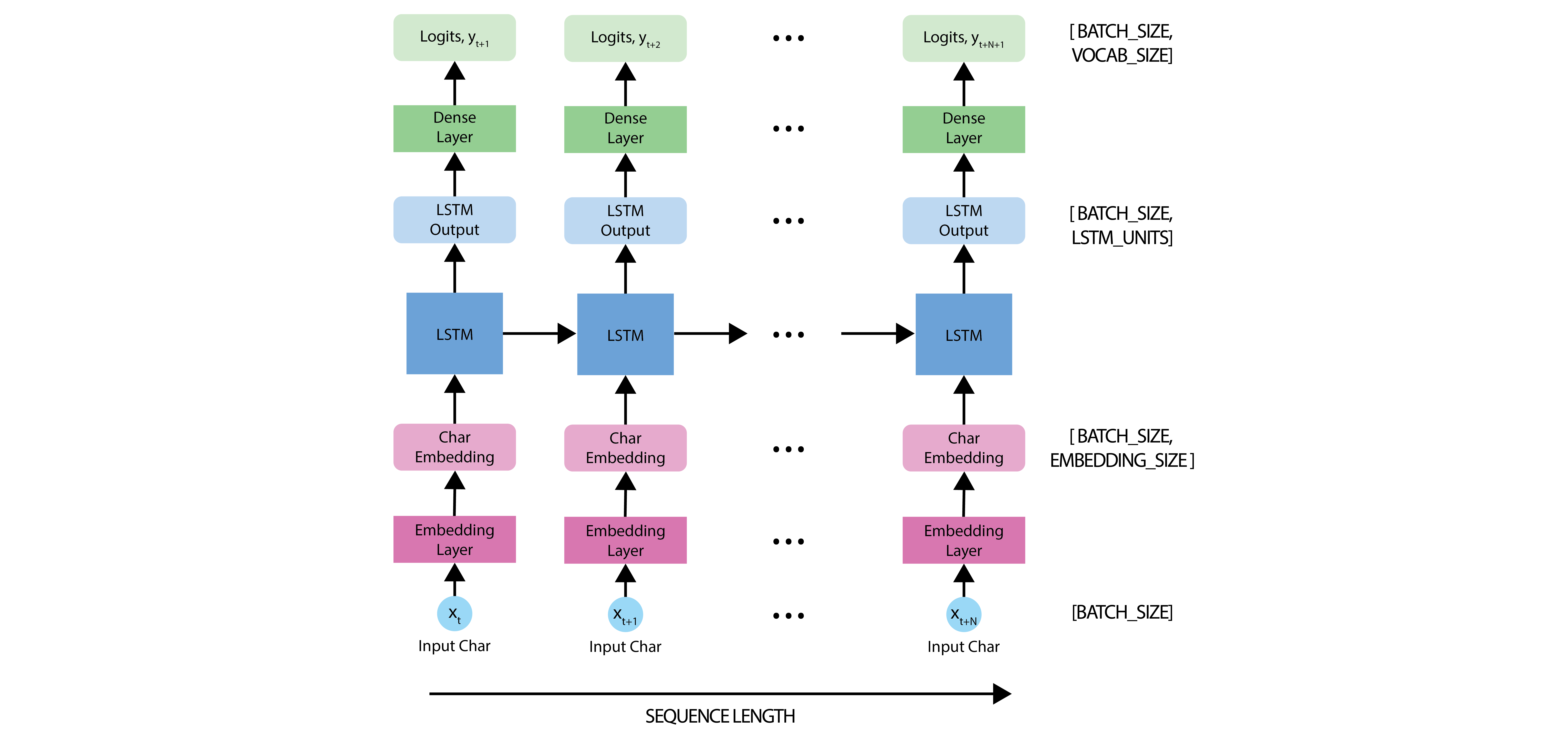
Define the RNN model
Let's define our model as an nn.Module. Fill in the TODOs to define the RNN model.
The time has come! Let's instantiate the model!
Test out the RNN model
It's always a good idea to run a few simple checks on our model to see that it behaves as expected.
We can quickly check the layers in the model, the shape of the output of each of the layers, the batch size, and the dimensionality of the output. Note that the model can be run on inputs of any length.
Predictions from the untrained model
Let's take a look at what our untrained model is predicting.
To get actual predictions from the model, we sample from the output distribution, which is defined by a torch.softmax over our character vocabulary. This will give us actual character indices. This means we are using a categorical distribution to sample over the example prediction. This gives a prediction of the next character (specifically its index) at each timestep. torch.multinomial samples over a categorical distribution to generate predictions.
Note here that we sample from this probability distribution, as opposed to simply taking the argmax, which can cause the model to get stuck in a repetitive loop.
Let's try this sampling out for the first example in the batch.
We can now decode these to see the text predicted by the untrained model:
As you can see, the text predicted by the untrained model is pretty nonsensical! How can we do better? Well, we can train the network!
2.5 Training the model: loss and training operations
Now it's time to train the model!
At this point, we can think of our next character prediction problem as a standard classification problem. Given the previous state of the RNN, as well as the input at a given time step, we want to predict the class of the next character -- that is, to actually predict the next character.
To train our model on this classification task, we can use a form of the crossentropy loss (i.e., negative log likelihood loss). Specifically, we will use PyTorch's CrossEntropyLoss, as it combines the application of a log-softmax (LogSoftmax) and negative log-likelihood (NLLLoss in a single class and accepts integer targets for categorical classification tasks. We will want to compute the loss using the true targets -- the labels -- and the predicted targets -- the logits.
Let's define a function to compute the loss, and then use that function to compute the loss using our example predictions from the untrained model.
Let's start by defining some hyperparameters for training the model. To start, we have provided some reasonable values for some of the parameters. It is up to you to use what we've learned in class to help optimize the parameter selection here!
Having defined our hyperparameters we can set up for experiment tracking with Comet. Experiment are the core objects in Comet and will allow us to track training and model development. Here we have written a short function to create a new Comet experiment. Note that in this setup, when hyperparameters change, you can run the create_experiment() function to initiate a new experiment. All experiments defined with the same project_name will live under that project in your Comet interface.
Now, we are ready to define our training operation -- the optimizer and duration of training -- and use this function to train the model. You will experiment with the choice of optimizer and the duration for which you train your models, and see how these changes affect the network's output. Some optimizers you may like to try are Adam and Adagrad.
First, we will instantiate a new model and an optimizer, and ready them for training. Then, we will use loss.backward(), enabled by PyTorch's autograd method, to perform the backpropagation. Finally, to update the model's parameters based on the computed gradients, we will utake a step with the optimizer, using optimizer.step().
We will also generate a print-out of the model's progress through training, which will help us easily visualize whether or not we are minimizing the loss.
2.6 Generate music using the RNN model
Now, we can use our trained RNN model to generate some music! When generating music, we'll have to feed the model some sort of seed to get it started (because it can't predict anything without something to start with!).
Once we have a generated seed, we can then iteratively predict each successive character (remember, we are using the ABC representation for our music) using our trained RNN. More specifically, recall that our RNN outputs a softmax over possible successive characters. For inference, we iteratively sample from these distributions, and then use our samples to encode a generated song in the ABC format.
Then, all we have to do is write it to a file and listen!
The prediction procedure
Now, we're ready to write the code to generate text in the ABC music format:
Initialize a "seed" start string and the RNN state, and set the number of characters we want to generate.
Use the start string and the RNN state to obtain the probability distribution over the next predicted character.
Sample from multinomial distribution to calculate the index of the predicted character. This predicted character is then used as the next input to the model.
At each time step, the updated RNN state is fed back into the model, so that it now has more context in making the next prediction. After predicting the next character, the updated RNN states are again fed back into the model, which is how it learns sequence dependencies in the data, as it gets more information from the previous predictions.
Complete and experiment with this code block (as well as some of the aspects of network definition and training!), and see how the model performs. How do songs generated after training with a small number of epochs compare to those generated after a longer duration of training?
Play back the generated music!
We can now call a function to convert the ABC format text to an audio file, and then play that back to check out our generated music! Try training longer if the resulting song is not long enough, or re-generating the song!
We will save the song to Comet -- you will be able to find your songs under the Audio and Assets & Artifacts pages in your Comet interface for the project. Note the log_asset() documentation, where you will see how to specify file names and other parameters for saving your assets.
2.7 Experiment and get awarded for the best songs!
Congrats on making your first sequence model in TensorFlow! It's a pretty big accomplishment, and hopefully you have some sweet tunes to show for it.
Consider how you may improve your model and what seems to be most important in terms of performance. Here are some ideas to get you started:
How does the number of training epochs affect the performance?
What if you alter or augment the dataset?
Does the choice of start string significantly affect the result?
Try to optimize your model and submit your best song! Participants will be eligible for prizes during the January 2026 offering. To enter the competition, you must upload the following to this submission link:
a recording of your song;
iPython notebook with the code you used to generate the song;
a description and/or diagram of the architecture and hyperparameters you used -- if there are any additional or interesting modifications you made to the template code, please include these in your description.
Name your file in the following format: [FirstName]_[LastName]_RNNMusic, followed by the file format (.zip, .mp4, .ipynb, .pdf, etc). ZIP files of all three components are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature.
You can also tweet us at @MITDeepLearning a copy of the song (but this will not enter you into the competition)! See this example song generated by a previous student (credit Ana Heart): song from May 20, 2020.
Have fun and happy listening!