
 Visit MIT Deep Learning
Visit MIT Deep Learning Run in Google Colab
Run in Google Colab View Source on GitHub
View Source on GitHubCopyright Information
Lab 1: Intro to TensorFlow and Music Generation with RNNs
In this lab, you'll get exposure to using TensorFlow and learn how it can be used for solving deep learning tasks. Go through the code and run each cell. Along the way, you'll encounter several TODO blocks -- follow the instructions to fill them out before running those cells and continuing.
Part 1: Intro to TensorFlow
0.1 Install TensorFlow
TensorFlow is a software library extensively used in machine learning. Here we'll learn how computations are represented and how to define a simple neural network in TensorFlow. For all the TensorFlow labs in Introduction to Deep Learning 2026, we'll be using TensorFlow 2, which affords great flexibility and the ability to imperatively execute operations, just like in Python. You'll notice that TensorFlow 2 is quite similar to Python in its syntax and imperative execution. Let's install TensorFlow and a couple of dependencies.
1.1 Why is TensorFlow called TensorFlow?
TensorFlow is called 'TensorFlow' because it handles the flow (node/mathematical operation) of Tensors, which are data structures that you can think of as multi-dimensional arrays. Tensors are represented as n-dimensional arrays of base dataypes such as a string or integer -- they provide a way to generalize vectors and matrices to higher dimensions.
The shape of a Tensor defines its number of dimensions and the size of each dimension. The rank of a Tensor provides the number of dimensions (n-dimensions) -- you can also think of this as the Tensor's order or degree.
Let's first look at 0-d Tensors, of which a scalar is an example:
Vectors and lists can be used to create 1-d Tensors:
Next we consider creating 2-d (i.e., matrices) and higher-rank Tensors. For examples, in future labs involving image processing and computer vision, we will use 4-d Tensors. Here the dimensions correspond to the number of example images in our batch, image height, image width, and the number of color channels.
As you have seen, the shape of a Tensor provides the number of elements in each Tensor dimension. The shape is quite useful, and we'll use it often. You can also use slicing to access subtensors within a higher-rank Tensor:
1.2 Computations on Tensors
A convenient way to think about and visualize computations in TensorFlow is in terms of graphs. We can define this graph in terms of Tensors, which hold data, and the mathematical operations that act on these Tensors in some order. Let's look at a simple example, and define this computation using TensorFlow:
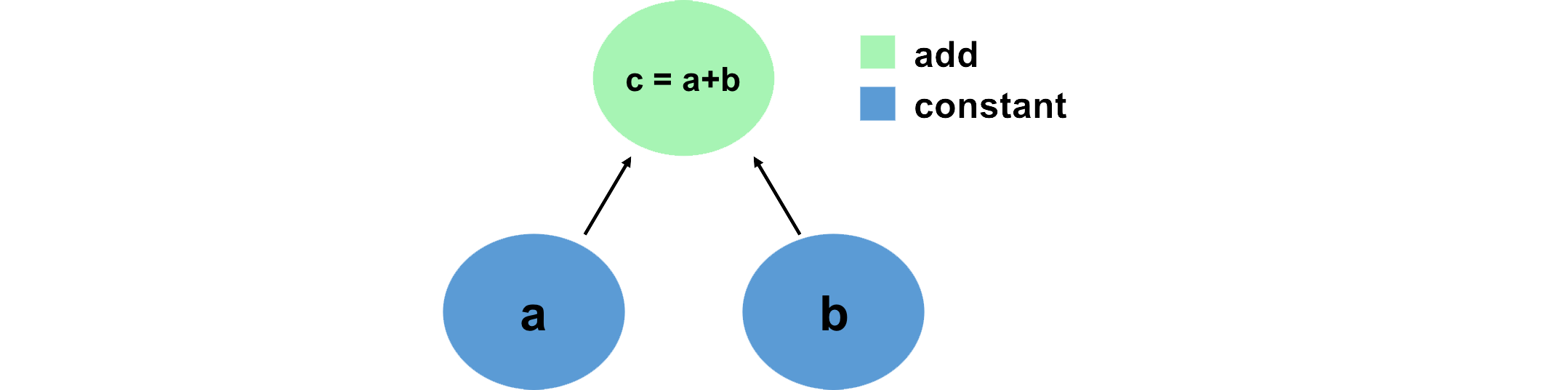
Notice how we've created a computation graph consisting of TensorFlow operations, and how the output is a Tensor with value 76 -- we've just created a computation graph consisting of operations, and it's executed them and given us back the result.
Now let's consider a slightly more complicated example:
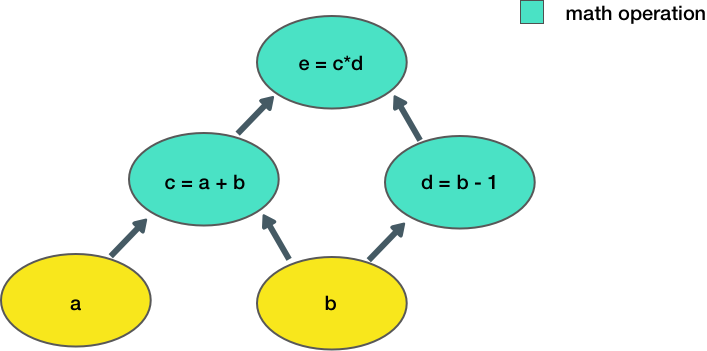
Here, we take two inputs, a, b, and compute an output e. Each node in the graph represents an operation that takes some input, does some computation, and passes its output to another node.
Let's define a simple function in TensorFlow to construct this computation function:
Now, we can call this function to execute the computation graph given some inputs a,b:
Notice how our output is a Tensor with value defined by the output of the computation, and that the output has no shape as it is a single scalar value.
1.3 Neural networks in TensorFlow
We can also define neural networks in TensorFlow. TensorFlow uses a high-level API called Keras that provides a powerful, intuitive framework for building and training deep learning models.
Let's first consider the example of a simple perceptron defined by just one dense layer: , where represents a matrix of weights, is a bias, is the input, is the sigmoid activation function, and is the output. We can also visualize this operation using a graph:
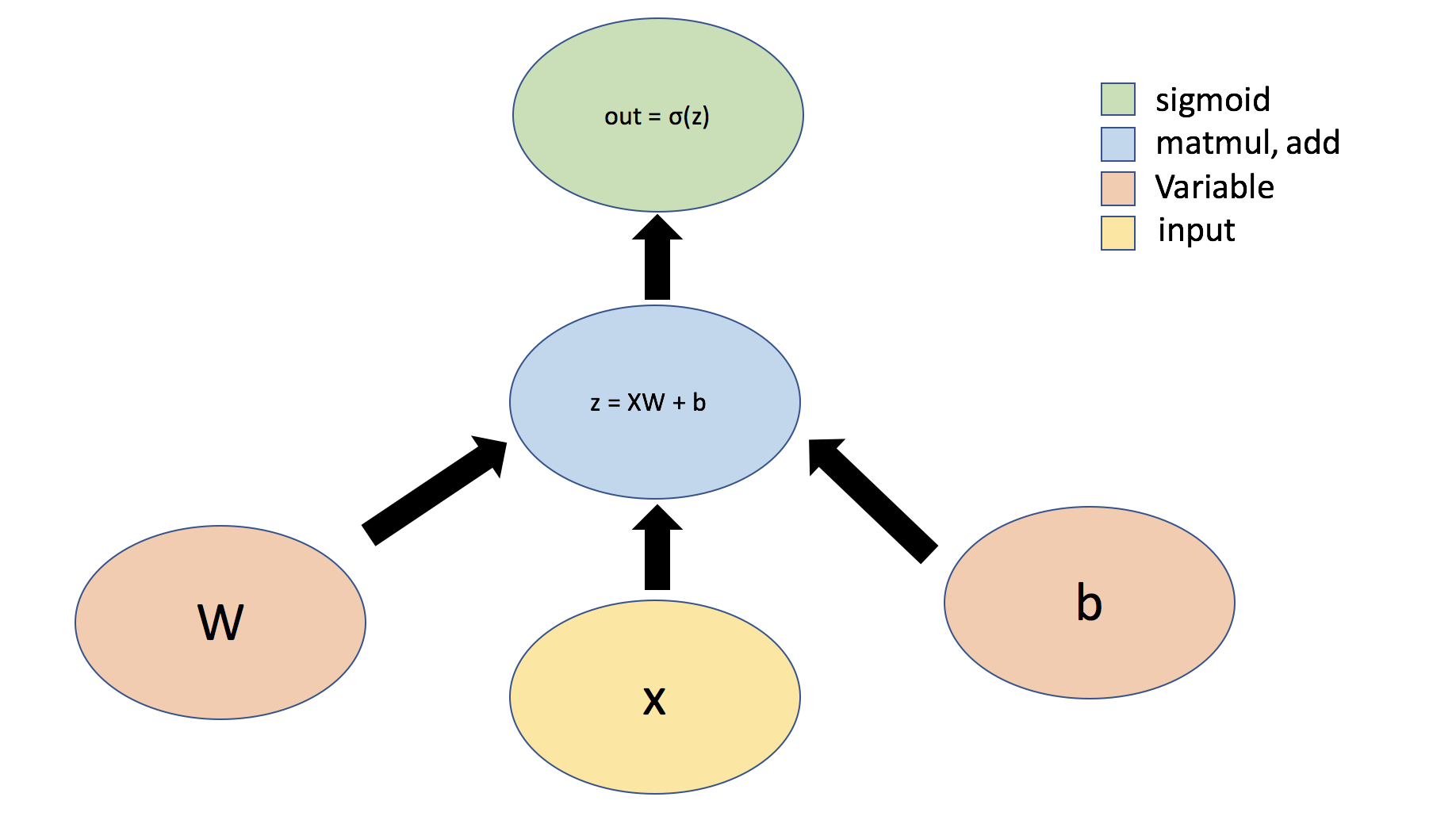
Tensors can flow through abstract types called Layers -- the building blocks of neural networks. Layers implement common neural networks operations, and are used to update weights, compute losses, and define inter-layer connectivity. We will first define a Layer to implement the simple perceptron defined above.
Conveniently, TensorFlow has defined a number of Layers that are commonly used in neural networks, for example a Dense. Now, instead of using a single Layer to define our simple neural network, we'll use the Sequential model from Keras and a single Dense layer to define our network. With the Sequential API, you can readily create neural networks by stacking together layers like building blocks.
That's it! We've defined our model using the Sequential API. Now, we can test it out using an example input:
In addition to defining models using the Sequential API, we can also define neural networks by directly subclassing the Model class, which groups layers together to enable model training and inference. The Model class captures what we refer to as a "model" or as a "network". Using Subclassing, we can create a class for our model, and then define the forward pass through the network using the call function. Subclassing affords the flexibility to define custom layers, custom training loops, custom activation functions, and custom models. Let's define the same neural network as above now using Subclassing rather than the Sequential model.
Just like the model we built using the Sequential API, let's test out our SubclassModel using an example input.
Importantly, Subclassing affords us a lot of flexibility to define custom models. For example, we can use boolean arguments in the call function to specify different network behaviors, for example different behaviors during training and inference. Let's suppose under some instances we want our network to simply output the input, without any perturbation. We define a boolean argument isidentity to control this behavior:
Let's test this behavior:
Now that we have learned how to define Layers as well as neural networks in TensorFlow using both the Sequential and Subclassing APIs, we're ready to turn our attention to how to actually implement network training with backpropagation.
1.4 Automatic differentiation in TensorFlow
Automatic differentiation is one of the most important parts of TensorFlow and is the backbone of training with backpropagation. We will use the TensorFlow GradientTape tf.GradientTape to trace operations for computing gradients later.
When a forward pass is made through the network, all forward-pass operations get recorded to a "tape"; then, to compute the gradient, the tape is played backwards. By default, the tape is discarded after it is played backwards; this means that a particular tf.GradientTape can only compute one gradient, and subsequent calls throw a runtime error. However, we can compute multiple gradients over the same computation by creating a persistent gradient tape.
First, we will look at how we can compute gradients using GradientTape and access them for computation. We define the simple function and compute the gradient:
In training neural networks, we use differentiation and stochastic gradient descent (SGD) to optimize a loss function. Now that we have a sense of how GradientTape can be used to compute and access derivatives, we will look at an example where we use automatic differentiation and SGD to find the minimum of . Here is a variable for a desired value we are trying to optimize for; represents a loss that we are trying to minimize. While we can clearly solve this problem analytically (), considering how we can compute this using GradientTape sets us up nicely for future labs where we use gradient descent to optimize entire neural network losses.
GradientTape provides an extremely flexible framework for automatic differentiation. In order to back propagate errors through a neural network, we track forward passes on the Tape, use this information to determine the gradients, and then use these gradients for optimization using SGD.