Path: blob/master/xtra_labs/uncertainty/Part1_IntroductionCapsa.ipynb
903 views
 Visit MIT Deep Learning
Visit MIT Deep Learning Run in Google Colab
Run in Google Colab View Source on GitHub
View Source on GitHubCopyright Information
Laboratory 3: Debiasing, Uncertainty, and Robustness
Part 1: Introduction to Capsa
In this lab, we'll explore different ways to make deep learning models more robust and trustworthy.
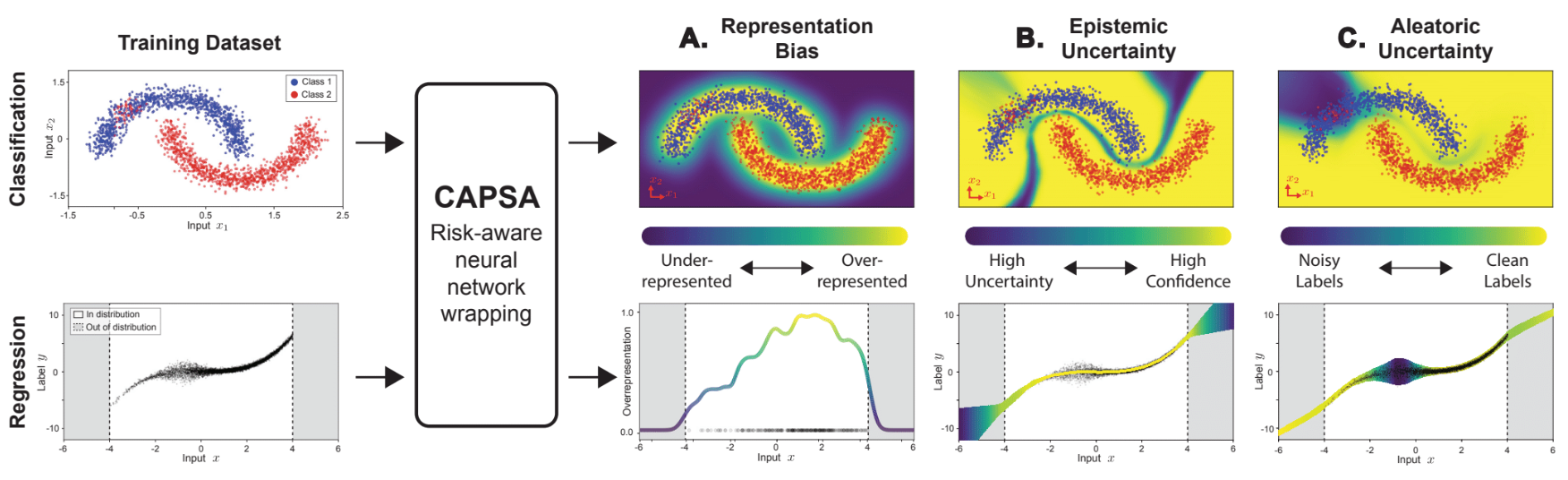
To achieve this it is critical to be able to identify and diagnose issues of bias and uncertainty in deep learning models, as we explored in the Facial Detection Lab 2. We need benchmarks that uniformly measure how uncertain a given model is, and we need principled ways of measuring bias and uncertainty. To that end, in this lab, we'll utilize Capsa, a risk-estimation wrapping library developed by Themis AI. Capsa supports the estimation of three different types of risk, defined as measures of how robust and trustworthy our model is. These are:
Representation bias: reflects how likely combinations of features are to appear in a given dataset. Often, certain combinations of features are severely under-represented in datasets, which means models learn them less well and can thus lead to unwanted bias.
Data uncertainty: reflects noise in the data, for example when sensors have noisy measurements, classes in datasets have low separations, and generally when very similar inputs lead to drastically different outputs. Also known as aleatoric uncertainty.
Model uncertainty: captures the areas of our underlying data distribution that the model has not yet learned or has difficulty learning. Areas of high model uncertainty can be due to out-of-distribution (OOD) samples or data that is harder to learn. Also known as epistemic uncertainty.
CAPSA overview
This lab introduces Capsa and its functionalities, to next build automated tools that use Capsa to mitigate the underlying issues of bias and uncertainty.
The core idea behind Capsa is that any deep learning model of interest can be wrapped -- just like wrapping a gift -- to be made aware of its own risks. Risk is captured in representation bias, data uncertainty, and model uncertainty.
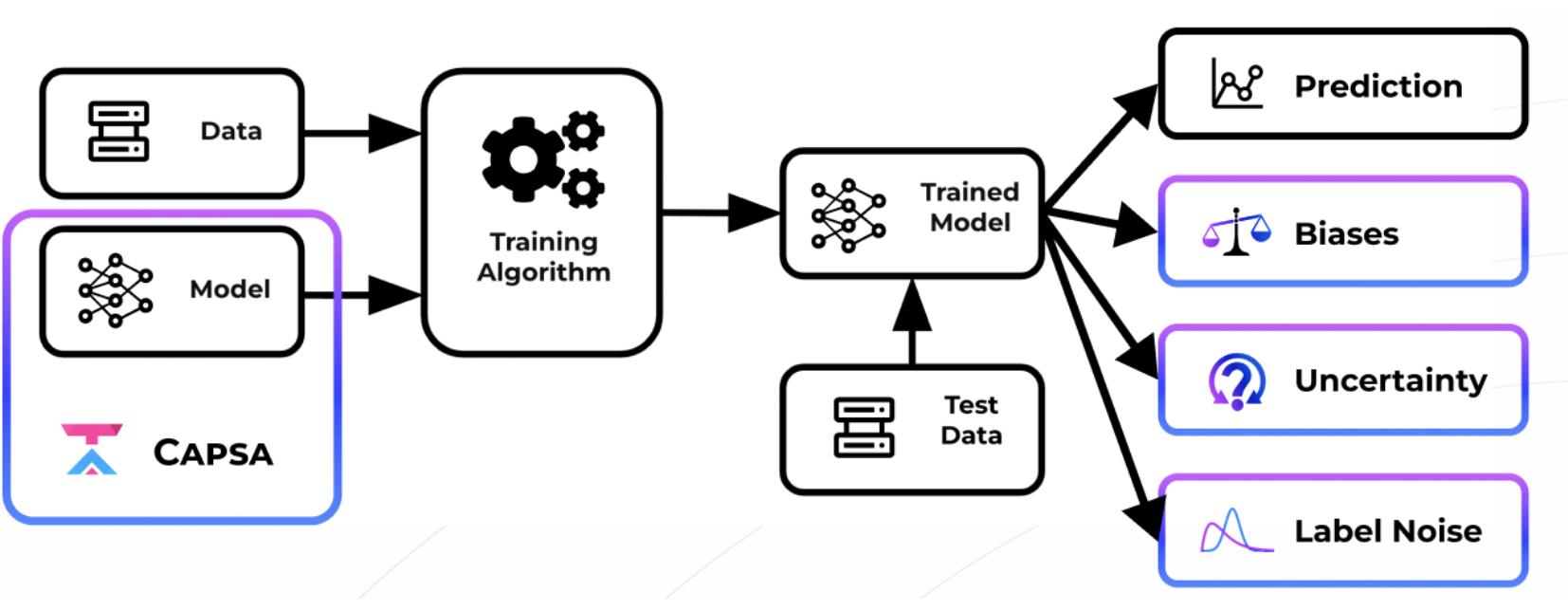
This means that Capsa takes the user's original model as input, and modifies it minimally to create a risk-aware variant while preserving the model's underlying structure and training pipeline. Capsa is a one-line addition to any training workflow in TensorFlow. In this part of the lab, we'll apply Capsa's risk estimation methods to a simple regression problem to further explore the notions of bias and uncertainty.
Please refer to Capsa's documentation for additional details.
Let's get started by installing the necessary dependencies:
1.1 Dataset
We will build understanding of bias and uncertainty by training a neural network for a simple 2D regression task: modeling the function . We will use Capsa to analyze this dataset and the performance of the model. Noise and missing-ness will be injected into the dataset.
Let's generate the dataset and visualize it:
In the plot above, the blue points are the training data, which will be used as inputs to train the neural network model. The red line is the ground truth data, which will be used to evaluate the performance of the model.
TODO: Inspecting the 2D regression dataset
Write short (~1 sentence) answers to the questions below to complete the TODOs:
What are your observations about where the train data and test data lie relative to each other?
What, if any, areas do you expect to have high/low aleatoric (data) uncertainty?
What, if any, areas do you expect to have high/low epistemic (model) uncertainty?
1.2 Regression on cubic dataset
Next we will define a small dense neural network model that can predict y given x: this is a classical regression task! We will build the model and use the model.fit() function to train the model -- normally, without any risk-awareness -- using the train dataset that we visualized above.
Now, we are ready to evaluate our neural network. We use the test data to assess performance on the regression task, and visualize the predicted values against the true values.
Given your observation of the data in the previous plot, where do you expect the model to perform well? Let's test the model and see:
TODO: Analyzing the performance of standard regression model
Write short (~1 sentence) answers to the questions below to complete the TODOs:
Where does the model perform well?
Where does the model perform poorly?
1.3 Evaluating bias
Now that we've seen what the predictions from this model look like, we will identify and quantify bias and uncertainty in this problem. We first consider bias.
Recall that representation bias reflects how likely combinations of features are to appear in a given dataset. Capsa calculates how likely combinations of features are by using a histogram estimation approach: the capsa.HistogramWrapper. For low-dimensional data, the capsa.HistogramWrapper bins the input directly into discrete categories and measures the density. More details of the HistogramWrapper and how it can be used are available here.
We start by taking our dense_NN and wrapping it with the capsa.HistogramWrapper:
Now that we've wrapped the classifier, let's re-train it to update the bias estimates as we train. We can use the exact same training pipeline, using compile to build the model and model.fit() to train the model:
We can now use our wrapped model to assess the bias for a given test input. With the wrapping capability, Capsa neatly allows us to output a bias score along with the predicted target value. This bias score reflects the density of data surrounding an input point -- the higher the score, the greater the data representation and density. The wrapped, risk-aware model outputs the predicted target and bias score after it is called!
Let's see how it is done:
TODO: Evaluating bias with wrapped regression model
Write short (~1 sentence) answers to the questions below to complete the TODOs:
How does the bias score relate to the train/test data density from the first plot?
What is one limitation of the Histogram approach that simply bins the data based on frequency?
1.4 Estimating data uncertainty
Next we turn our attention to uncertainty, first focusing on the uncertainty in the data -- the aleatoric uncertainty.
As introduced in Lecture 5 on Robust & Trustworthy Deep Learning, in regression we can estimate aleatoric uncertainty by training the model to predict both a target value and a variance for every input. Because we estimate both a mean and variance for every input, this method is called Mean Variance Estimation (MVE). MVE involves modifying the output layer to predict both the mean and variance, and changing the loss to reflect the prediction likelihood.
Capsa automatically implements these changes for us: we can wrap a given model using capsa.MVEWrapper to use MVE to estimate aleatoric uncertainty. All we have to do is define the model and the loss function to evaluate its predictions! More details of the MVEWrapper and how it can be used are available here.
Let's take our standard network, wrap it with capsa.MVEWrapper, build the wrapped model, and then train it for the regression task. Finally, we evaluate performance of the resulting model by quantifying the aleatoric uncertainty across the data space:
TODO: Estimating aleatoric uncertainty
Write short (~1 sentence) answers to the questions below to complete the TODOs:
For what values of is the aleatoric uncertainty high or increasing suddenly?
How does your answer in (1) relate to how the values are distributed?
1.5 Estimating model uncertainty
Finally, we use Capsa for estimating the uncertainty underlying the model predictions -- the epistemic uncertainty. In this example, we'll use ensembles, which essentially copy the model N times and average predictions across all runs for a more robust prediction, and also calculate the variance of the N runs to estimate the uncertainty.
Capsa provides a neat wrapper, capsa.EnsembleWrapper, to make an ensemble from an input model. Just like with aleatoric estimation, we can take our standard dense network model, wrap it with capsa.EnsembleWrapper, build the wrapped model, and then train it for the regression task. More details of the EnsembleWrapper and how it can be used are available here.
Finally, we evaluate the resulting model by quantifying the epistemic uncertainty on the test data:
TODO: Estimating epistemic uncertainty
Write short (~1 sentence) answers to the questions below to complete the TODOs:
For what values of is the epistemic uncertainty high or increasing suddenly?
How does your answer in (1) relate to how the values are distributed (refer back to original plot)? Think about both the train and test data.
How could you reduce the epistemic uncertainty in regions where it is high?
1.6 Conclusion
You've just analyzed the bias, aleatoric uncertainty, and epistemic uncertainty for your first risk-aware model! This is a task that data scientists do constantly to determine methods of improving their models and datasets.
In the next part of the lab, you'll continue to build off of these concepts to study them in the context of facial detection systems: not only diagnosing issues of bias and uncertainty, but also developing solutions to mitigate these risks.