
Path: blob/master/xtra_labs/uncertainty/Part2_BiasAndUncertainty.ipynb
911 views
 Visit MIT Deep Learning
Visit MIT Deep Learning Run in Google Colab
Run in Google Colab View Source on GitHub
View Source on GitHubCopyright Information
Laboratory 3: Debiasing, Uncertainty, and Robustness
Part 2: Mitigating Bias and Uncertainty in Facial Detection Systems
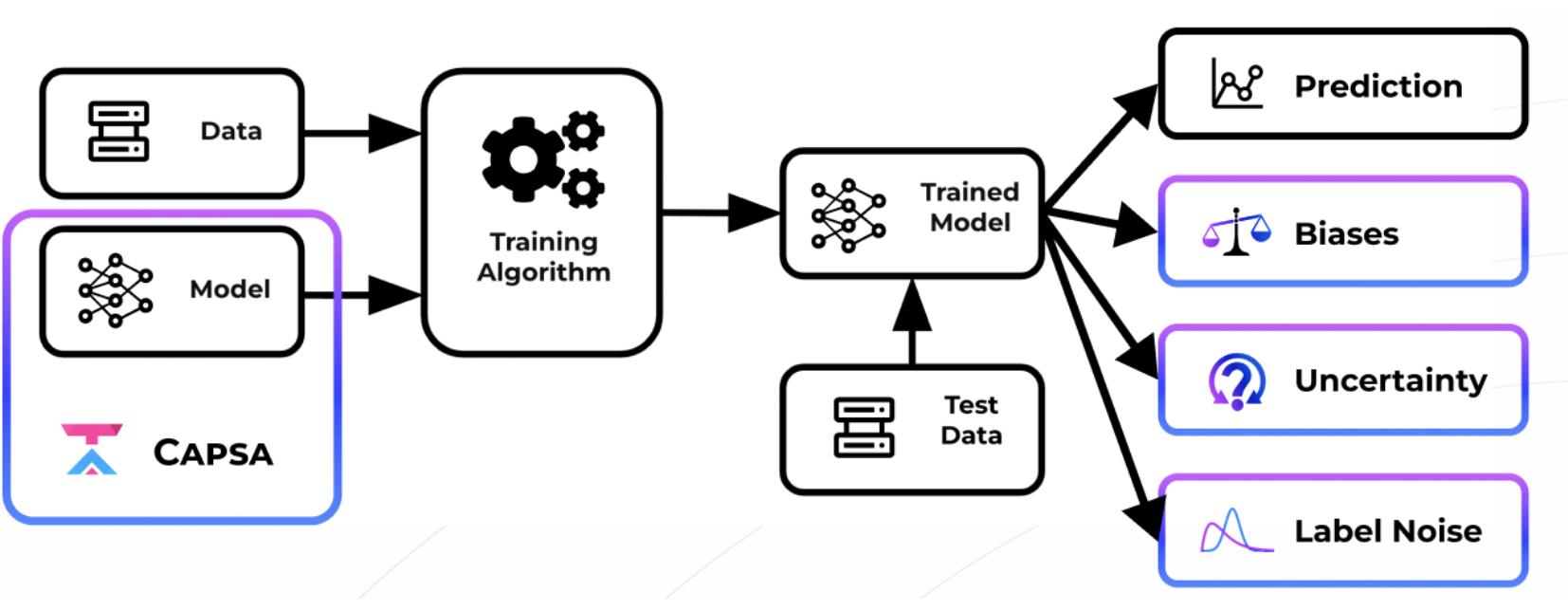
In Lab 2, we defined a semi-supervised VAE (SS-VAE) to diagnose feature representation disparities and biases in facial detection systems. In Lab 3 Part 1, we gained experience with Capsa and its ability to build risk-aware models automatically through wrapping. Now in this lab, we will put these two together: using Capsa to build systems that can automatically uncover and mitigate bias and uncertainty in facial detection systems.
As we have seen, automatically detecting and mitigating bias and uncertainty is crucial to deploying fair and safe models. Building off our foundation with Capsa, developed by Themis AI, we will now use Capsa for the facial detection problem, in order to diagnose risks in facial detection models. You will then design and create strategies to mitigate these risks, with goal of improving model performance across the entire facial detection dataset.
Your goal in this lab -- and the associated competition -- is to design a strategic solution for bias and uncertainty mitigation, using Capsa. The approaches and solutions with oustanding performance will be recognized with outstanding prizes! Details on the submission process are at the end of this lab.
Let's get started by installing the necessary dependencies:
3.1 Datasets
Since we are again focusing on the facial detection problem, we will use the same datasets from Lab 2. To remind you, we have a dataset of positive examples (i.e., of faces) and a dataset of negative examples (i.e., of things that are not faces).
Positive training data: CelebA Dataset. A large-scale dataset (over 200K images) of celebrity faces.
Negative training data: ImageNet. A large-scale dataset with many images across many different categories. We will take negative examples from a variety of non-human categories.
We will evaluate trained models on an independent test dataset of face images to diagnose and mitigate potential issues with bias, fairness, and confidence. This will be a larger test dataset for evaluation purposes.
We begin by importing these datasets. We have defined a DatasetLoader class that does a bit of data pre-processing to import the training data in a usable format.
Building robustness to bias and uncertainty
Remember that we'll be training our facial detection classifiers on the large, well-curated CelebA dataset (and ImageNet), and then evaluating their accuracy by testing them on an independent test dataset. We want to mitigate the effects of unwanted bias and uncertainty on the model's predictions and performance. Your goal is to build the best-performing, most robust model, one that achieves high classification accuracy across the entire test dataset.
To achieve this, you may want to consider the three metrics introduced with Capsa: (1) representation bias, (2) data or aleatoric uncertainty, and (3) model or epistemic uncertainty. Note that all three of these metrics are different! For example, we can have well-represented examples that still have high epistemic uncertainty. Think about how you may use these metrics to improve the performance of your model.
3.2 Risk-aware facial detection with Capsa
In Lab 2, we built a semi-supervised variational autoencoder (SS-VAE) to learn the latent structure of our database and to uncover feature representation disparities, inspired by the approach of uncover hidden biases. In this lab, we'll show that we can use Capsa to build the same VAE in one line!
This sets the foundation for quantifying a key risk metric -- representation bias -- for the facial detection problem. In working to improve your model's performance, you will want to consider representation bias carefully and think about how you could mitigate the effect of representation bias.
Just like in Lab 2, we begin by defining a standard CNN-based classifier. We will then use Capsa to wrap the model and build the risk-aware VAE variant.
Capsa's HistogramVAEWrapper
With our base classifier Capsa allows us to automatically define a VAE implementing that base classifier. Capsa's HistogramVAEWrapper builds this VAE to analyze the latent space distribution, just as we did in Lab 2.
Specifically, capsa.HistogramVAEWrapper constructs a histogram with num_bins bins across every dimension of the latent space, and then calculates the joint probability of every sample according to the constructed histograms. The samples with the lowest joint probability have the lowest representation; the samples with the highest joint probability have the highest representation.
capsa.HistogramVAEWrapper takes in a number of arguments including:
base_model: the model to be transformed into the risk-aware variant.num_bins: the number of bins we want to discretize our distribution into.queue_size: the number of samples we want to track at any given point.decoder: the decoder architecture for the VAE.
We define the same decoder as in Lab 2:
We are ready to create the wrapped model using capsa.HistogramVAEWrapper by passing in the relevant arguments!
Just like in the wrappers in the Introduction to Capsa lab, we can take our standard CNN classifier, wrap it with capsa.HistogramVAEWrapper, build the wrapped model. The wrapper then enablings semi-supervised training for the facial detection task. As the wrapped model trains, the classifier weights are updated, and the VAE-wrapped model learns to track feature distributions over the latent space. More details of the HistogramVAEWrapper and how it can be used are available here.
We can then evaluate the representation bias of the classifier on the test dataset. By calling the wrapped_model on our test data, we can automatically generate representation bias and uncertainty scores that are normally manually calculated. Let's wrap our base CNN classifier using Capsa, train and build the resulting model, and start to process the test data:
3.3 Analyzing representation bias with Capsa
From the above output, we have an estimate for the representation bias score! We can analyze the representation scores to start to think about manifestations of bias in the facial detection dataset. Before you run the next code block, which faces would you expect to be underrepresented in the dataset? Which ones do you think will be overrepresented?
We can also quantify how the representation density relates to the classification accuracy by plotting the two against each other:
These representations scores relate back to data examples, so we can visualize what the average face looks like for a given percentile of representation density:
TODO: Scoring representation densities with Capsa
Write short answers to the questions below to complete the TODOs:
How does accuracy relate to the representation score? From this relationship, what can you determine about the bias underlying the dataset?
What does the average face in the 10th percentile of representation density look like (i.e., the face for which 10% of the data have lower probability of occuring)? What about the 90th percentile? What changes across these faces?
What could be potential limitations of the
HistogramVAEWrapperapproach as it is implemented now?
3.4 Analyzing epistemic uncertainty with Capsa
Recall that epistemic uncertainty, or a model's uncertainty in its prediction, can arise from out-of-distribution data, missing data, or samples that are harder to learn. This does not necessarily correlate with representation bias! Imagine the scenario of training an object detector for self-driving cars: even if the model is presented with many cluttered scenes, these samples still may be harder to learn than scenes with very few objects in them.
We will now use our VAE-wrapped facial detection classifier to analyze and estimate the epistemic uncertainty of the model trained on the facial detection task.
While most methods of estimating epistemic uncertainty are sampling-based, we can also use reconstruction-based methods -- like using VAEs -- to estimate epistemic uncertainty. If a model is unable to provide a good reconstruction for a given data point, it has not learned that area of the underlying data distribution well, and therefore has high epistemic uncertainty.
Since we've already used the HistogramVAEWrapper to calculate the histograms for representation bias quantification, we can use the exact same VAE wrapper to shed insight into epistemic uncertainty! Capsa helps us do exactly that. When we called the model, we returned the classification prediction, uncertainty, and bias for every sample: predictions, uncertainty, bias = wrapped_model.predict(test_imgs, batch_size=512).
Let's analyze these estimated uncertainties:
We quantify how the epistemic uncertainty relates to the classification accuracy by plotting the two against each other:
TODO: Estimating epistemic uncertainties with Capsa
Write short answers to the questions below to complete the TODOs:
How does accuracy relate to the epistemic uncertainty?
How do the results for epistemic uncertainty compare to the results for representation bias? Was this expected or unexpted? Why?
What may be instances in the facial detection task that could have high representation density but also high uncertainty?
3.4 Resampling based on risk metrics
Finally, we will use the risk metrics just computed to actually mitigate the issues of bias and uncertainty in the facial detection classifier.
Specifically, we will use the latent variables learned via the VAE to adaptively re-sample the face (CelebA) data during training, following the approach of recent work. We will alter the probability that a given image is used during training based on how often its latent features appear in the dataset. So, faces with rarer features (like dark skin, sunglasses, or hats) should become more likely to be sampled during training, while the sampling probability for faces with features that are over-represented in the training dataset should decrease (relative to uniform random sampling across the training data).
Note that we want to debias and amplify only the positive samples in the dataset -- the faces -- so we are going to only adjust probabilities and calculate scores for these samples. We focus on using the representation bias scores to implement this adaptive resampling to achieve model debiasing.
We re-define the wrapped model with HistogramVAEWrapper, and then define the adaptive resampling operation for training. At each training epoch, we compute the predictions, uncertainties, and representation bias scores, then recompute the data sampling probabilities according to the inverse of the representation bias score. That is, samples with higher representation densities will end up with lower re-sampling probabilities; samples with lower representations will end up with higher re-sampling probabilities.
Let's do all this below!
That's it! We should have a debiased model (we hope!). Let's see how the model does.
Evaluation
Let's run the same analyses as before, and plot the classification accuracy vs. the representation bias and classification accuracy vs. epistemic uncertainty. We want the model to do better across the data samples, achieving higher accuracies on the under-represented and more uncertain samples compared to previously.
3.5 Competition!
Now, you are well equipped to submit to the competition to dig in deeper into deep learning models, uncover their deficiencies with Capsa, address those deficiencies, and submit your findings!
Below are some potential areas to start investigating -- the goal of the competition is to develop creative and innovative solutions to address bias and uncertainty, and to improve the overall performance of deep learning models.
We encourage you to identify other questions that could be solved with Capsa and use those as the basis of your submission. But, to help get you started, here are some interesting questions that you might look into solving with these new tools and knowledge that you've built up:
In this lab, you learned how to build a wrapper that can estimate the bias within the training data, and take the results from this wrapper to adaptively re-sample during training to encourage learning on under-represented data.
Can we apply a similar approach to mitigate epistemic uncertainty in the model?
Can this approach be combined with your original bias mitigation approach to achieve robustness across both bias and uncertainty?
In this lab, you focused on the
HistogramVAEWrapper.
How can you use other methods of uncertainty in Capsa to strengthen your uncertainty estimates? Checkout Capsa documentation for a list of all wrappers, and ask for help if you run into trouble applying them to your model!
Can you combine uncertainty estimates from different wrappers to achieve greater robustness in your estimates?
So far in this part of the lab, we focused only on bias and epistemic uncertainty. What about aleatoric uncetainty?
We've curated a dataset (available at this URL) of faces with greater amounts of aleatoric uncertainty -- can you use Capsa to wrap your model, estimate aleatoric uncertainty, and remove it from the dataset?
Does removing aleatoric uncertainty help improve your training accuracy on this new dataset?
Can you develop an approach to incorporate this aleatoric uncertainty estimation into the predictive training pipeline in order to improve accuracy? You may find some surprising results!!
How can the performance of the classifier above be improved even further? We purposely did not optimize hyperparameters to leave this up to you!
Are there other applications that you think Capsa and bias/uncertainty estimation would be helpful in?
Try integrating Capsa into another domain or dataset and submit your findings!
Are there applications where you may not want to debias your model?
To enter the competition, please upload the following to the lab submission site:
Written short-answer responses to
TODOs from Lab 2, Part 2 on Facial Detection.Description of the wrappers, algorithms, and approach you used. What was your strategy? What wrappers did you implement? What debiasing or mitigation strategies did you try? How and why did these modifications affect performance? Describe any modifications or implementations you made to the template code, and what their effects were. Written text, visual diagram, and plots welcome!
Jupyter notebook with the code you used to generate your results (along with all plots/visuals generated).
Name your file in the following format: [FirstName]_[LastName]_Face, followed by the file format (.zip, .ipynb, .pdf, etc). ZIP files are preferred over individual files. If you submit individual files, you must name the individual files according to the above nomenclature (e.g., [FirstName]_[LastName]_Face_TODO.pdf, [FirstName]_[LastName]_Face_Report.pdf, etc.). Submit your files here.
We encourage you to think about and maybe even address some questions raised by this lab and dig into any questions that you may have about the risks inherrent to neural networks and their data.
