
![]()
🤗 Training with Diffusers
In recent months, it has become clear that diffusion models have taken the throne as the state-of-the-art generative models. Here, we will use Hugging Face's brand new Diffusers library to train a simple diffusion model.
Installing the dependencies
This notebook leverages the 🤗 Datasets library to load and preprocess image datasets and the 🤗 Accelerate library to simplify training on any number of GPUs, with features like automatic gradient accumulation and tensorboard logging. Let's install them here:
To be able to share your model with the community, there are a few more steps to follow.|
First you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!) then execute the following cell and input your write token:
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
Then you need to install Git-LFS to upload your model checkpoints:
Config
For convenience, we define a configuration grouping all the training hyperparameters. This would be similar to the arguments used for a training script. Here we choose reasonable defaults for hyperparameters like num_epochs, learning_rate, lr_warmup_steps, but feel free to adjust them if you train on your own dataset. For example, num_epochs can be increased to 100 for better visual quality.
Loading the dataset
We will use the 🤗 Datasets library to download our image dataset.
In this case, the Butterflies dataset is hosted remotely, but you can load a local ImageFolder as shown in the commets below.
The dataset contains several extra features (columns), but the one that we're interested in is image:
Since the Image feature loads the images with PIL, we can easily look at a few examples:

The images in the dataset are all different, so we need to preprocess them first:
Resizemakes the images conform to a square resolution ofconfig.image_sizeRandomHorizontalFlipaugments the dataset by randomly mirroring the images.Normalizeis important to rescale the pixel values into a[-1, 1]range (which our model will expect).
🤗 Datasets offer a handy set_transform() method to apply the image transformations on the fly during training:
Let's see what they look like now

Now that all our images have the same size and are converted to tensors, we can create the dataloader we will use for training.
Defining the diffusion model
Here we set up our diffusion model. Diffusion models are neural networks that are trained to predict slightly less noisy images from a noisy input. At inference, they can be used to iteratively transform a random noise to generate an image:

Figure from DDPM paper (https://arxiv.org/abs/2006.11239).
Don't worry too much about the math if you're not familiar with it, the import part to remember is that our model corresponds to the arrow (which is a fancy way of saying: predict a slightly less noisy image).
The interesting part is that it's really easy to add some noise to an image, so the training can happen in a semi-supervised fashion as follows:
Take an image from the training set.
Apply to it some random noise times (this will give the and the in the figure above).
Give this noisy image to the model along with the value of .
Compute a loss from the output of the model and the noised image .
Then we can apply gradient descent and repeat this process multiple times.
Most diffusion models use architectures that are some variant of a U-net and that's what we'll use here.
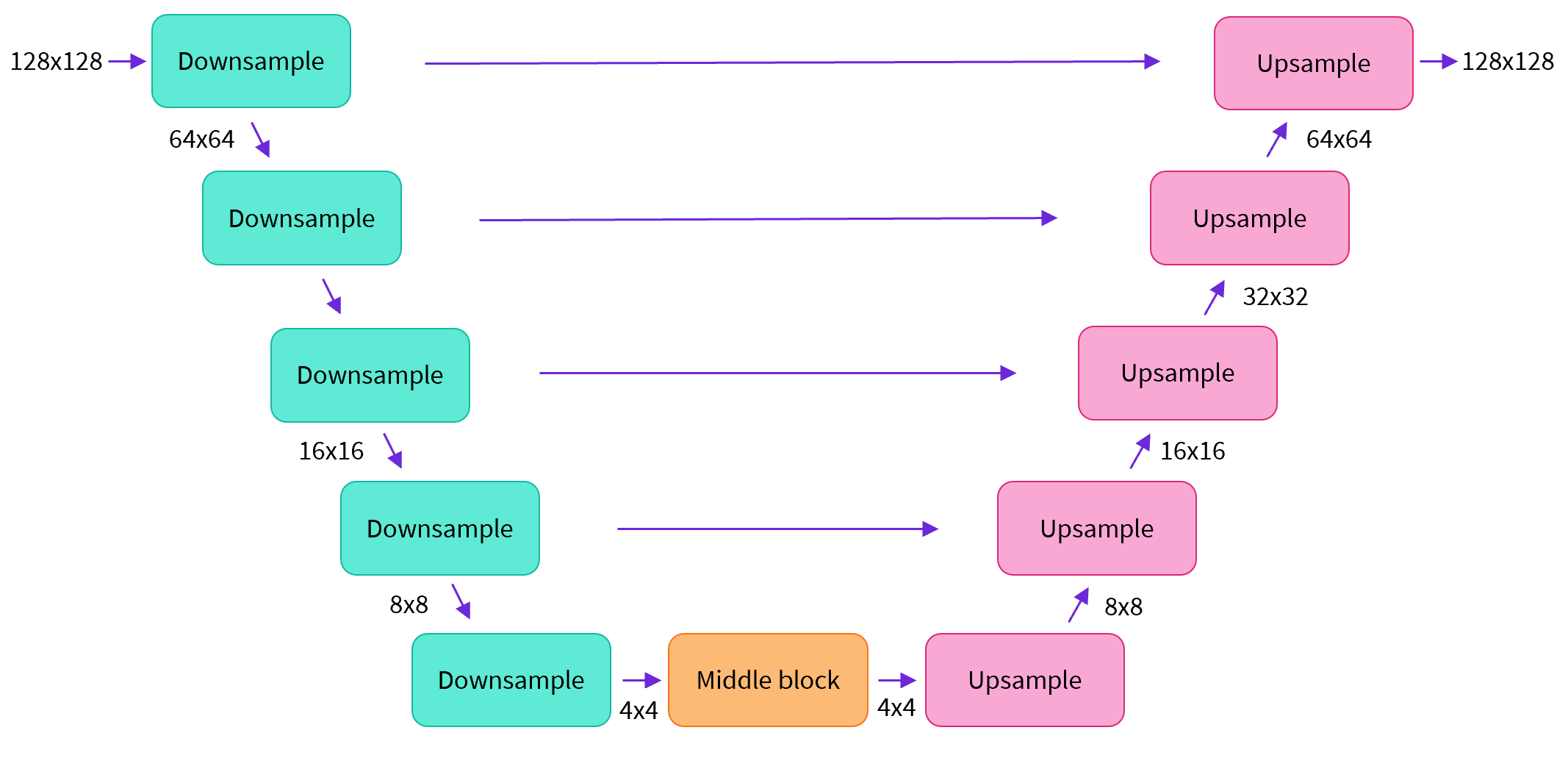
In a nutshell:
the model has the input image go through several blocks of ResNet layers which halves the image size by 2
then through the same number of blocks that upsample it again.
there are skip connections linking the features on the downample path to the corresponsding layers in the upsample path.
A key feature of this model is that it predicts images of the same size as the input, which is exactly what we need here.
Diffusers provides us a handy UNet2DModel class which creates the desired architecture in PyTorch.
Let's create a U-net for our desired image size. Note that down_block_types correspond to the downsampling blocks (green on the diagram above), and up_block_types are the upsampling blocks (red on the diagram):
Let's get a sample image from our dataset and pass it into our model. We just need to add a batch dimension:
And let's check the output is a tensor of the same exact shape:
Great!
Note that our model takes in the (noisy) image and also the current time-step (as we saw before in the training overview). That time-step information is converted for the model using a sinusoidal positional embedding, similar to what Transformer models often do.
Now that we have our model, we just need an object to add noise to an image. This is done by the schedulers in the diffusers library.
Defining the noise scheduler
Depending on the diffusion algorithm you want to use, the way images are noised is slightly different. That's why 🤗 Diffusers contains different scheduler classes which each define the algorithm-specific diffusion steps. Here we are going to use the DDPMScheduler which corresponds to the training denoising and training algorithm proposed in Denoising Diffusion Probabilistic Models.
Let's see how this noise scheduler works: it takes a batch of images from the trainng set (here we will reuse the batch of one image sample_image form before), a batch of random noise of the same shape and the timesteps for each image (which correspond to the number of times we want to apply noise to each image):

In the DDPM algorithm, the training objective of the model is then to be able to predict the noise we used in noise_scheduler.add_noise, so the loss at this step would be:
Setting up training
We have all we need to be able to train our model! Let's use a standard AdamW optimizer:
And a cosine learning rate schedule:
To evaluate our model, we use the DDPMPipeline which is an easy way to perform end-to-end inference (see this notebook [TODO link] for more detail). We will use this pipeline to generate a batch of sample images and save it as a grid to the disk.
With this in end, we can group all together and write our training function. This just wraps the training step we saw in the previous section in a loop, using Accelerate for easy TensorBoard logging, gradient accumulation, mixed precision training and multi-GPUs or TPU training.
Let's train!
Let's launch the training (including multi-GPU training) from the notebook using Accelerate's notebook_launcher function:
Let's have a look at the final image grid produced by the trained diffusion model:

Not bad! There's room for improvement of course, so feel free to play with the hyperparameters, model definition and image augmentations 🤗
If you've chosen to upload the model to the Hugging Face Hub, its repository should now look like so: https://huggingface.co/anton-l/ddpm-butterflies-128/tree/main
If you want to dive deeper into the code, we also have more advanced training scripts with features like Exponential Moving Average of model weights here: