
Path: blob/main/examples/image_classification-tf.ipynb
8231 views
Fine-tuning for Image Classification with 🤗 Transformers
This notebook shows how to fine-tune any pretrained Vision model for Image Classification on a custom dataset. The idea is to add a randomly initialized classification head on top of a pre-trained encoder, and fine-tune the model altogether on a labeled dataset.
ImageFolder
This notebook leverages the ImageFolder feature to easily run the notebook on a custom dataset (namely, EuroSAT in this tutorial). You can either load a Dataset from local folders or from local/remote files, like zip or tar.
Any model
This notebook is built to run on any image classification dataset with any vision model checkpoint from the Model Hub as long as that model has a TensorFlow version with a Image Classification head, such as:
in short, any model supported by TFAutoModelForImageClassification.
Data augmentation
This notebook leverages TensorFlow's image module for applying data augmentation. Alternative notebooks which leverage other libraries such as Albumentations to come!
Depending on the model and the GPU you are using, you might need to adjust the batch size to avoid out-of-memory errors. Set those two parameters, then the rest of the notebook should run smoothly.
In this notebook, we'll fine-tune from the https://huggingface.co/microsoft/swin-tiny-patch4-window7-224 checkpoint, but note that there are many, many more available on the hub.
Before we start, let's install the datasets and transformers libraries.
If you're opening this notebook locally, make sure your environment has an install from the last version of those libraries.
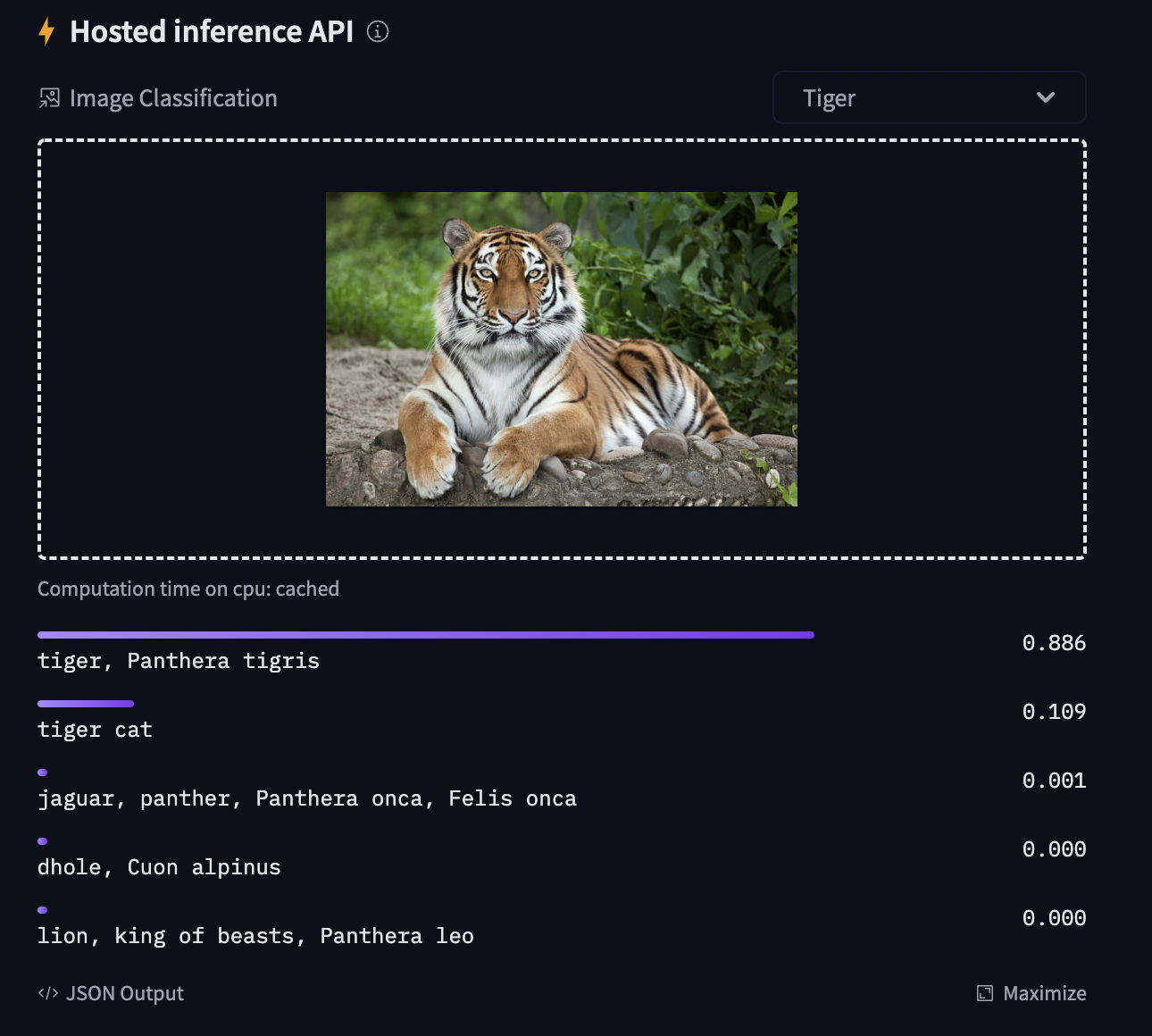
To be able to share your model with the community and generate results like the one shown in the picture below via the inference API, there are a few more steps to follow.
First you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!) then execute the following cell and input your token:
Then you need to install Git-LFS to upload your model checkpoints:
Fine-tuning a model on an image classification task
In this notebook, we will see how to fine-tune one of the 🤗 Transformers vision models on an Image Classification dataset.
Given an image, the goal is to predict an appropriate class for it, like "tiger". The screenshot below is taken from a ViT fine-tuned on ImageNet-1k - try out the inference widget!
Loading the dataset
We will use the 🤗 Datasets library's ImageFolder feature to download our custom dataset into a DatasetDict.
In this case, the EuroSAT dataset is hosted remotely, so we provide the data_files argument. Alternatively, if you have local folders with images, you can load them using the data_dir argument.
Let us also load the Accuracy metric, which we'll use to evaluate our model both during and after training.
The dataset object itself is a DatasetDict, which contains one key per split (in this case, only "train" for a training split).
To access an actual element, you need to select a split first, then give an index:
Each example consists of an image and a corresponding label. We can also verify this by checking the features of the dataset:
The cool thing is that we can directly view the image (as the 'image' field is an Image feature), as follows:
Let's make it a little bigger as the images in the EuroSAT dataset are of low resolution (64x64 pixels):
Let's print the corresponding label:
As you can see, the label field is not an actual string label. By default the ClassLabel fields are encoded into integers for convenience:
Let's create an id2label dictionary to decode them back to strings and see what they are. The inverse label2id will be useful too, when we load the model later.
Preprocessing the data
Before we can feed these images to our model, we need to preprocess them.
Preprocessing images typically comes down to (1) resizing them to a particular size (2) normalizing the color channels (R,G,B) using a mean and standard deviation. These are referred to as image transformations.
In addition, one typically performs what is called data augmentation during training (like random cropping and flipping) to make the model more robust and achieve higher accuracy. Data augmentation is also a great technique to increase the size of the training data.
We will use tf.image for the image transformations/data augmentation in this tutorial, but note that one can use any other package (like albumentations, imgaug, etc.).
To make sure we (1) resize to the appropriate size (2) use the appropriate image mean and standard deviation for the model architecture we are going to use, we instantiate what is called a feature extractor with the AutoFeatureExtractor.from_pretrained method.
This feature extractor is a minimal preprocessor that can be used to prepare images for inference.
The Datasets library is made for processing data very easily. We can write custom functions, which can then be applied on an entire dataset (either using .map() or .set_transform()).
Here we define 2 separate functions, one for training (which includes data augmentation) and one for validation (which only includes resizing, center cropping and normalizing).
Let's quickly visualise some example outputs from our processing pipeline.
Part of the processing pipeline rescales them between [0, 1] and normalizes them. This results in pixel values having negative values. To easily visualise and compare the original images and augmentations we undo this normalization and rescaling here.
Next, we can preprocess our dataset by applying these functions. We will use the set_transform functionality, which allows to apply the functions above on-the-fly (meaning that they will only be applied when the images are loaded in RAM).
Let's access an element to see that we've added a "pixel_values" feature:
Training the model
Now that our data is ready, we can download the pretrained model and fine-tune it. For classification we use the TFAutoModelForImageClassification class. Calling the from_pretrained method on it will download and cache the weights for us. As the label ids and the number of labels are dataset dependent, we pass label2id, and id2label alongside the model_checkpoint here. This will make sure a custom classification head will be created (with a custom number of output neurons).
NOTE: in case you're planning to fine-tune an already fine-tuned checkpoint, like facebook/convnext-tiny-224 (which has already been fine-tuned on ImageNet-1k), then you need to provide the additional argument ignore_mismatched_sizes=True to the from_pretrained method. This will make sure the output head (with 1000 output neurons) is thrown away and replaced by a new, randomly initialized classification head that includes a custom number of output neurons. You don't need to specify this argument in case the pre-trained model doesn't include a head.
The warning is telling us we are throwing away some weights (the weights and bias of the classifier layer) and randomly initializing some other (the weights and bias of a new classifier layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
Now we initialize our optimizer.
Note that most models on the Hub compute loss internally, so we actually don't have to specify anything there! Leaving the loss field blank will cause the model to read the loss head as its loss value.
This is an unusual quirk of TensorFlow models in 🤗 Transformers, so it's worth elaborating on in a little more detail. All 🤗 Transformers models are capable of computing an appropriate loss for their task internally (for example, a CausalLM model will use a cross-entropy loss). To do this, the labels must be provided in the input dict (or equivalently, in the columns argument to to_tf_dataset()), so that they are visible to the model during the forward pass.
This is quite different from the standard Keras way of handling losses, where labels are passed separately and not visible to the main body of the model, and loss is handled by a function that the user passes to compile(), which uses the model outputs and the label to compute a loss value.
The approach we take is that if the user does not pass a loss to compile(), the model will assume you want the internal loss. If you are doing this, you should make sure that the labels column(s) are included in the input dict or in the columns argument to to_tf_dataset.
If you want to use your own loss, that is of course possible too! If you do this, you should make sure your labels column(s) are passed like normal labels, either as the second argument to model.fit(), or in the label_cols argument to to_tf_dataset.
We need to convert our datasets to a format Keras understands. The easiest way to do this is with the to_tf_dataset() method. Note that our data collators are designed to work for multiple frameworks, so ensure you set the return_tensors='np' argument to get NumPy arrays out - you don't want to accidentally get a load of torch.Tensor objects in the middle of your nice TF code! You could also use return_tensors='tf' to get TensorFlow tensors, but our to_tf_dataset pipeline actually uses a NumPy loader internally, which is wrapped at the end with a tf.data.Dataset. As a result, np is usually more reliable and performant when you're using it!
train_set is now a tf.data.Dataset type object. We see that it contains two elements - labels and pixel_values (but not image) as a result of the preprocessing done in preprocess_train.
The last thing to define is how to compute the metrics from the predictions. We need to define a function for this, which will just use the metric we loaded earlier. The only preprocessing we have to do is to take the argmax of our predicted logits.
In addition, let's wrap this metric computation function in a KerasMetricCallback. This callback will compute the metric on the validation set each epoch, including printing it and logging it for other callbacks like TensorBoard and EarlyStopping.
Why do it this way, though, and not just use a straightforward Keras Metric object? This is a good question - on this task, metrics such as Accuracy are very straightforward, and it would probably make more sense to just use a Keras metric for those instead. However, we want to demonstrate the use of KerasMetricCallback here, because it can handle any arbitrary Python function for the metric computation.
Wow do we actually use KerasMetricCallback? We simply define a function that computes metrics given a tuple of numpy arrays of predictions and labels, then we pass that, along with the validation set to compute metrics on, to the callback:
Now we can train our model. We can also add a callback to sync up our model with the Hub - this allows us to resume training from other machines and even test the model's inference quality midway through training! Make sure to change the username if you do. If you don't want to do this, simply remove the callbacks argument in the call to fit().
Once the training is completed, we can evaluate our model and get its loss on the validation set like this:
Alternatively, we could also get the predictions from the model, and calculate metrics using the datasets.Metric object.
You can now share this model with all your friends, family, favorite pets: they can all load it with the identifier "your-username/the-name-you-picked" so for instance:
Inference
Let's say you have a new image, on which you'd like to make a prediction. Let's load a satellite image of a forest (that's not part of the EuroSAT dataset), and see how the model does.
We'll load the feature extractor and model from the hub (here, we use the Auto Classes, which will make sure the appropriate classes will be loaded automatically based on the config.json and preprocessor_config.json files of the repo on the hub):
Looks like our model got it correct!
Pipeline API
An alternative way to quickly perform inference with any model on the hub is by leveraging the Pipeline API, which abstracts away all the steps we did manually above for us. It will perform the preprocessing, forward pass and postprocessing all in a single object.
Note the configuration for feature_extractor will be pulled from the specified repo and used to build the feature_extractor in this pipeline.
Let's showcase this for our trained model:
As we can see, it does not only show the class label with the highest probability, but does return the top 5 labels, with their corresponding scores. Note that the pipelines also work with local models and feature extractors: