
Path: blob/master/examples/vision/ipynb/depth_estimation.ipynb
8147 views
Monocular depth estimation
Author: Victor Basu
Date created: 2021/08/30
Last modified: 2024/08/13
Description: Implement a depth estimation model with a convnet.
Introduction
Depth estimation is a crucial step towards inferring scene geometry from 2D images. The goal in monocular depth estimation is to predict the depth value of each pixel or inferring depth information, given only a single RGB image as input. This example will show an approach to build a depth estimation model with a convnet and simple loss functions.
Setup
Downloading the dataset
We will be using the dataset DIODE: A Dense Indoor and Outdoor Depth Dataset for this tutorial. However, we use the validation set generating training and evaluation subsets for our model. The reason we use the validation set rather than the training set of the original dataset is because the training set consists of 81GB of data, which is challenging to download compared to the validation set which is only 2.6GB. Other datasets that you could use are NYU-v2 and KITTI.
Preparing the dataset
We only use the indoor images to train our depth estimation model.
Preparing hyperparameters
Building a data pipeline
The pipeline takes a dataframe containing the path for the RGB images, as well as the depth and depth mask files.
It reads and resize the RGB images.
It reads the depth and depth mask files, process them to generate the depth map image and resize it.
It returns the RGB images and the depth map images for a batch.
Visualizing samples
3D point cloud visualization
Building the model
The basic model is from U-Net.
Addditive skip-connections are implemented in the downscaling block.
Defining the loss
We will optimize 3 losses in our mode.
Structural similarity index(SSIM).
L1-loss, or Point-wise depth in our case.
Depth smoothness loss.
Out of the three loss functions, SSIM contributes the most to improving model performance.
Model training
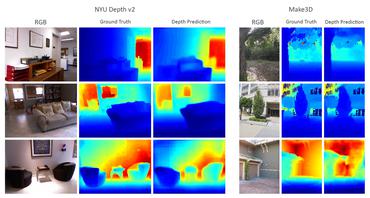
Visualizing model output
We visualize the model output over the validation set. The first image is the RGB image, the second image is the ground truth depth map image and the third one is the predicted depth map image.
Possible improvements
You can improve this model by replacing the encoding part of the U-Net with a pretrained DenseNet or ResNet.
Loss functions play an important role in solving this problem. Tuning the loss functions may yield significant improvement.
References
The following papers go deeper into possible approaches for depth estimation.
You can also find helpful implementations in the papers with code depth estimation task.
You can use the trained model hosted on Hugging Face Hub and try the demo on Hugging Face Spaces.