
Enhanced Deep Residual Networks for single-image super-resolution
Author: Gitesh Chawda
Date created: 2022/04/07
Last modified: 2024/08/27
Description: Training an EDSR model on the DIV2K Dataset.
Introduction
In this example, we implement Enhanced Deep Residual Networks for Single Image Super-Resolution (EDSR) by Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee.
The EDSR architecture is based on the SRResNet architecture and consists of multiple residual blocks. It uses constant scaling layers instead of batch normalization layers to produce consistent results (input and output have similar distributions, thus normalizing intermediate features may not be desirable). Instead of using a L2 loss (mean squared error), the authors employed an L1 loss (mean absolute error), which performs better empirically.
Our implementation only includes 16 residual blocks with 64 channels.
Alternatively, as shown in the Keras example Image Super-Resolution using an Efficient Sub-Pixel CNN, you can do super-resolution using an ESPCN Model. According to the survey paper, EDSR is one of the top-five best-performing super-resolution methods based on PSNR scores. However, it has more parameters and requires more computational power than other approaches. It has a PSNR value (≈34db) that is slightly higher than ESPCN (≈32db). As per the survey paper, EDSR performs better than ESPCN.
Paper: A comprehensive review of deep learning based single image super-resolution
Comparison Graph: 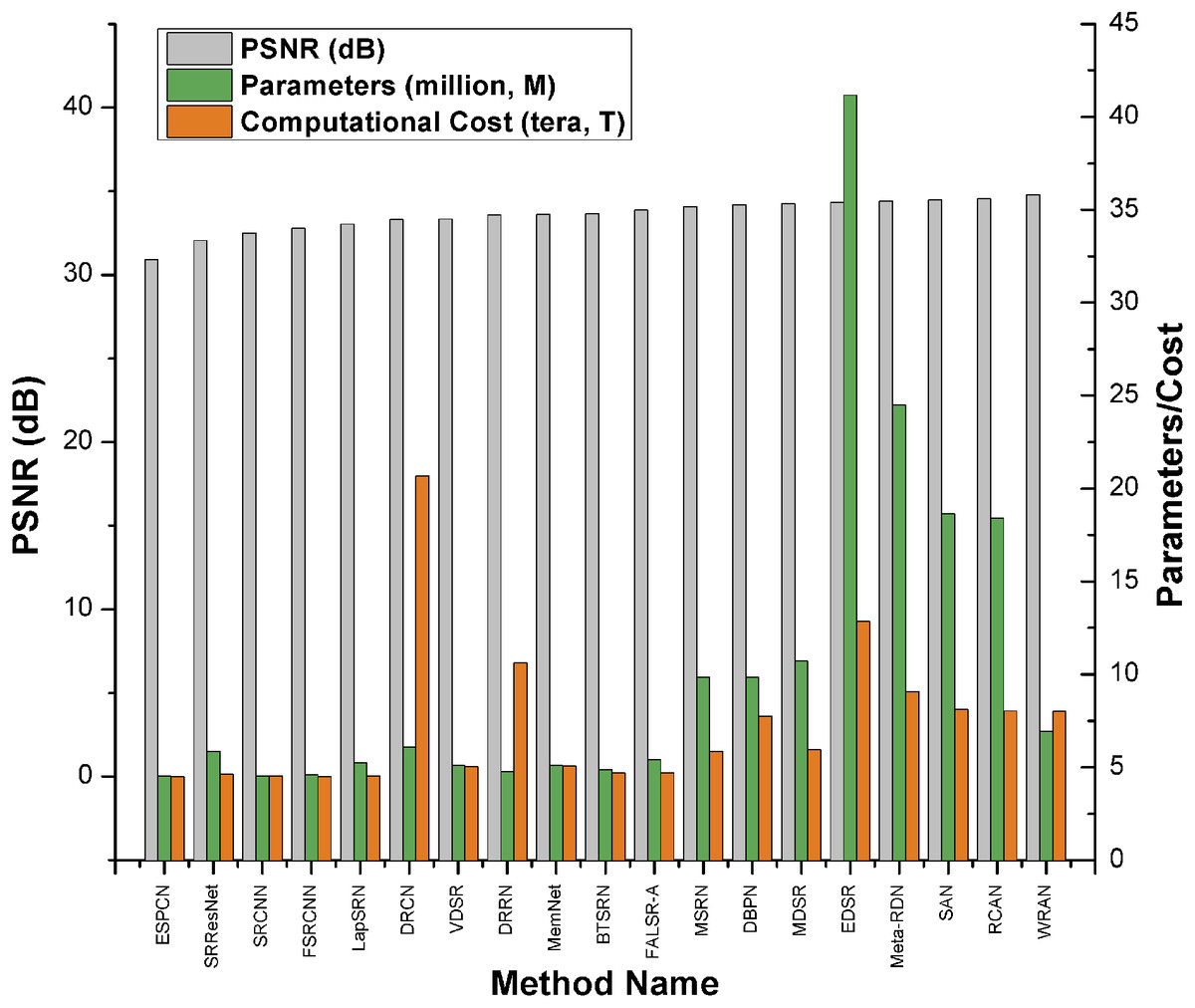
Imports
Download the training dataset
We use the DIV2K Dataset, a prominent single-image super-resolution dataset with 1,000 images of scenes with various sorts of degradations, divided into 800 images for training, 100 images for validation, and 100 images for testing. We use 4x bicubic downsampled images as our "low quality" reference.
Flip, crop and resize images
Prepare a tf.data.Dataset object
We augment the training data with random horizontal flips and 90 rotations.
As low resolution images, we use 24x24 RGB input patches.
Visualize the data
Let's visualize a few sample images:
Build the model
In the paper, the authors train three models: EDSR, MDSR, and a baseline model. In this code example, we only train the baseline model.
Comparison with model with three residual blocks
The residual block design of EDSR differs from that of ResNet. Batch normalization layers have been removed (together with the final ReLU activation): since batch normalization layers normalize the features, they hurt output value range flexibility. It is thus better to remove them. Further, it also helps reduce the amount of GPU RAM required by the model, since the batch normalization layers consume the same amount of memory as the preceding convolutional layers.
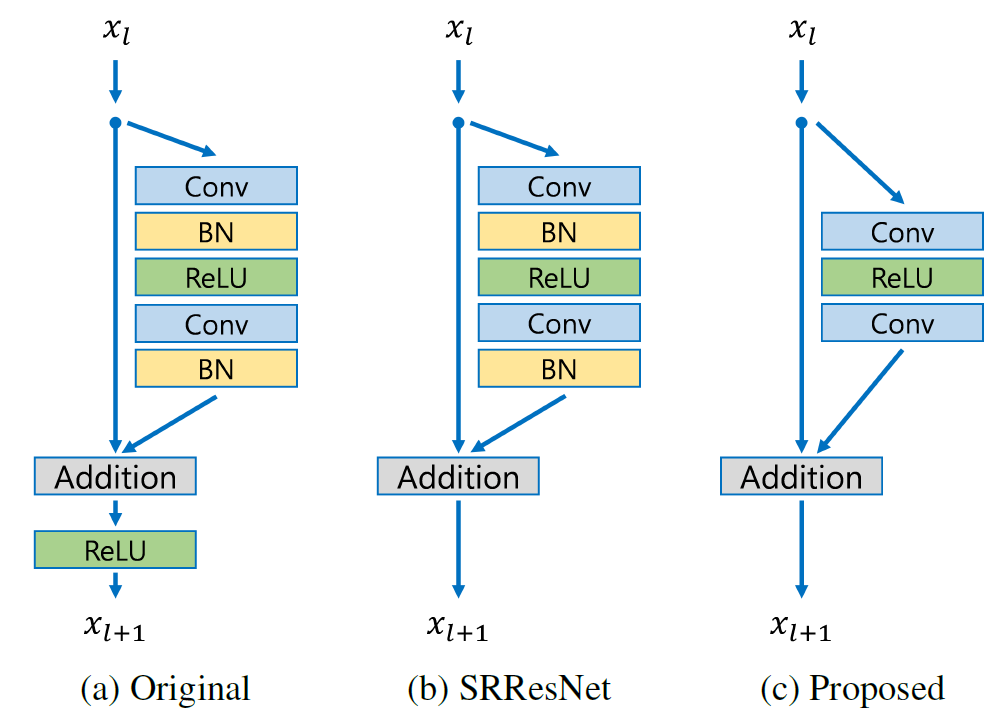
Train the model
Run inference on new images and plot the results
Final remarks
In this example, we implemented the EDSR model (Enhanced Deep Residual Networks for Single Image Super-Resolution). You could improve the model accuracy by training the model for more epochs, as well as training the model with a wider variety of inputs with mixed downgrading factors, so as to be able to handle a greater range of real-world images.
You could also improve on the given baseline EDSR model by implementing EDSR+, or MDSR( Multi-Scale super-resolution) and MDSR+, which were proposed in the same paper.