
Path: blob/main/notebooks/03/10-job-shop-scheduling.ipynb
759 views
Extra material: Job shop scheduling
Preamble: Install Pyomo and a solver
This cell selects and verifies a global SOLVER for the notebook.
If run on Google Colab, the cell installs Pyomo and HiGHS, then sets SOLVER to use the Highs solver via the appsi module. If run elsewhere, it assumes Pyomo and CBC have been previously installed and sets SOLVER to use the CBC solver via the Pyomo SolverFactory. It then verifies that SOLVER is available.
Job Shop Scheduling
Job shop scheduling is one of the classic problems in Operations Research.
A job shop refers to a collection of machines that process jobs. The jobs may be simple or complex, such as the production of a custom part, a print job at printing house, a patient treated in a hospital, or a meal produced in a fast food restaurant. The term "machines" can refer any device, person, or resource involved in the processing the jobs. In what follows in this notebook, a job comprises a series of tasks that requiring use of particular machines for known duration, and which must be completed in specified order.
The job shop scheduling problem is to schedule a set of jobs on the available machines to optimize a metric of productivity. A typical metric is the makespan which refers to the time needed to process all jobs.
At a basic level, the data required to specify a job shop scheduling problem consists of two tables. The first table is a decomposition of the jobs into a series of tasks, each task listing the job name, name of the required machine, and task duration. A second table list task pairs where the first task must be completed before the second task can be started.
Real applications of job shop scheduling often include additional considerations such as time that may be required to set up machines prior to the start of the next job, or limits on the time a job can wait between processing steps.
Job shop example
The following example of a job shop is from Chapter 7 of the book by Christelle Guéret, Christian Prins, Marc Sevaux titled Applications of Optimization with Xpress-MP (Dash Optimization, 2000).
In this example, there are three printed paper products that must pass through color printing presses in a particular order. The given data consists of a flow sheet showing the order in which each job passes through the color presses
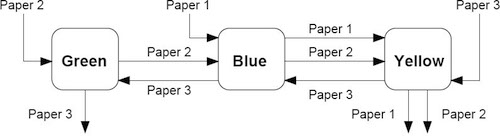
and a table of data showing, in minutes, the amount of time each job requires on each machine.
| Machine | Color | Paper 1 | Paper 2 | Paper 3 |
|---|---|---|---|---|
| 1 | Blue | 45 | 20 | 12 |
| 2 | Green | - | 10 | 17 |
| 3 | Yellow | 10 | 34 | 28 |
What is the minimum amount of time (i.e, what is the makespan) for this set of jobs?
Task decomposition
The first step in the analysis is to decompose the process into a series of tasks. Each task c(job, machine) pair. Some tasks cannot start until a prerequisite task is completed.
| Task (Job,Machine) | Duration | Prerequisite Task |
|---|---|---|
| (Paper 1, Blue) | 45 | - |
| (Paper 1, Yellow) | 10 | (Paper 1,Blue) |
| (Paper 2, Blue) | 20 | (Paper 2, Green) |
| (Paper 2, Green) | 10 | - |
| (Paper 2, Yellow) | 34 | (Paper 2, Blue) |
| (Paper 3, Blue) | 12 | (Paper 3, Yellow) |
| (Paper 3, Green) | 17 | (Paper 3, Blue) |
| (Paper 3, Yellow) | 28 | - |
We convert this to a JSON style representation where tasks are denoted by (Job,Machine) tuples in Python. The task data is stored in a Python dictionary indexed by (Job,Machine) tuples. The task data consists of a dictionary with duration ('dur') and (Job,Machine) pair for any prerequisite task.
Model formulation
Each task is indexed by an ordered pair where refers to a job, and refers to a machine. Associated with each task is data describing the time needed to perform the task, and a preceding task that must be completed before the index task can start.
| Parameter | Description |
|---|---|
| Duration of task | |
| A task that must be completed before task |
The choice of decision variables for this problem are key to modeling. We introduce as the time needed to complete all tasks. is a candidate objective function. Variable denotes the time when task begins.
| Decision Variables | Description |
|---|---|
| Completion of all jobs | |
| Start time for task |
The constraints include lower bounds on the start and an upper bound on the completion of each task
Any preceding tasks must be completed before task can start.
Finally, for every task performed on machine , there can be no overlap among those tasks. This leads to a set of pair-wise disjunctive constraints for each machine.
avoids conflicts for use of the same machine.
Pyomo implementation
The job shop scheduling problem is implemented below in Pyomo. The implementation consists of of a function JobShopModel(TASKS) that accepts a dictionary of tasks and returns a Pyomo model.
Printing schedules
Visualizing Results with Gantt Charts

Application to the scheduling of batch processes
We will now turn our attention to the application of the job shop scheduling problem to the short term scheduling of batch processes. We illustrate these techniques using Example II from Dunn (2013).
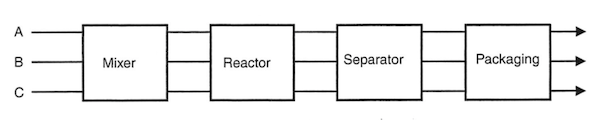
| Recipe | Mixer | Reactor | Separator | Packaging |
|---|---|---|---|---|
| A | 1.0 | 5.0 | 4.0 | 1.5 |
| B | - | - | 4.5 | 1.0 |
| C | - | 3.0 | 5.0 | 1.5 |
Single product strategies
Before going further, we create a function to streamline the generation of the TASKS dictionary.



Multiple Overlapping tasks
Let's now consider an optimal scheduling problem where we are wish to make two batches of Product A.

Earlier we found that it took 11.5 hours to produce one batch of product A. As we see here, we can produce a second batch with only 5.0 additional hours because some of the tasks overlap. The overlapping of tasks is the key to gaining efficiency in batch processing facilities.
Let's next consider production of a single batch each of products A, B, and C.

The individual production of A, B, and C required 11.5, 5.5, and 9.5 hours, respectively, for a total of 25.5 hours. As we see here, by scheduling the production simultaneously, we can get all three batches done in just 15 hours.
As we see below, each additional set of three products takes an additional 13 hours. So there is considerable efficiency gained by scheduling over longer intervals whenever possible.

Adding time for unit clean out
A common feature of batch unit operations is a requirement that equipment be cleaned prior to reuse.
In most cases the time needed for clean out would be specific to the equipment and product. But for the purposes this notebook, we implement can implement a simple clean out policy with a single non-negative parameter which, if specified, requires a period no less than between the finish of one task and the start of another on every piece of equipment.
This policy is implemented by modifying the usual disjunctive constraints to avoid machine conflicts to read
For this purpose, we write a new JobShopModel_Clean

Adding a zero wait policy
One of the issues in the use of job shop scheduling for chemical process operations are situations where there it is not possible to store intermediate materials. If there is no way to store intermediates, either in the processing equipment or in external vessels, then a zero-wait policy may be required.
A zero-wait policy requires subsequent processing machines to be available immediately upon completion of any task. To implement this policy, the usual precident sequencing constraint of a job shop scheduling problem, i.e.,
is changed to
if the zero-wait policy is in effect.
While this could be implemented on an equipment or product specific basis, here we add an optional ZW flag to the JobShop function that, by default, is set to False.

References
Applegate, David, and William Cook. "A computational study of the job-shop scheduling problem." ORSA Journal on computing 3, no. 2 (1991): 149-156. pdf available
Beasley, John E. "OR-Library: distributing test problems by electronic mail." Journal of the operational research society 41, no. 11 (1990): 1069-1072. OR-Library
Guéret, Christelle, Christian Prins, and Marc Sevaux. "Applications of optimization with Xpress-MP." contract (1999): 00034.
Manne, Alan S. "On the job-shop scheduling problem." Operations Research 8, no. 2 (1960): 219-223.
Exercises
Task specific cleanout
Clean out operations are often slow and time consuming. Further more, the time required to perform a clean out frequently depends on the type of machine, and the task performed by the machine. For this exercise, create a data format to include task-specific clean out times, and model the job shop model to accommodate this additional information.
Computational impact of a zero-wait policy
Repeat the benchmark problem calculation, but with a zero-wait policy. Does the execution time increase or descrease as a consequence of specifying zero-wait?