
![]()
Pandas
From http://pandas.pydata.org/pandas-docs/stable/
pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
See also:
Good and practice books about Pandas possibilities are:
Python for Data Analysis
Data Wrangling with Pandas, NumPy, and IPython
By William McKinney
This other is about aplications based on Pandas:  Introduction to Machine Learning with Python
Introduction to Machine Learning with Python
A Guide for Data Scientists By Sarah Guido, Andreas Müller
Pandas can be used in a similar way to R, which is based on similar data structures. Pandas also can replace the use of graphical interfaces to access spreadsheets like Excel. In particular, can be used in joint with the module xlsxwriter to produce professional Excel spreadsheets at the programatical level.
The similar data structure in Wolfram Alpha and Mathematica is the Dataset, in C++ is the ROOT framework, and in the old Fortran 77 was paw. In this way, a dictionary of equivalent commands can be stablished between the several frameworks
Standard way to load the module
Introduction
We already saw how NumPy arrays can improve the analysis of numerical data. For heterogeneous data the recommended tool are Pandas dataframes.
Heterogeneous and nested data can be stored as list of dictionaries. For example, for people with names, birth date, sex, and a job list with start and end date, we can have
We can create a DataFrame from the list of dictionaries
As with NumPy, we can create masks in order to filter out specific rows of the dataframe. For example, to filter out the female persons by using the syntax:
To filter out the last job of each person by using the following code (.get is a safer way to obtain the value of the key of a dictionary)
Basic structure: DataFrame
An flat spreadsheet can be seen in terms of the types of variables of Python just as dictionary of lists, where each column of the spreadsheet is a pair key-list of the dictionary
| A | B | |
|---|---|---|
| 1 | even | odd |
| 2 | 0 | 1 |
| 3 | 2 | 3 |
| 4 | 4 | 5 |
| 5 | 6 | 7 |
| 6 | 8 | 9 |
Data structures
Pandas has two new data structures:
DataFramewhich are similar to numpy arrays but with some assigned key. For example, for the previous case
Serieswhich are enriched to dictionaries, as the ones defined for the rows of the previous example:{'even':0,'odd':1}.
The rows in a two-dimensional DataFrame corresponds to Series with similar keys, while the columns are also Series with the indices as keys.
An example of a DataFrame is a spreadsheet, as the one before.
DataFrame
Pandas can convert a dictionary of lists, like the numbers dictionary before, into a DataFrame, which is just an spreadsheet but interpreted at the programming level:

See below for other possibilities of creating Pandas DataFrames from lists and dictionaries
The main advantage of the DataFrame,df, upon a spreadsheet, is that it can be managed just at the programming level without any graphical interface.
We can check the shape of the DataFrame
Export DataFrame to other formats
To export to excel:
Activity: Open the resulting spreadsheet in Google Drive, publish it and open from the resulting link with Pandas in the next cell
Series
Each column of the DataFrame is now an augmented dictionary called Series, with the indices as the keys of the Series
A Pandas Series object can be just initialized from a Python dictionary:
The keys are the index of the DataFrame
Each row is also a series
with keys: 'even' and 'odd'
or as a filter
or attributes even and odd
One specific cell value can be reached with the index and the key:
A Pandas Series object can be just initialized from a Python dictionary:
but also as containers of name spaces!
The power of Pandas rely in that their main data structures:
DataFramesandSeries, are enriched with many useful methods and attributes.
Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
"relational": the list of data is identified with some unique index (like a
SQLtable)"labeled": the list is identified with a key, like the previous
oddorevenkeys.
For example. A double bracket [[...]], can be used to filter data.
A row in a two-dimensional DataFrame corresponds to Series with the same keys of the DataFrame, but with single values instead of a list
To filter a column:
DataFrame initialization
Initialization from an existing spreadsheet.
This can be locally in your computer o from some downloadable link
To make a downloadable link for any spread sheet in Google Drive, follow the sequence:
After some modification
it can be saved again as an excel file with the option to not create a column of indices: index=False
Initialization from lists and dictionaries
Inizialization from Series
We start with an empty DataFrame:
Creating Pandas DataFrame from list and dictionaries offers many alternatives
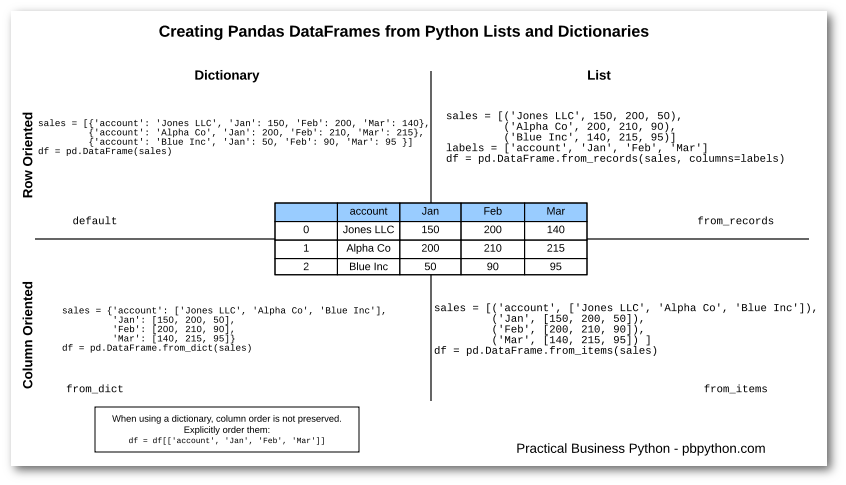
Column oriented way
In addition to the dictionary of lists already illustrated at the beginning that in this case corresponds to:
We can obtain the DataFrame from list of items
We can obtain the
DataFramefrom dictionary
Special DataFrames
Empty DataFrame
Single row DataFrame from dictionary
Initialization from sequential rows as Series
We start with an empty DataFrame:
We can append a dictionary (or Series) as a row of the DataFrame, provided that we always use the option: ignore_index=True
To add a second file we build another dict
{"name":"stdin","output_type":"stream","text":"Name:\n Diego Restrepo\nNacionality:\n Colombia\nAge:\n 51\nCompany:\n UdeA\n"}To concatenate a list of dataframes side by side use the option axis='columns'
Exercises
Display the resulting
Seriesin the screen:
Activity: Append a new row to the previous DataFrame and visualize it:
Fill NaN with empty strings
Save
PandasDataFrameas an Excel file
Load pandas DataFrame from the saved file in Excel
Other formats to saving and read files
We are interested in format which keeps the tags of the columns, like 'Nombre', 'Edad', 'Compañia'
CSV
Comma separated values
We can check the explicit file format with
JSON
This format keeps the Python lists and dictionaries at the storage level
This format allow us to keep exactly the very same list of dictionaries structure!
Activity:
Save to a file instead of
Noneand open the file with some editor.
Add a break-line at the end of the first dictionary and try to load the resulting file with
pd.read_json
JSON allows for some flexibility in the break-lines structure:
For large databases it is convinient just to accumulate dictionaries in a sequential form:
Activity:
Save to a file instead of
None, with options:orient='records',lines=True, and open the file with some editor.
Add a similar dictionary in the next new line, and try to load the resulting file with
pd.read_jsonwith options:orient='records',lines=True.WARNING: Use doble-quotes
"to write the keys od the new dictionary
Any Python string need to be converted first to double-quotes before to be used as JSON string.
Example
This string can be writing in the JSON format by replacing the single quotes, ' , by duoble quotes, ":
and now can be used as an JSON input
Activity: Try to read the string as JSON without make the double-quote replacement
Common operations upon DataFrames
To fill a specific cell
Filters (masking)
The main application of labeled data for data analysis is the possibility to make filers, or cuts, to obtain specific reduced datasets to further analysis
A mask is a list of True/False values
and → &
negation → ~
or → |
The apply method
The advantage of the spreadsheet paradigm is that the columns can be transformed with functions. All the typical functions avalaible for a spreadsheet are already implemented like the method .abs() used before, or the method: .sum()
Activity: Explore the avalaible methods by using the completion system of the notebook after the last semicolon of df.even.
df['even'].ipynb_checkpoints/
Column-level apply
We just select the column and apply the direct or implicit function:
Pre-defined function
Implicit function
Row-level apply
The foll row is passed as dictionary to the explicit or implicit function when apply is used for the full DataFrame and the option axis=1 is used at the end
Chain tools for data analysis
There are several chain tools for data analyis like the
Spreadsheet based one, like Excel
Relational databases with the use of more advanced SQL tabular data with some data base software like MySQL
Non-relational databases (RAM) with Pandas, R, Paw,... ( max ~ RAM/8)
Non-relational databases (Disk): Dask, ROOT, MongoDB,...
Here we illustrate an example of use fo a non-relational database with Pandas
Relational databases

Example
Obtain the current work of Álvaro Uribe Vélez
It is convenient to normalize the columns with strings before to tray to search inside them with a DataFrame method like .
Non-relational databases
Nested lists of dictionaries with a defined data scheme

Extract-Transform-Load: ETL
Actividad
Obtenga el último trabajo de Álvaro Uribe Vélez
We have shown that the simple two dimensional spreadsheets where each cell values is a simple type like string, integer, or float, can be represented as a dictionary of lists values or a list of dictionary column-value assignment.
We can go further and allow to store in the value itself a more general data structure, like nested lists and dictionaries. This allows advanced data-analysis when the apply methos is used to operate inside the nested lists or dictionaries.
See for example:
World wide web
There are really three kinds of web
The normal web,
The deep web,
The machine web. The web for machine readable responses. It is served in
JSONorXMLformats, which preserve programming objects.
Normal web
Real world example: microsoft academics 
Machine web
For example, consider the following normal web page:
https://inspirehep.net/literature?q=doi:10.1103/PhysRevLett.122.132001
about a Scientific paper with people from the University of Antioquia. A machine web version can be easily obtained in JSON just by attaching the extra parameter &of=recjson, and direcly loaded from Pandas, which works like a browser for the third web:
We can use all the previous methods to extract the authors from 'Antioquia U.':
Note: For a dictionary, d is safer to use d.get('key') instead of just d['key'] to obtain some key, because not error is generated if the requested key does not exists at all
or
We can see that the column authors is quite nested: Is a list of dictionaries with the full information for each one of the authors of the article.
Activity: Check that the lenght of the auhors list coincides with the number_of_authors
For further details see: https://github.com/restrepo/inspire/blob/master/gfif.ipynb
Activity: Repeat the same activity but using directly the JSON file, obtained with requests
Summary
Final remarks
With basic scripting and Pandas we already have a solid environment to analyse data. We introduce the other libraries motivated with the extending the capabilities of Pandas