
Path: blob/master/Data Analysis using Python/Titanic EDA(final).ipynb
4740 views
Learning EDA from Historic Diaster "The Titanic Wreck"

Table of Contents
Data Profiling & Preprocessing
3.1 Pre Profiling
3.2 Preprocessing
3.3 Post Profiling
Objective
The objective here is to conduct Exploratory data analysis (EDA) on the Titanic Dataset in order to gather insights and evenutally predicting survior on basics of factors like Class ,Sex , Age , Gender ,Pclass etc.
Why EDA?
An approach to summarize, visualize, and become intimately familiar with the important characteristics of a data set.
Defines and Refines the selection of feature variables that will be used for machine learning.
Helps to find hidden Insights
It provides the context needed to develop an appropriate model with minimum errors
About Event
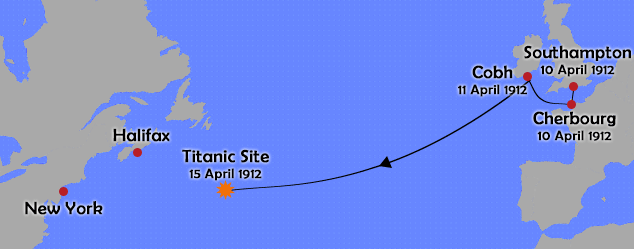
The RMS Titanic was a British passenger liner that sank in the North Atlantic Ocean in the early morning hours of 15 April 1912, after it collided with an iceberg during its maiden voyage from Southampton to New York City. There were an estimated 2,224 passengers and crew aboard the ship, and more than 1,500 died, making it one of the deadliest commercial peacetime maritime disasters in modern history. This sensational tragedy shocked the international community and led to better safety regulations for ships.
2. Data Description
The dataset consists of the information about people boarding the famous RMS Titanic. Various variables present in the dataset includes data of age, sex, fare, ticket etc. The dataset comprises of 891 observations of 12 columns. Below is a table showing names of all the columns and their description.
| Column Name | Description | | ------------- |:------------- 😐 | PassengerId | Passenger Identity | | Survived | Survival (0 = No; 1 = Yes) | | Pclass | Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd) | | Name | Name of passenger | | Sex | Sex of passenger | | Age | Age of passenger | | SibSp | Number of sibling and/or spouse travelling with passenger | | Parch | Number of parent and/or children travelling with passenger| | Ticket | Ticket number | | Fare | Price of ticket | | Cabin | Cabin number | |Embarkment | Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton)|
Importing Data
Examining Data
Insights:
1.Total samples are 891 or 40% of the actual number of passengers on board the Titanic (2,224)
2.Survived is a categorical feature with 0 or 1 values
3.Around 38% samples survived representative of the actual survival rate at 32%
4.Fares varied significantly with few passengers (<1%) paying as high as $512.
5.Few elderly passengers (<1%) within age range 65-80.
Data Profiling
By pandas profiling, an interactive HTML report gets generated which contains all the information about the columns of the dataset, like the counts and type of each column.
1.Detailed information about each column, coorelation between different columns and a sample of dataset
2.It gives us visual interpretation of each column in the data
3.Spread of the data can be better understood by the distribution plot
4.Grannular level analysis of each column.
Data Preprocessing
Check for Errors and Null Values
Replace Null Values with appropriate values
Drop down features that are incomplete and are not too relevant for analysis
Create new features that can would help to improve prediction
Check for null or empty values in Data
The Age, Cabin and Embarked have null values.Lets fix them
Filling missing age by median
Filling missing Embarked by mode
Cabin feature may be dropped as it is highly incomplete or contains many null values
PassengerId Feature may be dropped from training dataset as it does not contribute to survival
Ticket feature may be dropped down
Creating New Fields
Create New Age Bands to improve prediction Insights
Create a new feature called Family based on Parch and SibSp to get total count of family members on board
Create a Fare range feature if it helps our analysis
AGE-BAND
Fare-Band
We want to analyze if Name feature can be engineered to extract titles and test correlation between titles and survival, before dropping Name and PassengerId features.
In the following code we extract Title feature using regular expressions. The RegEx pattern (\w+.) matches the first word which ends with a dot character within Name feature. The expand=False flag returns a DataFrame.
We can replace many titles with a more common name or classify them as Rare.
We can convert the categorical titles to ordinal.
Insights
Most titles band Age groups accurately. For example: Master title has Age mean of 5 years.
Survival among Title Age bands varies slightly.
Certain titles mostly survived (Mme, Lady, Sir) or did not (Don, Rev, Jonkheer).
Decision
We decide to retain the new Title feature for model training
Now we can convert features which contain strings to numerical values. This is required by most model algorithms. Doing so will also help us in achieving the feature completing goal.
Converting Sex feature to a new feature called Gender where female=1 and male=0.
Extracting Titles Now we can drop down Name feature
We can also create an artificial feature combining Pclass and Age.
Post Pandas Profiling : Checking Data after data preparation
Data Visualization
4.1 What is Total Count of Survivals and Victims?

Insights
Only 342 Passengers Survived out of 891
Majority Died which conveys there were less chances of Survival
4.2 Which gender has more survival rate?


Insights
Female has better chances of Survival "LADIES FIRST"
There were more males as compared to females ,but most of them died.
4.3 What is Survival rate based on Person type?

------------------------------------------ADULT-SURVIVAL RATE--------------------------------------------------------------

------------------------------------------CHILD-SURVIVAL RATE--------------------------------------------------------------

Insights
Majority Passengers were Adults
Almost half of the total number of children survived.
Most of the Adults failed to Survive
More than 85percent of Infant Survived
4.4 Did Economy Class had an impact on survival rate?


Insights
Most of the passengers travelled in Third class but only 24per of them survived
If we talk about survival ,more passengers in First class survived and again female given more priority
Economic Class affected Survival rate and Passengers travelling with First Class had higher ratio of survival as compared to Class 2 and 3.
4.5 What is Survival Propability based on Embarkment of passengers?
Titanic’s first voyage was to New York before sailing to the Atlantic Ocean it picked passengers from three ports Cherbourg(C), Queenstown(Q), Southampton(S). Most of the Passengers in Titanicic embarked from the port of Southampton.Lets see how embarkemt affected survival probability.


Gender Survival based on Embarkment and Pclass


Insights:
Most Passengers from port C Survived.
Most Passengers were from Southampton(S).
Exception in Embarked=C where males had higher survival rate. This could be a correlation between Pclass and Embarked and in turn Pclass and Survived, not necessarily direct correlation between Embarked and Survived.
Males had better survival rate in Port C when compared for S and Q ports.
Females had least Survival rate in Pclass 3
4.6 How is Fare distributed for Passesngers?

Insights
Majority Passenger's fare lies in 0-100 dollars range
Passengers who paid more Fares had more chances of Survival
Fare as high as 514 dollars was purcharsed by very few.(Outlier)
4.7 What was Average fare by Pclass & Embark location?


Insights
First Class Passengers paid major part of total Fare.
Passengers who Embarked from Port C paid Highest Fare
4.8 Segment Age in bins with size of 10

Insights:
The youngest passenger on the Titanic were toddlers under 6 months
The oldest were of 80 years of age.
The mean for passengers was a bit over 29 years i.e there were more young passengers in the ship.
Lets see how Age has correlation with Survival



Insights
Most of the passengers died.
Majority of passengers were between 25-40,most of them died
Female are more likely to survival
4.9 Did Solo Passenger has less chances of Survival ?



Insights
Most of the Passengers were travelling Solo and most of them died
Solo Females were more likely to Survive as compared to males
Passengers Class have a positive correlation with Solo Passenger Survival
Passengers Embarked from Port Q had Fifty -Fifty Chances of Survival
4.10 How did total family size affected Survival Count?

Insights
Both men and women had a massive drop of survival with a FamilySize over 4.
The chance to survive as a man increased with FamilySize until a size of 4
Men are not likely to Survive with FamilySize 5 and 6
Big Size Family less likihood of Survival
4.11 How can you correlate Pclass/Age/Fare with Survival rate?

Insights:
Fare and Survival has positive correlation
We cannt relate age and Survival as majority of travellers were of mid age
Higher Class Passengers had more likeihood of Survival
4.12 Which features had most impact on Survival rate?

Insights:
Older women have higher rate of survival than older men . Also, older women has higher rate of survival than younger women; an opposite trend to the one for the male passengers.
All the features are not necessary to predict Survival
More Features creates Complexitity
Fare has positive Correlation
For Females major Survival Chances , only for port C males had more likeihood of Survival.
Conclusion : "If you were young female travelling in First Class and embarked from port -C then you have best chances of Survival in Titanic"
Most of the Passengers Died
"Ladies & Children First" i.e 76% of Females and 16% of Children Survived
Gender , Passenger type & Classs are mostly realted to Survival.
Survival rate diminishes significantly for Solo Passengers
Majority of Male Died
Males with Family had better Survival rate as compared to Solo Males
Part -2
Machine Learning
Importing Machine Learning Packages
Analyze by pivoting features¶
To confirm some of our observations and assumptions, we can quickly analyze our feature correlations by pivoting features against each other. We can only do so at this stage for features which do not have any empty values. It also makes sense doing so only for features which are categorical (Sex), ordinal (Pclass) or discrete (SibSp, Parch) type.
Pclass: We observe significant correlation (>0.5) among Pclass=1 and Survived (classifying #3). We decide to include this feature in our model.
Sex :We confirm the observation during problem definition that Sex=female had very high survival rate at 74% (classifying #1).
SibSp and Parch : These features have zero correlation for certain values. It may be best to derive a feature or a set of features from these individual features (creating #1).
Observations form EDA on Categorical Features
Female passengers had much better survival rate than males. Classifying .
Exception in Embarked=C where males had higher survival rate. This could be a correlation between Pclass and Embarked and in turn Pclass and Survived, not necessarily direct correlation between Embarked and Survived.
Males had better survival rate in Pclass=3 when compared with Pclass=2 for C and Q ports.Correlatring
Ports of embarkation have varying survival rates for Pclass=3 and among male passengers. Correlating.
Decisions.
Add Sex feature to model training.
Complete and add Embarked feature to model training.
There are 60+ predictive modelling algorithms to choose from. We must understand the type of problem and solution requirement to narrow down to a select few models which we can evaluate. Here our problem is a classification and regression problem.
Lets identify relationship between output (Survived or not) with other variables or features (Gender, Age, Port) and perform a category of machine learning which is called supervised learning
1. Logistic Regression
Logistic regression is a statistical method for analyzing a dataset in which there are one or more independent variables that determine an outcome.
Logistic Regression is used when the dependent variable(target) is categorical.
Logistic regression measures the relationship between the categorical dependent variable (feature) and one or more independent variables (features) by estimating probabilities using a logistic function, which is the cumulative logistic distribution.
We can use Logistic Regression to validate our assumptions and decisions for feature creating and completing goals. This can be done by calculating the coefficient of the features in the decision function.
Positive coefficients increase the log-odds of the response (and thus increase the probability), and negative coefficients decrease the log-odds of the response (and thus decrease the probability).
Insights
Sex is highest positivie coefficient, implying as the Sex value increases (male: 0 to female: 1), the probability of Survived=1 increases the most.
Inversely as Pclass increases, probability of Survived=1 decreases the most.
This way Age*Class is a good artificial feature to model as it has second highest negative correlation with Survived.
So is Title as second highest positive correlation.
Support Vector Machines(SVM)
Support-vector machines also support-vector networks) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis.
k-Nearest Neighbors algorithm
In pattern recognition, the k-Nearest Neighbors algorithm (or k-NN for short) is a non-parametric method used for classification and regression. A sample is classified by a majority vote of its neighbors, with the sample being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
Naive Bayes
Naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes' theorem with strong (naive) independence assumptions between the features. Naive Bayes classifiers are highly scalable, requiring a number of parameters linear in the number of variables (features) in a learning problem.
The model generated confidence score is the lowest among the models evaluated so far.
Perceptron
The perceptron is an algorithm for supervised learning of binary classifiers (functions that can decide whether an input, represented by a vector of numbers, belongs to some specific class or not). It is a type of linear classifier, i.e. a classification algorithm that makes its predictions based on a linear predictor function combining a set of weights with the feature vector. The algorithm allows for online learning, in that it processes elements in the training set one at a time.