
Path: blob/master/site/en-snapshot/hub/tutorials/movinet.ipynb
39067 views
Copyright 2021 The TensorFlow Hub Authors.
Licensed under the Apache License, Version 2.0 (the "License");
MoViNet for streaming action recognition
 View on GitHub
View on GitHubThis tutorial demonstrates how to use a pretrained video classification model to classify an activity (such as dancing, swimming, biking etc) in the given video.
The model architecture used in this tutorial is called MoViNet (Mobile Video Networks). MoVieNets are a family of efficient video classification models trained on huge dataset (Kinetics 600).
In contrast to the i3d models available on TF Hub, MoViNets also support frame-by-frame inference on streaming video.
The pretrained models are available from TF Hub. The TF Hub collection also includes quantized models optimized for TFLite.
The source for these models is available in the TensorFlow Model Garden. This includes a longer version of this tutorial that also covers building and fine-tuning a MoViNet model.
This MoViNet tutorial is part of a series of TensorFlow video tutorials. Here are the other three tutorials:
Load video data: This tutorial explains how to load and preprocess video data into a TensorFlow dataset pipeline from scratch.
Build a 3D CNN model for video classification. Note that this tutorial uses a (2+1)D CNN that decomposes the spatial and temporal aspects of 3D data; if you are using volumetric data such as an MRI scan, consider using a 3D CNN instead of a (2+1)D CNN.
Transfer learning for video classification with MoViNet: This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.
Setup
For inference on smaller models (A0-A2), CPU is sufficient for this Colab.
Get the kinetics 600 label list, and print the first few labels:
To provide a simple example video for classification, we can load a short gif of jumping jacks being performed.

Attribution: Footage shared by Coach Bobby Bluford on YouTube under the CC-BY license.
Download the gif.
Define a function to read a gif file into a tf.Tensor:
The video's shape is (frames, height, width, colors)
How to use the model
This section contains a walkthrough showing how to use the models from TensorFlow Hub. If you just want to see the models in action, skip to the next section.
There are two versions of each model: base and streaming.
The
baseversion takes a video as input, and returns the probabilities averaged over the frames.The
streamingversion takes a video frame and an RNN state as input, and returns the predictions for that frame, and the new RNN state.
The base model
Download the pretrained model from TensorFlow Hub.
This version of the model has one signature. It takes an image argument which is a tf.float32 with shape (batch, frames, height, width, colors). It returns a dictionary containing one output: A tf.float32 tensor of logits with shape (batch, classes).
To run this signature on the video you need to add the outer batch dimension to the video first.
Define a get_top_k function that packages the above output processing for later.
Convert the logits to probabilities, and look up the top 5 classes for the video. The model confirms that the video is probably of jumping jacks.
The streaming model
The previous section used a model that runs over a whole video. Often when processing a video you don't want a single prediction at the end, you want to update predictions frame by frame. The stream versions of the model allow you to do this.
Load the stream version of the model.
Using this model is slightly more complex than the base model. You have to keep track of the internal state of the model's RNNs.
The init_states signature takes the video's shape (batch, frames, height, width, colors) as input, and returns a large dictionary of tensors containing the initial RNN states:
Once you have the initial state for the RNNs, you can pass the state and a video frame as input (keeping the (batch, frames, height, width, colors) shape for the video frame). The model returns a (logits, state) pair.
After just seeing the first frame, the model is not convinced that the video is of "jumping jacks":
If you run the model in a loop, passing the updated state with each frame, the model quickly converges to the correct result:
You may notice that the final probability is much more certain than in the previous section where you ran the base model. The base model returns an average of the predictions over the frames.
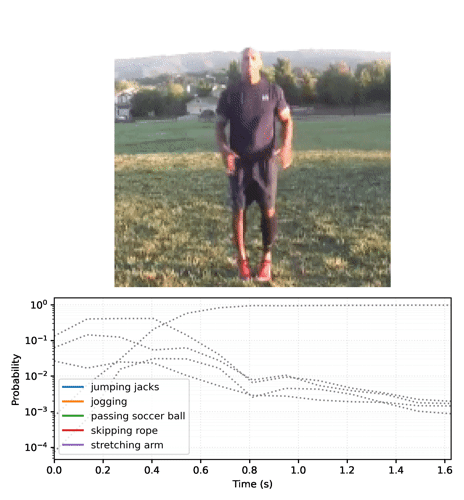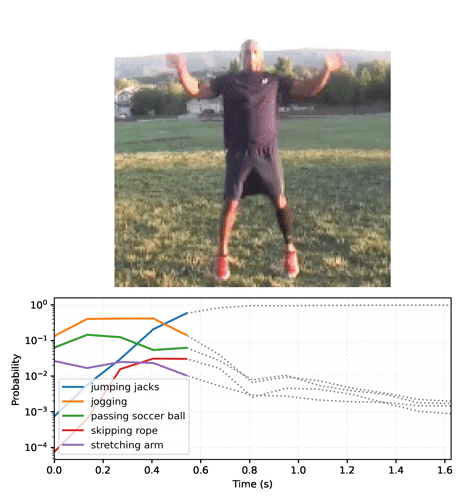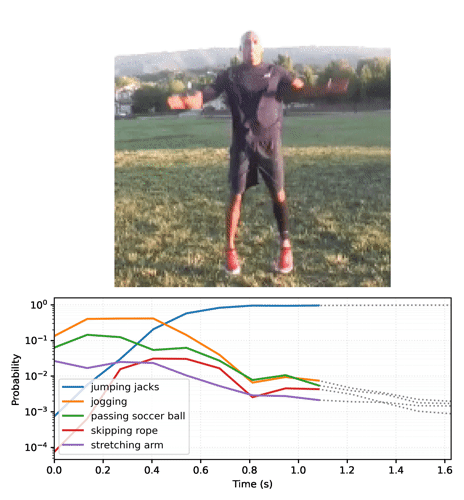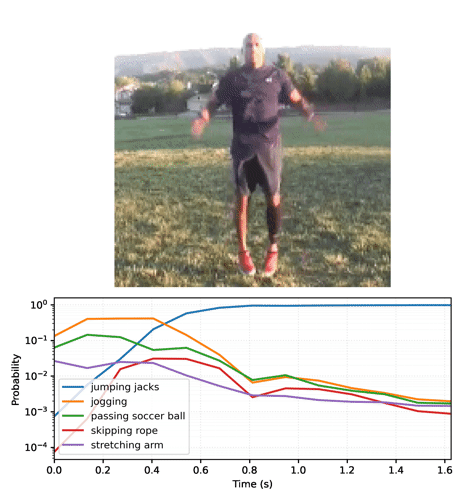
Animate the predictions over time
The previous section went into some details about how to use these models. This section builds on top of that to produce some nice inference animations.
The hidden cell below to defines helper functions used in this section.
Start by running the streaming model across the frames of the video, and collecting the logits:
Convert the sequence of probabilities into a video:
Resources
The pretrained models are available from TF Hub. The TF Hub collection also includes quantized models optimized for TFLite.
The source for these models is available in the TensorFlow Model Garden. This includes a longer version of this tutorial that also covers building and fine-tuning a MoViNet model.
Next Steps
To learn more about working with video data in TensorFlow, check out the following tutorials: