
Path: blob/master/site/en-snapshot/tutorials/load_data/video.ipynb
38548 views
Copyright 2022 The TensorFlow Authors.
Load video data
 View source on GitHub
View source on GitHubThis tutorial demonstrates how to load and preprocess AVI video data using the UCF101 human action dataset. Once you have preprocessed the data, it can be used for such tasks as video classification/recognition, captioning or clustering. The original dataset contains realistic action videos collected from YouTube with 101 categories, including playing cello, brushing teeth, and applying eye makeup. You will learn how to:
Load the data from a zip file.
Read sequences of frames out of the video files.
Visualize the video data.
Wrap the frame-generator
tf.data.Dataset.
This video loading and preprocessing tutorial is the first part in a series of TensorFlow video tutorials. Here are the other three tutorials:
Build a 3D CNN model for video classification: Note that this tutorial uses a (2+1)D CNN that decomposes the spatial and temporal aspects of 3D data; if you are using volumetric data such as an MRI scan, consider using a 3D CNN instead of a (2+1)D CNN.
MoViNet for streaming action recognition: Get familiar with the MoViNet models that are available on TF Hub.
Transfer learning for video classification with MoViNet: This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.
Setup
Begin by installing and importing some necessary libraries, including: remotezip to inspect the contents of a ZIP file, tqdm to use a progress bar, OpenCV to process video files, and tensorflow_docs for embedding data in a Jupyter notebook.
Download a subset of the UCF101 dataset
The UCF101 dataset contains 101 categories of different actions in video, primarily used in action recognition. You will use a subset of these categories in this demo.
The above URL contains a zip file with the UCF 101 dataset. Create a function that uses the remotezip library to examine the contents of the zip file in that URL:
Begin with a few videos and a limited number of classes for training. After running the above code block, notice that the class name is included in the filename of each video.
Define the get_class function that retrieves the class name from a filename. Then, create a function called get_files_per_class which converts the list of all files (files above) into a dictionary listing the files for each class:
Once you have the list of files per class, you can choose how many classes you would like to use and how many videos you would like per class in order to create your dataset.
Create a new function called select_subset_of_classes that selects a subset of the classes present within the dataset and a particular number of files per class:
Define helper functions that split the videos into training, validation, and test sets. The videos are downloaded from a URL with the zip file, and placed into their respective subdirectiories.
The following function returns the remaining data that hasn't already been placed into a subset of data. It allows you to place that remaining data in the next specified subset of data.
The following download_ucf_101_subset function allows you to download a subset of the UCF101 dataset and split it into the training, validation, and test sets. You can specify the number of classes that you would like to use. The splits argument allows you to pass in a dictionary in which the key values are the name of subset (example: "train") and the number of videos you would like to have per class.
After downloading the data, you should now have a copy of a subset of the UCF101 dataset. Run the following code to print the total number of videos you have amongst all your subsets of data.
You can also preview the directory of data files now.
Create frames from each video file
The frames_from_video_file function splits the videos into frames, reads a randomly chosen span of n_frames out of a video file, and returns them as a NumPy array. To reduce memory and computation overhead, choose a small number of frames. In addition, pick the same number of frames from each video, which makes it easier to work on batches of data.
Visualize video data
The frames_from_video_file function that returns a set of frames as a NumPy array. Try using this function on a new video from Wikimedia{:.external} by Patrick Gillett:
In addition to examining this video, you can also display the UCF-101 data. To do this, run the following code:
Next, define the FrameGenerator class in order to create an iterable object that can feed data into the TensorFlow data pipeline. The generator (__call__) function yields the frame array produced by frames_from_video_file and a one-hot encoded vector of the label associated with the set of frames.
Test out the FrameGenerator object before wrapping it as a TensorFlow Dataset object. Moreover, for the training dataset, ensure you enable training mode so that the data will be shuffled.
Finally, create a TensorFlow data input pipeline. This pipeline that you create from the generator object allows you to feed in data to your deep learning model. In this video pipeline, each element is a single set of frames and its associated label.
Check to see that the labels are shuffled.
Configure the dataset for performance
Use buffered prefetching such that you can yield data from the disk without having I/O become blocking. Two important functions to use while loading data are:
Dataset.cache: keeps the sets of frames in memory after they're loaded off the disk during the first epoch. This function ensures that the dataset does not become a bottleneck while training your model. If your dataset is too large to fit into memory, you can also use this method to create a performant on-disk cache.Dataset.prefetch: overlaps data preprocessing and model execution while training. Refer to Better performance with thetf.datafor details.
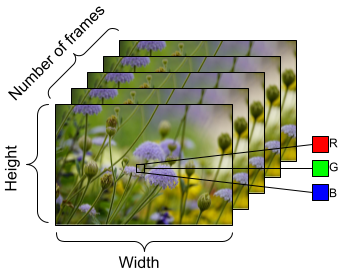
To prepare the data to be fed into the model, use batching as shown below. Notice that when working with video data, such as AVI files, the data should be shaped as a five dimensional object. These dimensions are as follows: [batch_size, number_of_frames, height, width, channels]. In comparison, an image would have four dimensions: [batch_size, height, width, channels]. The image below is an illustration of how the shape of video data is represented.
Next steps
Now that you have created a TensorFlow Dataset of video frames with their labels, you can use it with a deep learning model. The following classification model that uses a pre-trained EfficientNet{:.external} trains to high accuracy in a few minutes:
To learn more about working with video data in TensorFlow, check out the following tutorials: