
Path: blob/master/site/en-snapshot/tutorials/video/video_classification.ipynb
38653 views
Copyright 2022 The TensorFlow Authors.
 View source on GitHub
View source on GitHubVideo classification with a 3D convolutional neural network
This tutorial demonstrates training a 3D convolutional neural network (CNN) for video classification using the UCF101 action recognition dataset. A 3D CNN uses a three-dimensional filter to perform convolutions. The kernel is able to slide in three directions, whereas in a 2D CNN it can slide in two dimensions. The model is based on the work published in A Closer Look at Spatiotemporal Convolutions for Action Recognition by D. Tran et al. (2017). In this tutorial, you will:
Build an input pipeline
Build a 3D convolutional neural network model with residual connections using Keras functional API
Train the model
Evaluate and test the model
This video classification tutorial is the second part in a series of TensorFlow video tutorials. Here are the other three tutorials:
Load video data: This tutorial explains much of the code used in this document.
MoViNet for streaming action recognition: Get familiar with the MoViNet models that are available on TF Hub.
Transfer learning for video classification with MoViNet: This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.
Setup
Begin by installing and importing some necessary libraries, including: remotezip to inspect the contents of a ZIP file, tqdm to use a progress bar, OpenCV to process video files, einops for performing more complex tensor operations, and tensorflow_docs for embedding data in a Jupyter notebook.
Note: Use TensorFlow 2.10 to run this tutorial. Versions above TensorFlow 2.10 may not run successfully.
Load and preprocess video data
The hidden cell below defines helper functions to download a slice of data from the UCF-101 dataset, and load it into a tf.data.Dataset. You can learn more about the specific preprocessing steps in the Loading video data tutorial, which walks you through this code in more detail.
The FrameGenerator class at the end of the hidden block is the most important utility here. It creates an iterable object that can feed data into the TensorFlow data pipeline. Specifically, this class contains a Python generator that loads the video frames along with its encoded label. The generator (__call__) function yields the frame array produced by frames_from_video_file and a one-hot encoded vector of the label associated with the set of frames.
Create the training, validation, and test sets (train_ds, val_ds, and test_ds).
Create the model
The following 3D convolutional neural network model is based off the paper A Closer Look at Spatiotemporal Convolutions for Action Recognition by D. Tran et al. (2017). The paper compares several versions of 3D ResNets. Instead of operating on a single image with dimensions (height, width), like standard ResNets, these operate on video volume (time, height, width). The most obvious approach to this problem would be replace each 2D convolution (layers.Conv2D) with a 3D convolution (layers.Conv3D).
This tutorial uses a (2 + 1)D convolution with residual connections. The (2 + 1)D convolution allows for the decomposition of the spatial and temporal dimensions, therefore creating two separate steps. An advantage of this approach is that factorizing the convolutions into spatial and temporal dimensions saves parameters.
For each output location a 3D convolution combines all the vectors from a 3D patch of the volume to create one vector in the output volume.
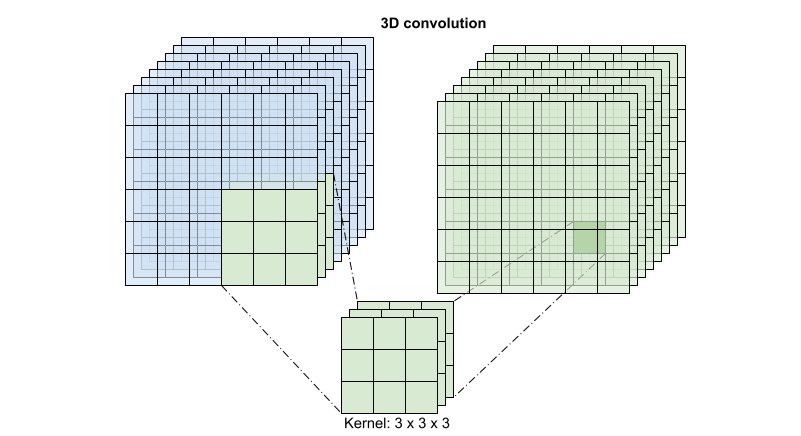
This operation is takes time * height * width * channels inputs and produces channels outputs (assuming the number of input and output channels are the same. So a 3D convolution layer with a kernel size of (3 x 3 x 3) would need a weight-matrix with 27 * channels ** 2 entries. The reference paper found that a more effective & efficient approach was to factorize the convolution. Instead of a single 3D convolution to process the time and space dimensions, they proposed a "(2+1)D" convolution which processes the space and time dimensions separately. The figure below shows the factored spatial and temporal convolutions of a (2 + 1)D convolution.
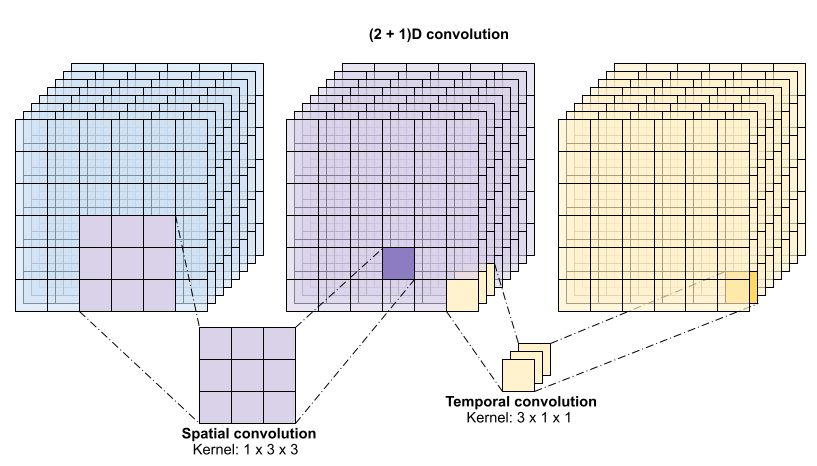
The main advantage of this approach is that it reduces the number of parameters. In the (2 + 1)D convolution the spatial convolution takes in data of the shape (1, width, height), while the temporal convolution takes in data of the shape (time, 1, 1). For example, a (2 + 1)D convolution with kernel size (3 x 3 x 3) would need weight matrices of size (9 * channels**2) + (3 * channels**2), less than half as many as the full 3D convolution. This tutorial implements (2 + 1)D ResNet18, where each convolution in the resnet is replaced by a (2+1)D convolution.
A ResNet model is made from a sequence of residual blocks. A residual block has two branches. The main branch performs the calculation, but is difficult for gradients to flow through. The residual branch bypasses the main calculation and mostly just adds the input to the output of the main branch. Gradients flow easily through this branch. Therefore, an easy path from the loss function to any of the residual block's main branch will be present. This avoids the vanishing gradient problem.
Create the main branch of the residual block with the following class. In contrast to the standard ResNet structure this uses the custom Conv2Plus1D layer instead of layers.Conv2D.
To add the residual branch to the main branch it needs to have the same size. The Project layer below deals with cases where the number of channels is changed on the branch. In particular, a sequence of densely-connected layer followed by normalization is added.
Use add_residual_block to introduce a skip connection between the layers of the model.
Resizing the video is necessary to perform downsampling of the data. In particular, downsampling the video frames allow for the model to examine specific parts of frames to detect patterns that may be specific to a certain action. Through downsampling, non-essential information can be discarded. Moreoever, resizing the video will allow for dimensionality reduction and therefore faster processing through the model.
Use the Keras functional API to build the residual network.
Train the model
For this tutorial, choose the tf.keras.optimizers.Adam optimizer and the tf.keras.losses.SparseCategoricalCrossentropy loss function. Use the metrics argument to the view the accuracy of the model performance at every step.
Train the model for 50 epoches with the Keras Model.fit method.
Note: This example model is trained on fewer data points (300 training and 100 validation examples) to keep training time reasonable for this tutorial. Moreover, this example model may take over one hour to train.
Visualize the results
Create plots of the loss and accuracy on the training and validation sets:
Evaluate the model
Use Keras Model.evaluate to get the loss and accuracy on the test dataset.
Note: The example model in this tutorial uses a subset of the UCF101 dataset to keep training time reasonable. The accuracy and loss can be improved with further hyperparameter tuning or more training data.
To visualize model performance further, use a confusion matrix. The confusion matrix allows you to assess the performance of the classification model beyond accuracy. In order to build the confusion matrix for this multi-class classification problem, get the actual values in the test set and the predicted values.
The precision and recall values for each class can also be calculated using a confusion matrix.
Next steps
To learn more about working with video data in TensorFlow, check out the following tutorials: