
Path: blob/master/site/es-419/guide/dtensor_overview.ipynb
38627 views
Copyright 2019 The TensorFlow Authors.
Conceptos de DTensor
 Ver fuente en GitHub
Ver fuente en GitHubDescripción general
En este colaboratorio se presenta DTensor, una extensión de TensorFlow para cálculos distribuidos sincrónicos.
DTensor ofrece un modelo de programación global que les permite a los programadores componer aplicaciones que operan globalmente con Tensores, mientras que, a la vez, permiten gestionar la distribución entre distintos dispositivos a nivel interno. DTensor distribuye el programa y los tensores según las directivas del particionamiento horizontal (sharding) a través de un procedimiento llamado expansión Un programa, múltiples datos (SPMD).
Al desacoplar la aplicación de las directivas de particionamiento horizontal (sharding), DTensor permite la ejecución de la misma aplicación en un solo dispositivo, en varios o, incluso, en múltiples clientes, sin dejar de preservar la semántica global.
En esta guía se presentan los conceptos de DTensor para cálculos distribuidos y se muestra cómo DTensor se integra con TensorFlow. Para acceder a una demostración en la que se usa DTensor en entrenamiento de modelos, consulte el tutorial sobre entrenamiento distribuido con DTensor.
Preparación
DTensor es parte de la versión de lanzamiento "TensorFlow 2.9.0", que también se ha incluido en las construcciones nocturnas de TensorFlow desde el 09/04/2022.
Una vez instalado, importe tensorflow y tf.experimental.dtensor. Después, configure TensorFlow para usar 6 CPU virtuales.
Aunque este ejemplo usa CPUs, DTensor funciona igual en dispositivos con CPU, GPU o TPU.
El modelo de tensores distribuidos de DTensor
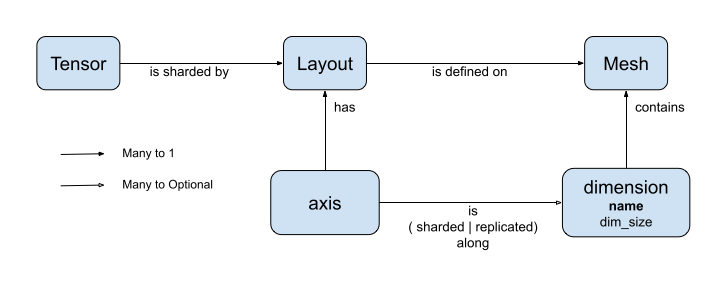
DTensor presenta dos conceptos: dtensor.Mesh y dtensor.Layout. Son abstracciones del modelo de particionamiento horizontal (sharding) de tensores en dispositivos topológicamente relacionados.
Meshdefine la lista de dispositivos para calcular.Layoutdefine cómo particionar horizontalmente la dimensión del tensor en unaMesh.
Malla (mesh)
Mesh representa a una topología cartesiana lógica de un conjunto de dispositivos. A cada dimensión de la cuadrícula cartesiana se la denomina dimensión de malla y nos referimos a ella por un nombre. Los nombres de una dimensión de malla dentro de la misma Mesh deben ser únicos.
Los nombres de medidas mesh son referenciados por Layout para describir el comportamiento del particionamiento horizontal (sharding) de un tf.Tensor a lo largo de cada uno de sus ejes. Esto se describe más detalladamente, más adelante, en la sección sobre Layout.
Mesh se puede pensar como un arreglo multidimensional de dispositivos.
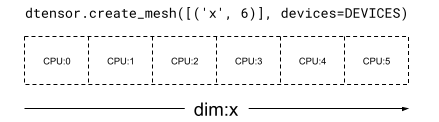
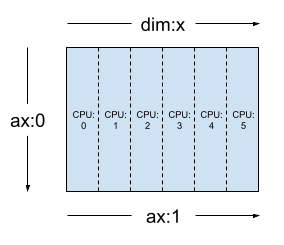
En una Mesh monodimensional, todos los dispositivos forman una lista que se encuentran en una sola dimensión de malla. En el siguiente ejemplo se usa dtensor.create_mesh para crear una malla de 6 dispositivos con CPU a lo largo de una dimensión de malla 'x' con el tamaño de 6 dispositivos:
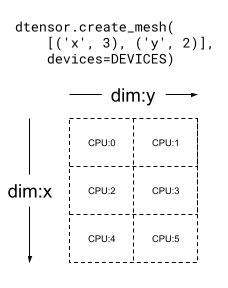
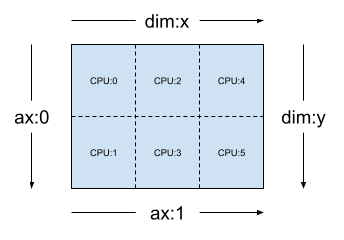
Una Mesh también puede ser multidimensional. En el siguiente ejemplo, 6 dispositivos CPU forman una malla de 3x2, donde la dimensión 'x' de la malla tiene el tamaño de 3 dispositivos, y la dimensión 'y' de la malla, el tamaño de 2 dispositivos:
Diseño (layout)
El Layout especifica cómo se distribuye o particiona horizontalmente un tensor en una Mesh.
Nota: Para evitar confusiones entre Mesh y Layout, en esta guía, el término dimensión siempre se asocia con Mesh, y el término eje con Tensor y Layout.
El rango u orden de Layout debería ser igual al del Tensor, donde se aplique el Layout. Para cada eje del Tensor, el Layout puede especificar una dimensión de malla para particionar horizontalmente el tensor, o especificar el eje como "no particionado". El tensor se replica en cualquiera de las dimensiones de malla que no esté horizontalmente particionada.
El rango de un Layout y la cantidad de dimensiones de una Mesh no necesariamente deben coincidir. Los ejes unsharded de un Layout no necesitan estar asociados a una dimensión de malla y tampoco es necesario que las dimensiones de malla unsharded estén asociadas con un eje de layout.
Analicemos algunos ejemplos de Layout para lo creado para la Mesh en la sección anterior.
En una malla monodimensional como [("x", 6)] (mesh_1d en la sección anterior), Layout(["unsharded", "unsharded"], mesh_1d) es un diseño para un tensor de orden 2 replicado en 6 dispositivos. 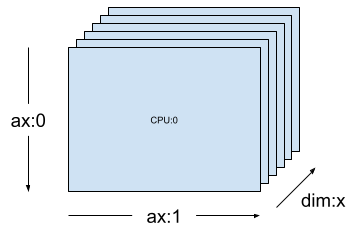
Con el mismo tensor y la misma malla el diseño Layout(['unsharded', 'x']) particionaría horizontalmente el segundo eje del tensor en los 6 dispositivos.
Dada una malla de 3x2 bidimensional como [("x", 3), ("y", 2)], (mesh_2d de la sección anterior), Layout(["y", "x"], mesh_2d) es un diseño para un Tensor de orden 2 cuyo primer eje se particiona horizontalmente en la dimensión "y" de la malla y cuyo segundo eje se particiona horizontalmente en la dimensión "x" de la malla.
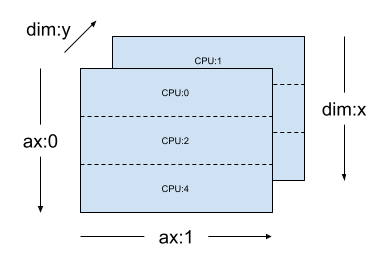
Para la misma mesh_2d, el diseño Layout(["x", dtensor.UNSHARDED], mesh_2d) es un diseño para un Tensor de segundo orden que se replica por "y" y cuyo primer eje se particiona horizontalmente en la dimensión x de la malla.
Aplicaciones monocliente y multicliente
DTensor es compatible tanto con aplicaciones monocliente como multicliente. El núcleo (kernel) para Python en Colab es un ejemplo de una aplicación DTensor monocliente, donde hay un solo proceso de Python.
En una aplicación DTensor multicliente, múltiples procesos Python funcionan colectivamente como una aplicación coherente. La cuadrícula cartesiana de una Mesh en una aplicación DTensor multicliente se puede extender por los dispositivos, independientemente de si están vinculados localmente al cliente actual o si lo están remotamente a otro cliente. El conjunto de todos los dispositivos usados por una Mesh se denomina lista de dispositivos globales.
La creación de una Mesh en una aplicación DTensor multicliente es una operación colectiva en la que la lista de dispositivos globales es idéntica para todos los clientes involucrados y la creación de la Mesh sirve como barrera global.
Durante la creación de la Mesh, cada cliente proporciona su lista de dispositivos locales junto con la lista de dispositivos globales esperada. DTensor valida que ambas listas sean consistentes. Para más información sobre la creación de mallas multicliente y sobre la lista de dispositivos globales, consulte la documentación de la API para dtensor.create_mesh y dtensor.create_distributed_mesh.
La opción monocliente se puede pensar como un caso especial de multicliente, pero con un cliente. En una aplicación monocliente la lista de dispositivos globales es idéntica a la lista de dispositivos locales.
DTensor como tensor particionado horizontalmente
Ahora, empecemos a codificar con DTensor. La función ayudante, dtensor_from_array, demuestra la creación de tensores d a partir de algo que se ve como un tf.Tensor. La función lleva a cabo 2 pasos:
Replica el tensor en cada dispositivo de la malla.
Particiona horizontalmente la copia según el diseño solicitado en sus argumentos.
Anatomía de un DTensor
Un DTensor es un objeto tf.Tensor, pero aumentado con la anotación Layout que define su comportamiento para el particionamiento horizontal. Un DTensor está compuesto por lo siguiente:
Metadatos de tensor global, incluida la forma global y el tipo d de tensor.
Un
Layout, que define laMesha la que pertenece elTensory cómo elTensorse particiona horizontalmente en laMesh.Una lista de tensores componentes, un elemento por dispositivo local en la
Mesh.
Con dtensor_from_array, puede crear su primer DTensor, my_first_dtensor y examinar su contenido.
Diseño (layout) y fetch_layout
El diseño de un DTensor no es un atributo regular de tf.Tensor. Sino que, DTensor brinda una función, dtensor.fetch_layout para acceder al diseño de un DTensor.
Tensores componentes, pack y unpack
Un DTensor está compuesto por una lista de tensores componentes. El tensor componente de un dispositivo en la Mesh es el objeto Tensor que representa a la parte del DTensor global que se almacena en este dispositivo.
Un DTensor se puede separar en tensores componentes con dtensor.unpack. Y dtensor.unpack también se puede usar para inspeccionar los componentes del DTensor y confirmar que están en todos los dispositivos de la Mesh.
Tenga en cuenta que las posiciones de los tensores componentes pueden superponerse en la vista global. Por ejemplo, en el caso de un diseño totalmente replicado, todos los componentes serán réplicas idénticas del tensor global.
Tal como se muestra, my_first_dtensor es un tensor de [0, 1] replicado para los 6 dispositivos.
La operación inversa de dtensor.unpack es dtensor.pack. Los tensores componentes se pueden volver a agrupar en un DTensor.
Los componentes deben tener el mismo orden y tipo d, que será el orden y tipo d del DTensor. Sin embargo, no hay ningún requerimiento estricto para la colocación de tensores componentes en dispositivos como entradas de dtensor.unpack: la función copiará automáticamente los tensores componentes en sus correspondientes y respectivos dispositivos.
Particionamiento horizontal (sharding) de un DTensor para una malla
Hasta aquí, hemos trabajado con my_first_dtensor, que es un DTensor de orden 1 totalmente replicado en una Mesh monodimensional.
A continuación, cree e inspeccione tensores d que estén horizontalmente particionados en una Mesh bidimensional. En el siguiente ejemplo, esto se logra con una Mesh de 3x2 en 6 dispositivos CPU, donde el tamaño de la dimensión 'x' de la malla es de 3 dispositivos y el tamaño de la dimensión 'y' de la malla es de 2 dispositivos.
Tensor de orden 2 particionado horizontalmente por completo en una malla bidimensional
Cree un DTensor de orden 2, de 3x2, particionando horizontalmente su primer eje por la dimensión 'x' de la malla y su segundo eje por la dimensión 'y' de la malla.
Debido a que el tamaño del tensor es igual a la dimensión de la malla por todos los ejes particionados horizontalmente, cada dispositivo recibe un único elemento del DTensor.
El orden del tensor componente es siempre igual al del tamaño global. El DTensor adopta esta convención como una manera simple de preservar la información para localizar la relación entre un tensor componente y el DTensor global.
Tensor de orden 2 replicado por completo en una malla bidimensional
A modo de comparación, cree un DTensor de orden 2 de 3x2 totalmente replicado en la misma malla bidimensional.
Dado que el DTensor está totalmente replicado, cada dispositivo recibe una réplica completa del DTensor de 3x2.
Los órdenes de los tensores componentes son iguales a los de la forma global. De todos modos, este hecho es trivial, porque en este caso la forma de los tensores componentes es igual a la forma global.
Tensor de orden 2 híbrido en una malla bidimensional
Y qué sucede cuando queda en medio de completamente particionado y completamente replicado.
El DTensor permite que un Layout sea híbrido, particionado horizontalmente a lo largo de alguno de los ejes, pero replicado en otros.
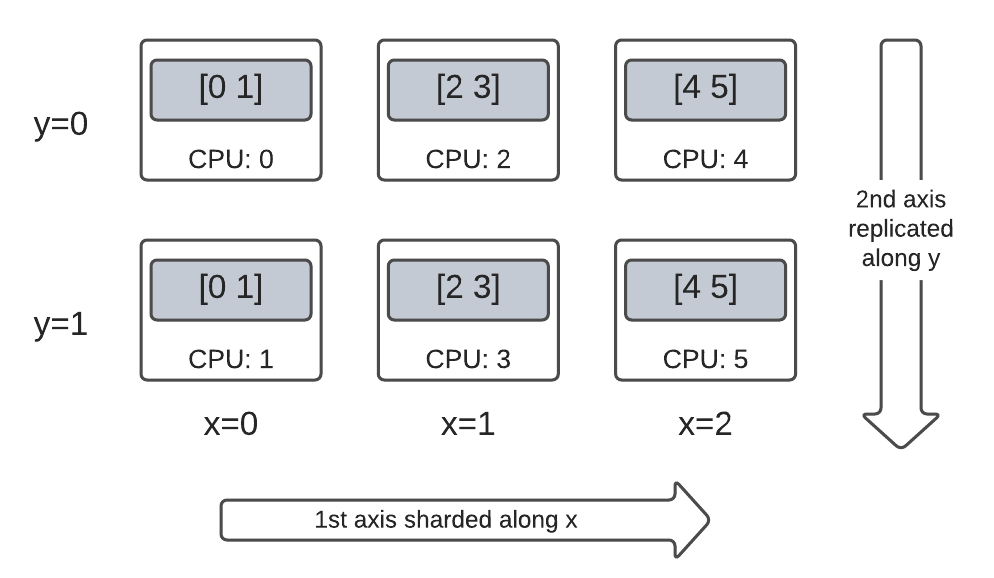
Por ejemplo, es posible particionar horizontalmente el mismo DTensor de orden 2 de 3x2 de la siguiente manera:
El primer eje, a lo largo de la dimensión
'x'de la malla.El segundo eje, a lo largo de la dimensión
'y'de la malla.
Para lograr este esquema de particionamiento horizontal, simplemente debe reemplazar las especificaciones de particionamiento horizontal del segundo eje de 'y' a dtensor.UNSHARDED, para indicar la intención de replicar a lo largo del segundo eje. El objeto de diseño se verá similar a este: Layout(['x', dtensor.UNSHARDED], mesh).
Puede inspeccionar los tensores componentes del DTensor creado y verificar que realmente están horizontalmente particionados según el esquema deseado. Puede resultar útil ilustrar la situación con un gráfico:
Tensor.numpy() y tensor D particionado horizontalmente
Tenga en cuenta que al llamar al método .numpy() en un DTensor particionado horizontalmente, surge un error. La base racional del error es que este se genera como protección contra el agrupamiento no intencionado de datos de múltiples dispositivos de cálculo a la CPU host que sirve de respaldo del arreglo numpy.
API TensorFlow en DTensor
Los tensores d (DTensor) aspiran a convertirse en el reemplazo de los tensores actuales de los programas. Las API Python TensorFlow que consumen tf.Tensor, como las funciones de librería de Ops (operaciones), tf.function, tf.GradientTape, también funcionan con DTensor.
A fin de lograrlo, para cada gráfico de TensorFlow, DTensor produce y ejecuta un gráfico SPMD equivalente en un procedimiento llamado expansión SPMD. Algunos pasos críticos de la expansión SPMD de DTensor son:
Propagar el
Layoutdel particionamiento horizontal del DTensor en el gráfico de TensorFlowReescribir operaciones de TensorFlow en el DTensor global con operaciones de TensorFlow equivalentes en los tensores componentes, insertando operaciones colectivas y de comunicaciones siempre que sea necesario.
Bajar las operaciones de TensorFlow neutrales de backend a operaciones de TensorFlow específicas de backend.
El resultado final es que DTensor es un reemplazo de Tensor.
Nota: DTensor todavía es una API experimental, lo que significa que las fronteras y los límites del modelo de programación DTensor se seguirán explorando y corriendo.
Hay 2 formas de disparar la ejecución de DTensor:
Los DTensor como operandos de una función Python, p. ej.,
tf.matmul(a, b)se ejecutará a través de DTensor sia,bo ambos son DTensors.Mediante la solicitud del resultado de una función Python para ser un tensor d; p. ej.,
dtensor.call_with_layout(tf.ones, layout, shape=(3, 2))correrá a través de DTensor porque solicitamos que la salida de tf.ones se particione horizontalmente según unlayout.
DTensor como operandos
Muchas funciones de la API TensorFlow toman tf.Tensor como su operando y devuelven tf.Tensor como sus resultados. Para estas funciones, se puede expresar la intención de ejecutar una función a través de DTensor pasando los DTensor como operandos. En esta sección se usa tf.matmul(a, b) como ejemplo.
Entrada y salida totalmente replicada
En este caso, los tensores d se replican por completo. En cada uno de los dispositivos de la Mesh,
el componente tensor para el operando
aes[[1, 2, 3], [4, 5, 6]](2x3)el componente tensor para el operando
bes[[6, 5], [4, 3], [2, 1]](3x2)el cálculo consiste de un solo
MatMulde(2x3, 3x2) -> 2x2,el componente tensor para el resultado
ces[[20, 14], [56,41]](2x2)
El número total de operaciones mul de punto flotante es 6 device * 4 result * 3 mul = 72.
Particionamiento horizontal (sharding) de operandos a lo largo del eje contraído
Se puede reducir la cantidad de cálculos por dispositivos mediante el particionamiento horizontal de los operandos a y b. Un esquema popular de particionamiento horizontal para tf.matmul consiste en particionar los operandos a lo largo del eje de contracción, lo que significa particionar horizontalmente a a lo largo del segundo eje y b a lo largo del primero.
El producto de la matriz global particionado horizontalmente bajo este esquema se puede llevar a cabo con eficiencia mediante matmul local que funciona concurrentemente, seguido de una reducción colectiva para agregar los resultados locales. Este es también el modo canónico de implementar un producto punto de matriz distribuida.
El número total de operaciones mul de punto flotante es 6 devices * 4 result * 1 = 24, un factor de reducción 3 comparado con el caso replicado por completo (72) anterior. El factor de 3 se debe al particionamiento horizontal a lo largo de la dimensión x de la malla con un tamaño de 3 dispositivos.
La reducción del número de operaciones que funciona secuencialmente es el principal mecanismo con el que el paralelismo del modelo sincrónico acelera el entrenamiento.
Particionamiento horizontal adicional
Se puede realizar un particionamiento horizontal adicional en las entradas y se trasladan apropiadamente a los resultados. Por ejemplo, se puede aplicar un particionamiento horizontal adicional del operando a a lo largo de su primer eje a la dimensión 'y' de la malla. El particionamiento horizontal adicional se trasladará al primer eje del resultado c.
El número total de operaciones mul de punto flotante es 6 devices * 2 result * 1 = 12, un factor adicional de reducción 2 comparado con el caso (24) anterior. El factor de 2 se debe al particionamiento horizontal a lo largo de la dimensión y de la malla con un tamaño de 2 dispositivos.
DTensor como salida
Qué sucede con las funciones de Python en las que no se usan operandos pero devuelven un resultado tensor que se puede particionar horizontalmente. Algunos ejemplos de tales funciones son los siguientes:
tf.ones,tf.zeros,tf.random.stateless_normal,
Para estas funciones de Python, DTensor proporciona dtensor.call_with_layout que ejecuta, mediante ejecución eager, una función de Python con DTensor y garantiza que el tensor devuelto sea un DTensor con el Layout solicitado.
La función de Python ejecutada con el modo eager, por lo general, solamente contiene una operación de TensorFlow no trivial.
Para usar una función de Python que emite múltiples operaciones de TensorFlow con dtensor.call_with_layout, la función debería convertirse a una tf.function. Llamar a una tf.function es una sola operación de TensorFlow. Cuando se llama a la función tf.function, DTensor puede realizar la propagación del diseño cuando analiza el gráfico de cálculos de la tf.function, antes de que se materialice cualquier tensor intermedio.
API que emiten una sola operación de TensorFlow
Si una función emite una sola operación de TensorFlow, se puede aplicar directamente dtensor.call_with_layout a la función.
API que emiten múltiples operaciones de TensorFlow
Si la API emite múltiples operaciones de TensorFlow, convierta la función en una sola operación con tf.function. Por ejemplo, tf.random.stateleess_normal
Se puede encapsular (wrapear) una función de Python que emita una sola operación de TensorFlow con tf.function. El único inconveniente es el de pagar el costo asociado y la complejidad que ofrece crear una tf.function de una función de Python.
De tf.Variable a dtensor.DVariable
En Tensorflow, tf.Variable es el portador para un valor de Tensor mutable. Con DTensor, la semántica variable correspondiente es provista por dtensor.DVariable.
La razón por la que se introdujo un tipo nuevo de DVariable para la variable DTensor es que las DVariables tienen un requerimiento adicional, que el diseño no pueda cambiar su valor inicial.
Aparte del requerimiento sobre la correspondencia con el layout, una DVariable se comporta de la misma manera que una tf.Variable. Por ejemplo, una DVariable se puede agregar a un DTensor.
También se puede asignar un DTensor a una DVariable.
Si se intenta mutar el diseño de una DVariable mediante la asignación de un DTensor con un diseño incompatible, se produce un error.
¿Qué sigue?
En este colaboratorio, aprendió sobre DTensor, una extensión de TensorFlow para cálculos distribuidos. Para probar estos conceptos en un tutorial, consulte Entrenamiento distribuido con DTensor.