
Path: blob/master/site/es-419/hub/tutorials/movinet.ipynb
38968 views
Copyright 2021 The TensorFlow Hub Authors.
Licensed under the Apache License, Version 2.0 (the "License");
MoViNet para reconocimiento de acciones en streaming
 Ver en GitHub
Ver en GitHubEn este tutorial se demuestra cómo usar un modelo de clasificación de video previamente entrenado para clasificar una actividad (como bailar, nadar, pedalear, etc.) en un video dado.
La arquitectura del modelo usada en este tutorial se denomina MoViNet (Mobile Video Networks, redes móviles de video). Las MoVieNet son una familia de modelos de clasificación de video eficientes entrenados con conjuntos de datos muy grandes (Kinetics 600).
Por el contrario a lo que sucede con los modelos i3d disponibles en TF Hub, las MoViNet también se pueden utilizar con inferencias cuadro por cuadro en transmisión de videos.
Los videos preentrenados se encuentran disponibles en TF Hub. La colección de TF Hub también incluye modelos cuantificados optimizados para TFLite.
La fuente para estos modelos se encuentra en TensorFlow Model Garden. Incluye una versión más extensa de este tutorial que también abarca la construcción y el ajuste fino de un modelo MoViNet.
Este tutorial sobre MoViNet es parte de una serie de tutoriales en video de TensorFlow. A continuación, compartimos otros tres tutoriales:
Carga de datos de video: en este tutorial se explica cómo cargar y preprocesar datos de video desde cero para una canalización de conjuntos de datos de TensorFlow.
Creación de un modelo 3D CNN para la clasificación de video: tenga en cuenta que en este tutorial se usa (2+1)D CNN que descompone los aspectos espaciales y temporales de los datos en 3D. Si usa datos volumétricos como un escaneo MRI, considere utilizar un 3D CNN en vez de un (2+1)D CNN.
Transferencia de aprendizaje para la clasificación de videos con MoViNet: en este tutorial se explica cómo usar, con el conjunto de datos UCF-101, un modelo de clasificación de videos previamente entrenado en un conjunto de datos diferente.
Preparación
Para inferir a partir de modelos más pequeños (A0-A2), la CPU es suficiente en este caso.
Tomamos una lista de 600 etiquetas cinéticas e imprimimos las primeras:
Para trabajar en la clasificación con un video de ejemplo simple, podemos cargar un gif corto de una persona haciendo saltos tijera.

Créditos: la filmación ha sido compartida por Coach Bobby Bluford en YouTube bajo licencia de CC-BY.
Descargamos el gif.
Definimos una función para leer un archivo gif en un tf.Tensor:
El formato de video es (frames, height, width, colors)
Cómo se usa el modelo
Esta sección contiene una descripción en la que se muestra paso a paso cómo se usan los modelos de TensorFlow Hub. Si lo que quiere, solamente, es ver los modelos en acción, puede saltarse la siguiente sección.
Hay dos versiones para cada modelo: base y streaming.
La versión
basetoma un video como entrada y devuelve las probabilidades calculadas en base al promedio de los fotogramas.La versión
streamingtoma un fotograma de video y un estado de RNN como entrada, y devuelve las predicciones para ese fotograma y el nuevo estado RNN.
El modelo base
Descargue el modelo previamente entrenado de TensorFlow Hub.
Esta versión del modelo tiene una signature. Toma un argumento de image que es un tf.float32 con formato (batch, frames, height, width, colors). Devuelve un diccionario que contiene una salida: un tensor tf.float32 de funciones logit con formato (batch, classes).
Para ejecutar la firma en el video, primero hay que agregar la dimensión del batch exterior al video.
Defina una función get_top_k que empaquete el procesamiento de salida que figura arriba para después.
Convierta las logits a probabilidades y busque las 5 clases principales de video. El modelo confirma que el video probablemente sea de jumping jacks (saltos tijera).
El modelo de streaming
En la sección anterior usamos un modelo que se ejecuta en un video completo. Por lo general, cuando se procesa el video no se pretende lograr una sola predicción al final, lo que se busca es que las predicciones se actualicen fotograma a fotograma. Las versiones stream del modelo permiten hacerlo.
Cargue la versión stream del modelo.
Este modelo es un poco más complejo que el base. Hay que controlar el estado interno de las RNN del modelo.
La firma init_states toma la forma (batch, frames, height, width, colors) del video como entrada y devuelve un diccionario grande de tensores que contiene los estados iniciales de RNN:
Una vez que cuenta con el estado inicial para las RNN, puede pasar el estado y un fotograma de video como entrada (el fotograma conserva la forma (batch, frames, height, width, colors)). El modelo devuelve un par (logits, state).
Después de ver el primer fotograma, el modelo no está convencido de que el video sea sobre "saltos tijera":
Si el modelo se ejecuta en un ciclo, pasando el estado actualizado en cada fotograma, el modelo, rápidamente, converge y concluye el resultado correcto:
Notará que la probabilidad es mucho más certera que en secciones anteriores en las que se ejecutó el modelo base. El modelo base devuelve un promedio de las predicciones basadas en los fotogramas.
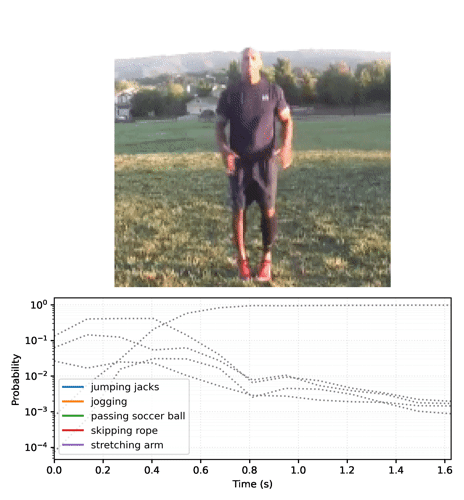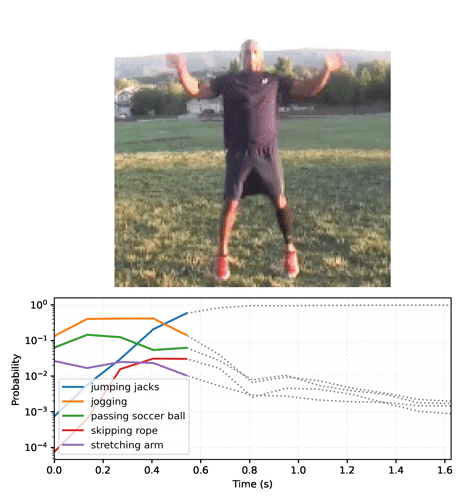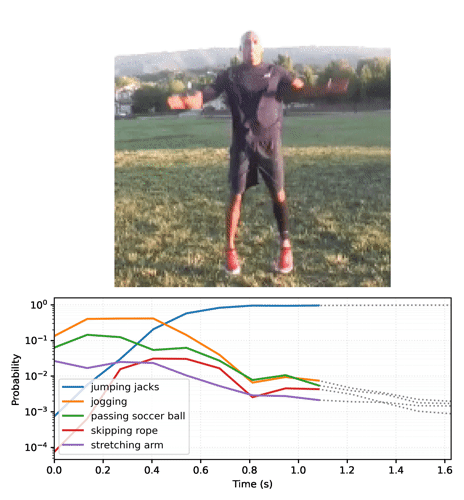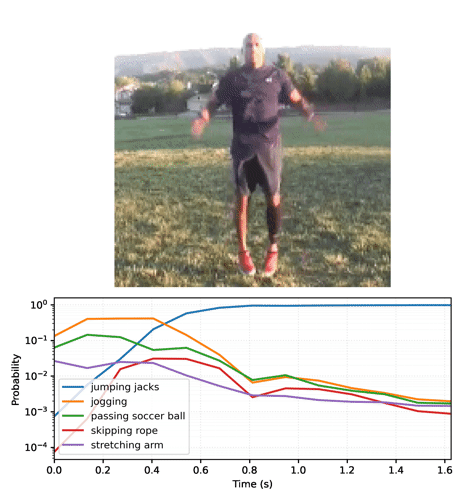
Animación de las predicciones a lo largo del tiempo
En la sección anterior repasamos algunos detalles sobre cómo usar estos modelos. Esta sección toma como base lo descrito allí para producir algunas animaciones inferidas.
La celda oculta (debajo) define funciones ayudante usadas en esta sección.
Comience por ejecutar el modelo de streaming con los fotogramas de video y recolecte las funciones logit:
Convierta la secuencia de probabilidades en un video:
Recursos
Los videos preentrenados se encuentran disponibles en TF Hub. La colección de TF Hub también incluye modelos cuantificados optimizados para TFLite.
La fuente para estos modelos se encuentra en TensorFlow Model Garden. Incluye una versión más extensa de este tutorial que también abarca la construcción y el ajuste fino de un modelo MoViNet.
Próximos pasos
Para obtener más información sobre cómo trabajar con datos de video en TensorFlow, consulte los siguientes tutoriales: