
Path: blob/master/site/es-419/tutorials/customization/custom_training_walkthrough.ipynb
38983 views
Copyright 2018 The TensorFlow Authors.
Entrenamiento personalizado: tutorial
 Ver fuente en GitHub
Ver fuente en GitHubEste tutorial le muestra cómo entrenar un modelo de aprendizaje automático con un bucle de entrenamiento personalizado para categorizar pingüinos por especies. En este bloc de notas, usará TensorFlow para hacer lo siguiente:
Importar un conjunto de datos
Construir un modelo lineal simple
Entrenar el modelo
Evaluar la eficacia del modelo
Usar el modelo entrenado para hacer predicciones
Programar el TensorFlow
Este tutorial demuestra las siguientes tareas de programación de TensorFlow:
Importar datos con la API de conjuntos de datos de TensorFlow
Construir modelos y capas con la API Keras
Problema de clasificación de pingüinos
Imagine que es un ornitólogo en busca de cómo categorizar automáticamente cada pingüino que encuentra. El aprendizaje automático ofrece muchos algoritmos para clasificar pingüinos estadísticamente. Por ejemplo, un sofisticado programa de aprendizaje automático podría clasificar pingüinos basándose en fotografías. El modelo que construye en este tutorial es un poco más sencillo. Clasifica a los pingüinos basándose en su peso corporal, la longitud de sus aletas y sus picos, es decir, la longitud y anchura de su culmen.
Hay 18 especies de pingüinos, pero en este tutorial sólo intentará clasificar las tres siguientes:
Pingüinos barbijo
Pingüinos gentú
Pingüinos de Adelia

Por suerte, un equipo de investigadores ya ha creado y compartido un conjunto de datos de 334 pingüinos con peso corporal, longitud de las aletas, medidas del pico y otros datos. Este conjunto de datos también está convenientemente disponible como el Conjunto de Datos TensorFlow penguins.
Preparación
Instale el paquete tfds-nightly para el conjunto de datos penguins. El paquete tfds-nightly es la versión nightly de los Conjuntos de Datos TensorFlow (TFDS). Para más información sobre TFDS, consulte Descripción general de los conjuntos de datos TensorFlow.
A continuación, seleccione Tiempo de ejecución > Reiniciar tiempo de ejecución en el menú Colab para reiniciar el tiempo de ejecución de Colab.
No siga con el resto de este tutorial sin antes reiniciar el tiempo de ejecución.
Importe TensorFlow y los demás módulos de Python necesarios.
Importar el conjunto de datos
El conjunto de datos predeterminado penguins/processed ya está limpio, normalizado y listo para construir un modelo. Antes de descargar los datos procesados, previsualice una versión simplificada para familiarizarse con los datos originales del estudio sobre pingüinos.
Previsualizar los datos
Descargue la versión simplificada del conjunto de datos de pingüinos (penguins/simple) usando el método tdfs.load de Conjuntos de Datos TensorFlow. Hay 344 registros de datos en este conjunto de datos. Extraiga los cinco primeros registros en un objeto DataFrame para inspeccionar una muestra de los valores de este conjunto de datos:
Las filas numeradas son registros de datos, un ejemplo por línea, donde:
Los seis primeros campos son características: son las características de un ejemplo. Aquí, los campos contienen números que representan medidas de pingüinos.
La última columna es la etiqueta: es el valor que se quiere predecir. Para este conjunto de datos, es un valor entero de 0, 1 o 2 que corresponde al nombre de una especie de pingüino.
En el conjunto de datos, la etiqueta de la especie de pingüino se representa como un número para que sea más fácil trabajar con ella en el modelo que construye. Estos números corresponden a las siguientes especies de pingüinos:
0: pingüino de Adelia1: pingüino barbijo2: pingüino gentú
Cree una lista que contenga los nombres de las especies de pingüinos en este orden. Usará esta lista para interpretar los resultados del modelo de clasificación:
Para saber más sobre características y etiquetas, consulte la sección Terminología ML del Curso acelerado de aprendizaje automático.
Descargar el conjunto de datos preprocesados
Ahora, descargue el conjunto de datos preprocesado de pingüinos (penguins/processed) con el método tfds.load, que devuelve una lista de objetos tf.data.Dataset. Tenga en cuenta que el conjunto de datos penguins/processed no viene con su propio conjunto de prueba, así que use una división 80:20 para dividir el conjunto de datos completo en los conjuntos de entrenamiento y prueba. Usará el conjunto de datos de prueba más adelante para verificar su modelo.
Observe que esta versión del conjunto de datos se procesó reduciendo los datos a cuatro características normalizadas y una etiqueta de especie. En este formato, los datos pueden usarse rápidamente para entrenar un modelo sin más procesamiento.
Puede visualizar algunos clusters trazando algunas características del lote:
Construir un modelo lineal simple
¿Por qué un modelo?
Un modelo es una relación entre las características y la etiqueta. Para resolver el problema de clasificación de pingüinos, el modelo define la relación entre las medidas de masa corporal, aletas y culmen y la especie de pingüino predicha. Algunos modelos sencillos pueden describirse con unas pocas líneas de álgebra, pero los modelos complejos de aprendizaje automático tienen un gran número de parámetros que son difíciles de resumir.
¿Podría determinar la relación entre las cuatro características y la especie de pingüino sin usar el aprendizaje automático? Es decir, ¿podría usar técnicas de programación tradicionales (por ejemplo, muchas sentencias condicionales) para crear un modelo? Tal vez, si analizara el conjunto de datos el tiempo suficiente para determinar las relaciones entre la masa corporal y las medidas del culmen con una especie concreta. Y esto se hace difícil (quizá imposible) en conjuntos de datos más complicados. Un buen enfoque de aprendizaje automático determina el modelo por usted. Si le da suficientes ejemplos representativos al tipo de modelo de aprendizaje automático adecuado, el programa determina las relaciones por usted.
Elegir el modelo
Después tiene que elegir el tipo de modelo que va a entrenar. Hay muchos tipos de modelos y elegir uno bueno requiere experiencia. Este tutorial usa una red neuronal para resolver el problema de clasificación de pingüinos. Las redes neuronales pueden encontrar relaciones complejas entre las características y la etiqueta. Se trata de un grafo muy estructurado, organizado en una o varias capas ocultas. Cada capa oculta está formada por una o más neuronas. Existen varias categorías de redes neuronales y este programa usa una red neuronal densa, o completamente conectada: las neuronas de una capa reciben conexiones de entrada de cada neurona de la capa anterior. Por ejemplo, la figura 2 ilustra una red neuronal densa formada por una capa de entrada, dos capas ocultas y una capa de salida:
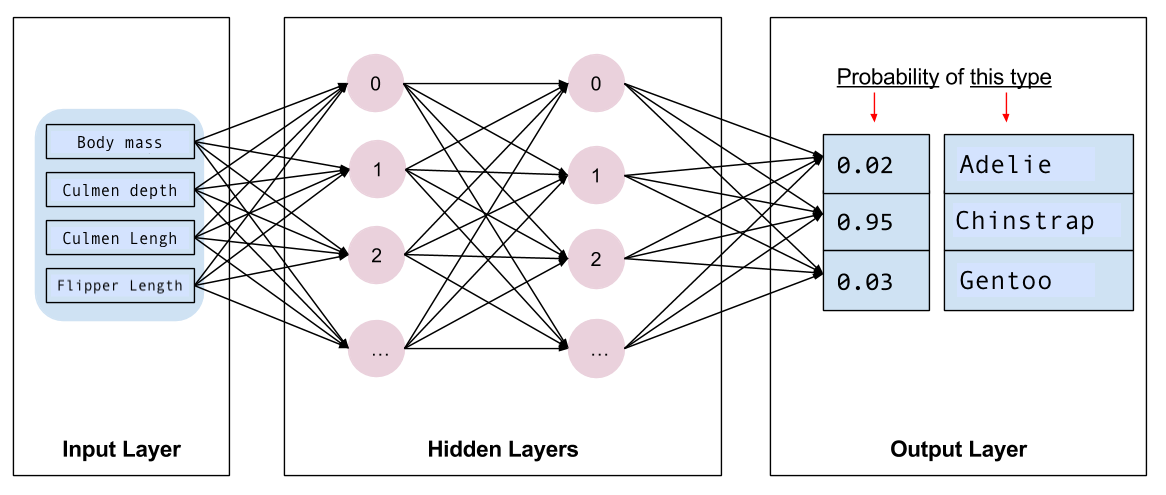 |
| Figura 2. Una red neuronal con características, capas ocultas y predicciones. |
Cuando entrena el modelo de la Figura 2 y lo alimenta con un ejemplo sin etiquetar, produce tres predicciones: la probabilidad de que este pingüino sea de la especie dada. Esta predicción se llama inferencia. En este ejemplo, la suma de las predicciones de salida es 1.0. En la Figura 2, esta predicción se desglosa como 0.02 para la especie de Adelia, 0.95 para la especie barbijo, y 0.03 para la especie gentú. Esto significa que el modelo predice (con un 95 % de probabilidad) que un pingüino de ejemplo no etiquetado es un pingüino Barbijo.
Crear un modelo usando Keras
La API TensorFlow tf.keras es la forma preferida de crear modelos y capas. Esto facilita la creación de modelos y la experimentación, a la vez que Keras se encarga de la complejidad de conectarlo todo.
El modelo tf.keras.Sequential es una pila lineal de capas. Su constructor toma una lista de instancias de capas, en este caso, dos capas tf.keras.layers.Dense con 10 nodos cada una, y una capa de salida con 3 nodos para representar sus predicciones de etiquetas. El parámetro input_shape de la primera capa corresponde al número de características del conjunto de datos, y es obligatorio:
La función de activación determina la forma de salida de cada nodo de la capa. Estas no linealidades son importantes: sin ellas, el modelo sería equivalente a una sola capa. Hay muchas tf.keras.activations, pero para las capas ocultas es común usar ReLU.
La cantidad ideal de capas ocultas y neuronas varía en función del problema y del conjunto de datos. Igual que muchos aspectos del aprendizaje automático, se requiere una mezcla de conocimientos y experimentación para elegir la mejor forma de la red neuronal. Como regla general, aumentar el número de capas ocultas y neuronas suele crear un modelo más potente, que requiere más datos para entrenarse eficazmente.
Usar el modelo
Veamos rápidamente lo que hace este modelo con un lote de funciones:
Si se toma el tf.math.argmax entre las clases, obtenemos el índice de clase predicho. Pero el modelo aún no se ha entrenado, así que no son buenas predicciones:
Entrenar el modelo
El entrenamiento es la fase del aprendizaje automático en la que el modelo se optimiza gradualmente, es decir, el modelo aprende el conjunto de datos. La meta es que aprenda lo suficiente sobre la estructura del conjunto de datos de entrenamiento para hacer predicciones sobre datos que no haya visto. Si aprende demasiado sobre el conjunto de datos de entrenamiento, las predicciones sólo funcionarán para los datos que haya visto y no serán generalizables. Este problema se llama sobreajuste: es como memorizar las respuestas en lugar de comprender cómo resolver un problema.
El problema de clasificación de pingüinos es un ejemplo de aprendizaje automático supervisado: el modelo se entrena a partir de ejemplos que contienen etiquetas. En el aprendizaje automático no supervisado, los ejemplos no contienen etiquetas. En su lugar, el modelo suele encontrar patrones entre las características.
Definir la pérdida y la función de gradientes
Tanto en la fase de entrenamiento como en la de evaluación hay que calcular la pérdida del modelo. Esto mide lo alejadas que están las predicciones de un modelo de la etiqueta deseada, en otras palabras, lo mal que funciona el modelo. Se desea minimizar, u optimizar, este valor.
Su modelo calculará su pérdida usando la función tf.keras.losses.SparseCategoricalCrossentropy que toma las predicciones de probabilidad de clase del modelo y la etiqueta deseada, y devuelve la pérdida media en todos los ejemplos.
Use el contexto tf.GradientTape para calcular los gradientes usados para optimizar su modelo:
Crear un optimizador
Un optimizador aplica los gradientes calculados a los parámetros del modelo para minimizar la función loss. Imagine la función loss como una superficie curva (vea la Figura 3) y quiere encontrar su punto más bajo andando a su alrededor. Los gradientes apuntan en la dirección del ascenso más pronunciado, así que se desplazará en sentido contrario y bajará por la colina. Calculando iterativamente la pérdida y el gradiente para cada lote, ajustará el modelo durante el entrenamiento. Gradualmente, el modelo encontrará la mejor combinación de ponderaciones y sesgo para minimizar la pérdida. Y cuanto menor sea la pérdida, mejores serán las predicciones del modelo.
 |
| Figura 3. Algoritmos de optimización visualizados en el tiempo en un espacio 3D. (Fuente: Stanford class CS231n, licencia del MIT, Créditos de imagen: Alec Radford) |
TensorFlow tiene muchos algoritmos de optimización disponibles para el entrenamiento. En este tutorial, usará tf.keras.optimizers.SGD que implementa el algoritmo descenso de gradiente estocástico (SGD). El parámetro learning_rate fija el tamaño del paso que hay que dar en cada iteración cuesta abajo. Esta tasa es un hiperparámetro que deberá ajustar habitualmente para obtener mejores resultados.
Instancie el optimizador con una velocidad de aprendizaje de 0.01, un valor escalar que se multiplica por el gradiente en cada iteración del entrenamiento:
A continuación, use este objeto para calcular un único paso de optimización:
Bucle de entrenamiento
Con todas las piezas en su sitio, ¡el modelo está listo para ser entrenado! Un bucle de entrenamiento alimenta el modelo con los ejemplos del conjunto de datos para ayudarle a hacer mejores predicciones. El siguiente bloque de código establece estos pasos de entrenamiento:
Itere cada epoca. Una época es una pasada por el conjunto de datos.
Dentro de una época, itere sobre cada ejemplo del
Datasetde entrenamiento tomando sus características (x) y etiqueta (y).Usando las características del ejemplo, haga una predicción y compárela con la etiqueta. Mida la inexactitud de la predicción y úsela para calcular la pérdida y los gradientes del modelo.
Use un
optimizerpara actualizar los parámetros del modelo.Conserve algunas estadísticas para visualizarlas.
Repítalo para cada época.
La variable num_epochs es el número de veces que se repite el bucle sobre la colección de conjuntos de datos. En el siguiente código, num_epochs se fija en 201, lo que significa que este bucle de entrenamiento se ejecutará 201 veces. Aunque parezca contradictorio, entrenar un modelo durante más tiempo no garantiza un mejor modelo. num_epochs es un hiperparámetro que puede ajustar. Seleccionar el número adecuado suele requerir experiencia y experimentación:
También puede usar el método incorporado Model.fit(ds_train_batch) de Keras para entrenar su modelo.
Ver la función de pérdida en el tiempo
Aunque es útil imprimir el progreso del entrenamiento del modelo, puede visualizarlo con TensorBoard, una herramienta de visualización y métricas que viene incluida con TensorFlow. Para este sencillo ejemplo, usará el módulo matplotlib para crear gráficos básicos.
Hay que aprender a interpretar estos gráficos, pero en general lo que se desea es que disminuya la pérdida y aumente la precisión:
Evaluar la eficacia del modelo
Ahora que el modelo está entrenado, puede sacar algunas estadísticas sobre su rendimiento.
Evaluar significa determinar la eficacia del modelo a la hora de hacer predicciones. Para determinar la eficacia del modelo en la clasificación de pingüinos, pásele algunas mediciones y pídale que prediga qué especie de pingüino representan. Luego compare sus predicciones con la etiqueta real. Por ejemplo, un modelo que eligió la especie correcta en la mitad de los ejemplos de entrada tiene una precisión de 0.5. La figura 4 muestra un modelo ligeramente más eficaz, que acierta 4 de cada 5 predicciones con una precisión del 80%:
| Características de ejemplo | Etiqueta | Predicción del modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Un clasificador de pingüinos con un 80% de precisión. |
Configurar el conjunto de pruebas
Evaluar el modelo es similar a entrenarlo. La mayor diferencia es que los ejemplos vienen de un conjunto de prueba distinto del conjunto de entrenamiento. Si quiere evaluar correctamente la eficacia de un modelo, los ejemplos usados para evaluarlo deben ser distintos de los usados para entrenarlo.
El conjunto de datos de pingüinos no tiene un conjunto de datos de prueba separado, así que, en la sección anterior Descargar el conjunto de datos, divida el conjunto de datos original en conjuntos de datos de prueba y de entrenamiento. Use el conjunto de datos ds_test_batch para la evaluación.
Evaluar el modelo en el conjunto de datos de prueba
A diferencia de la etapa de entrenamiento, el modelo sólo evalúa una única época de los datos de prueba. El código siguiente itera sobre cada ejemplo del conjunto de prueba y compara la predicción del modelo con la etiqueta real. Esta comparación se usa para medir la precisión del modelo en todo el conjunto de pruebas:
También puede usar la función model.evaluate(ds_test, return_dict=True) de keras para conseguir información de qué tan preciso es su conjunto de datos de prueba.
Al inspeccionar el último lote, por ejemplo, puede ver que las predicciones del modelo suelen ser correctas.
Usar el modelo entrenado para hacer predicciones
Ha entrenado un modelo y "demostrado" que es bueno (pero no perfecto) para clasificar las especies de pingüinos. Ahora vamos a usar el modelo entrenado para hacer algunas predicciones con ejemplos sin etiquetar; es decir, con ejemplos que tienen características pero no etiquetas.
En la vida real, los ejemplos sin etiquetar pueden venir de muchas fuentes distintas, como apps, archivos CSV y fuentes de datos. Para este tutorial, le damos manualmente tres ejemplos sin etiquetar para predecir sus etiquetas. Recuerde que los números de etiqueta se mapean en una representación con nombre como:
0: pingüino de Adelia1: pingüino barbijo2: pingüino gentú