
Path: blob/master/site/es-419/tutorials/load_data/video.ipynb
38340 views
Copyright 2022 The TensorFlow Authors.
Carga de datos de video
 Ver fuente en GitHub
Ver fuente en GitHubEn este tutorial se demuestra cómo cargar y preprocesar datos de video AVI con el conjunto de datos de acciones humanas UCF101. Una vez que haya preprocesado los datos, se pueden usar para tareas como la clasificación, el reconocimiento, el subtitulado o la agrupación de videos. El conjunto de datos original contiene videos de acción realistas recopilados de YouTube con 101 categorías que incluyen tocar el violonchelo, lavarse los dientes y maquillarse. Aprenderá lo siguiente:
Cargue los datos de un archivo zip.
Lea las secuencias de cuadros de los archivos de video.
Visualice los datos de video.
Encapsule el generador de cuadros
tf.data.Dataset.
Este tutorial de carga y preprocesamiento de videos es la primera parte de una serie de tutoriales sobre videos de TensorFlow. A continuación, compartimos otros tres tutoriales:
Creación de un modelo 3D CNN para la clasificación de video: tenga en cuenta que en este tutorial se usa (2+1)D CNN que descompone los aspectos espaciales y temporales de los datos en 3D. Si usa datos volumétricos como un escaneo MRI, considere utilizar un 3D CNN en vez de un (2+1)D CNN.
MoViNet para reconocimiento de acciones de transmisión: familiarícese con los modelos MoViNet que se encuentran disponibles en TF Hub.
Transferencia de aprendizaje para la clasificación de videos con MoViNet: en este tutorial se explica cómo usar un modelo de clasificación de videos previamente entrenado en un conjunto de datos diferente con el conjunto de datos UCF-101.
Preparación
Comience por instalar e importar algunas de las bibliotecas necesarias, incluidas: remotezip, para inspeccionar el contenido de un archivo ZIP; tqdm, para usar la barra de progreso; OpenCV, para procesar archivos de video; y tensorflow_docs, para incorporar datos de video en un cuaderno Jupyter.
Descarga de un subconjunto del conjunto de datos UCF101
El conjunto de datos UCF101 contiene 101 categorías de acciones diferentes en video, principalmente usadas para reconocimiento de acciones. En este demo se usará un subconjunto de estas categorías.
La URL de aquí arriba lleva a un archivo zip con el conjunto de datos UCF 101. Cree una función que use la biblioteca remotezip para examinar el contenido del archivo zip de esa URL:
Empiece con algunos videos y una cantidad limitada de clases para el entrenamiento. Después de ejecutar el bloque de código de arriba, notará que el nombre de la clase se incluye en el nombre del archivo de cada video.
Defina la función get_class que obtiene el nombre de la clase a partir del nombre del archivo. Después, cree una función llamada get_files_per_class que convierte la lista de todos los archivos (arriba, files) en un diccionario en el que se enumeran los archivos para cada clase:
Una vez que tenga la lista de archivos por clase, podrá elegir cuántas clases quisiera usar y cuántos videos desearía conservar por clase para crear su conjunto de datos.
Cree una función nueva denominada select_subset_of_classes con la que se seleccione un subconjunto de las clases presentes en el conjunto de datos y una cantidad particular de archivos por clase:
Defina las funciones ayudante que separan los videos en los conjuntos de entrenamiento, validación y prueba. Los videos se descargan de una URL en la que está el archivo zip que los contiene y se colocan en sus respectivos subdirectorios.
La siguiente función devuelve los datos restantes que todavía no se han colocado en un subconjunto de datos. Le permitirá colocar esos datos sobrantes en el siguiente subconjunto especificado de datos.
La siguiente función download_ucf_101_subset le permitirá bajar un subconjunto del conjunto de datos UCF101 y separarlo en los conjuntos de entrenamiento, validación y prueba. Puede especificar la cantidad de clases que quisiera usar. El argumento splits le permitirá pasar un diccionario en el que los valores clave son el nombre del subconjunto (p. ej., "entrenamiento") y la cantidad de videos que desearía tener por clase.
Después de descargar los datos, ahora, debería tener una copia de un subconjunto proveniente del conjunto UCF101. Ejecute el código que se encuentra a continuación para imprimir la cantidad total de videos que tiene entre todos los subconjuntos de datos.
Ahora también puede acceder a una vista previa del directorio en el que se encuentran los archivos de datos.
Creación de cuadros a partir de cada uno de los archivos de video
La función frames_from_video_file separa los videos en cuadros, lee un grupo de n_frames elegidos al azar de un archivo de video y los devuelve como un array NumPy. Para reducir la superposición de cálculos y memoria, elija una pequeña cantidad de cuadros. Además, elija la misma cantidad de cuadros de cada uno de los videos. De este modo, el trabajo con los lotes de datos será más sencillo.
Visualización de los datos de video
La función frames_from_video_file devuelve un conjunto de cuadros como un arreglo NumPy array. Intente usar esta función con un video de Wikimedia{:.external} de Patrick Gillett:
Además de examinar este video, podrá ver los datos de UCF-101. Para hacerlo, ejecute el siguiente código:
A continuación, defina la clase FrameGenerator para crear un objeto iterable que pueda introducir los datos en la canalización de datos de TensorFlow. La función (__call__) de generador arroja un arreglo de cuadros producido por frames_from_video_file y un vector codificado en un solo paso (one-hot) de la etiqueta asociada al conjunto de cuadros.
Antes de encapsular el objeto FrameGenerator como un conjunto de datos de TensorFlow Dataset, haga las pruebas correspondientes. También, verifique que el modo de entrenamiento esté activado para el conjunto de datos de entrenamiento, a fin de que los datos se puedan aleatorizar.
Finalmente, cree una canalización de entrada de datos de TensorFlow. Esta canalización que cree a partir del objeto generador le permitirá introducir los datos en su modelo de aprendizaje profundo. En esta canalización de video, cada elemento es un único conjunto de cuadros con su etiqueta asociada.
Controle que las etiquetas sean aleatorias.
Configuración del conjunto de datos para rendimiento
Use una preextracción almacenada en el búfer para que pueda producir datos desde el disco sin provocar un bloqueo en la entrada ni en la salida. Hay dos funciones importantes que habría que usar al cargar los datos:
Dataset.cacheconserva los datos en la memoria después de que se carga desde el disco durante la primera época. Así se garantiza que el conjunto de datos no forme un cuello de botella mientras entrena su modelo. Si el conjunto de datos es muy grande como para guardarlo en la memoria, también puede usar este método para crear un caché en disco de alto rendimiento.Dataset.prefetch: superpone el preprocesamiento de datos y la ejecución del modelo mientras se entrena. Para más detalles, consulte la información sobre mejor rendimiento contf.data.
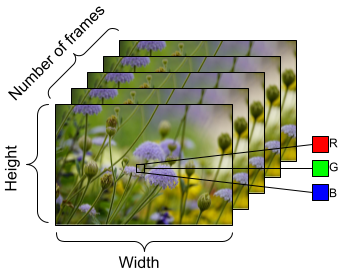
Para preparar los datos con que se alimentará el modelo, use la agrupación en lotes como se muestra a continuación. Advierta que cuando se trabaja con datos de video, como con los archivos AVI, los datos deberían tomar la forma de un objeto de cinco dimensiones. Esas dimensiones son las siguientes: [batch_size, number_of_frames, height, width, channels]. Si comparamos, una imagen tendría cuatro dimensiones: [batch_size, height, width, channels]. La siguiente imagen es una ilustración de cómo se representa la forma de los datos de video.
Próximos pasos
Ahora que ya ha creado un Dataset de TensorFlow de cuadros de video, podrá usarlo con un modelo de aprendizaje profundo. El siguiente modelo de clasificación que usa una EfficientNet{:.external} previamente entrenada, entrena con gran exactitud en unos pocos minutos:
Para más información sobre cómo trabajar con datos de video en TensorFlow, consulte los siguientes tutoriales: