
Path: blob/master/site/es-419/tutorials/understanding/sngp.ipynb
38968 views
Copyright 2021 The TensorFlow Authors.
Aprendizaje profundo consciente de la incertidumbre con SNGP
 Ver en GitHub
Ver en GitHubEn las aplicaciones de IA cuya seguridad es crítica, como la toma de decisiones médicas y la conducción autónoma, o en las que los datos intrínsecamente tienen ruido (por ejemplo, comprensión del lenguaje natural), es importante que un clasificador profundo cuantifique de forma fiable su incertidumbre. El clasificador profundo debe ser capaz de ser consciente de sus propias limitaciones y de cuándo debe ceder el control a los expertos humanos. Este tutorial muestra cómo mejorar la capacidad de un clasificador profundo para cuantificar la incertidumbre utilizando una técnica llamada Proceso neural gaussiano espectral-normalizado (SNGP{.externo}).
La idea central de SNGP es mejorar la conciencia de la distancia de un clasificador profundo aplicando modificaciones sencillas a la red. La conciencia de la distancia de un modelo es una medida de cómo su probabilidad predictiva refleja la distancia entre el ejemplo de prueba y los datos de entrenamiento. Se trata de una propiedad deseable que es común en los modelos probabilísticos estándares (por ejemplo, el proceso Gaussiano{.externo} con núcleos RBF), pero de la que carecen los modelos con redes neuronales profundas. SNGP ofrece una forma sencilla de inyectar este comportamiento de proceso gaussiano en un clasificador profundo manteniendo su precisión predictiva.
Este tutorial implementa un modelo SNGP basado en una red residual profunda (ResNet) sobre el conjunto de datos dos lunas de Scikit-learn{.externo}, y compara su superficie de incertidumbre con la de otros dos enfoques de incertidumbre populares: Abandono de Monte Carlo{.externo} y Ensamble profundo{.externo}.
Este tutorial ejemplifica el modelo SNGP en un conjunto de datos 2D de juguete. Para ver un ejemplo de cómo aplicar SNGP a una tarea de comprensión del lenguaje natural del mundo real usando una base BERT, consulte el tutorial SNGP-BERT. Para ver implementaciones de alta calidad de un modelo SNGP (y de muchos otros métodos de incertidumbre) en una amplia variedad de conjuntos de datos de referencia (como CIFAR-100, ImageNet, Detección de toxicidad en rompecabezas, etc.), consulte la Base de referencia de incertidumbre{.externo}.
Acerca de SNGP
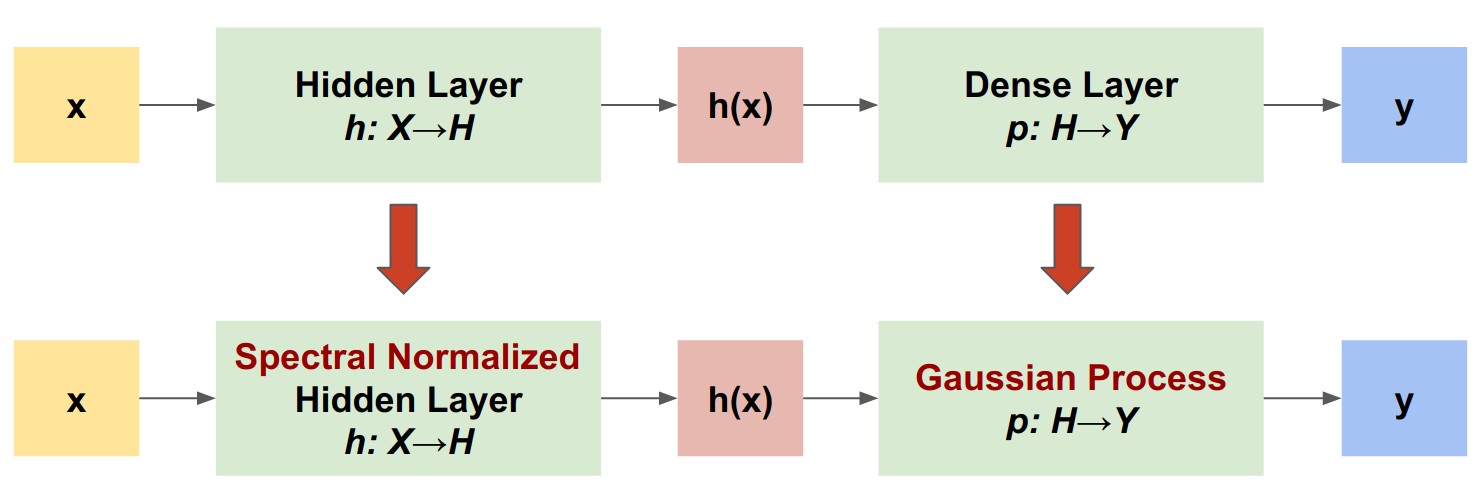
SNGP es un enfoque sencillo para mejorar la calidad de la incertidumbre de un clasificador profundo manteniendo un nivel similar de precisión y latencia. Dada una red residual profunda, SNGP realiza dos cambios sencillos en el modelo:
Aplica la normalización espectral a las capas residuales ocultas.
Reemplaza la capa de salida densa por una capa de proceso gaussiano.
En comparación con otros enfoques de incertidumbre (como el abandono de Monte Carlo o el Ensamble profundo), el SNGP presenta varias ventajas:
Sirve para una amplia gama de arquitecturas basadas en residuos de última generación (por ejemplo, (Wide) ResNet, DenseNet o BERT).
Se trata de un método de modelo único (no se basa en el promedio de ensambles). Por lo tanto, SNGP tiene un nivel de latencia similar al de una única red determinista, y puede escalarse fácilmente a grandes conjuntos de datos como ImageNet{.externo} y Clasificación de comentarios tóxicos de rompecabezas{.externo}.
Tiene un fuerte rendimiento de detección fuera del dominio debido a la propiedad conciencia de la distancia.
Los inconvenientes de este método son:
La incertidumbre predictiva del SNGP se calcula usando la aproximación de Laplace{.externo}. Por lo tanto, teóricamente, la incertidumbre posterior de SNGP es diferente de la de un proceso gaussiano exacto.
El entrenamiento SNGP necesita un paso de restablecimiento de la covarianza al comienzo de una nueva época. Esto puede añadir una pequeña cantidad de complejidad adicional a un proceso de entrenamiento. Este tutorial muestra una forma sencilla de implementarlo usando retrollamadas de Keras.
Preparación
Defina macros de visualización
El conjunto de datos de dos lunas
Cree los conjuntos de datos de entrenamiento y evaluación a partir del conjunto de datos scikit-learn dos lunas{.externo}.
Evalúe el comportamiento predictivo del modelo en todo el espacio de entrada 2D.
Para evaluar la incertidumbre del modelo, añada un conjunto de datos fuera del dominio (OOD) que pertenezca a una tercera clase. El modelo nunca observa estos ejemplos OOD durante el entrenamiento.
Aquí, el azul y el naranja representan las clases positiva y negativa, y el rojo los datos OOD. Se espera que un modelo que cuantifique bien la incertidumbre sea seguro cuando esté cerca de los datos de entrenamiento (es decir, cerca de 0 o 1), y sea incierto cuando esté lejos de las regiones de datos de entrenamiento (es decir, cerca de 0.5).
El modelo determinístico
Definir modelo
Partimos del modelo determinista (línea de referencia): una red residual multicapa (ResNet) con regularización de abandono.
Este tutorial usa una ResNet de seis capas con 128 unidades ocultas.
Entrenar el modelo
Configure los parámetros de entrenamiento para usar SparseCategoricalCrossentropy como función de pérdida y el optimizador Adam.
Entrene el modelo durante 100 épocas con un tamaño de lote de 128.
Visualizar la incertidumbre
Ahora visualice las predicciones del modelo determinista. Primero trace la probabilidad de clase:
En este gráfico, el amarillo y el morado son las probabilidades de predicción para las dos clases. El modelo determinista hizo un buen trabajo al clasificar las dos clases conocidas (azul y naranja) con un límite de decisión no lineal. Sin embargo, no es consciente de la distancia, y clasificó los ejemplos rojos nunca observados fuera del dominio (OOD) con confianza como la clase naranja.
Visualice la incertidumbre del modelo calculando la varianza predictiva:
En este diagrama, el amarillo indica una incertidumbre alta y el morado una incertidumbre baja. La incertidumbre de una ResNet determinista sólo depende de la distancia de los ejemplos de prueba respecto al límite de decisión. Esto lleva al modelo a tener un exceso de confianza cuando se encuentra fuera del dominio de entrenamiento. La siguiente sección muestra cómo el SNGP se comporta de forma diferente en este conjunto de datos.
El modelo SNGP
Defina el modelo SNGP
Implementemos ahora el modelo SNGP. Los dos componentes SNGP, SpectralNormalization y RandomFeatureGaussianProcess, están disponibles en las capas built-in de tensorflow_model.
Inspeccionemos con más detalle estos dos componentes. (También puede pasar a la sección el modelo SNGP completo para saber cómo se implementa SNGP).
Envoltorio SpectralNormalization
SpectralNormalization{.externo} es un contenedor de capas Keras. Se puede aplicar a una capa Dense existente de esta manera:
La normalización espectral regulariza la ponderación oculta guiando gradualmente su norma espectral (es decir, el mayor valor propio de ) hacia el valor objetivo norm_multiplier).
Nota: Normalmente es preferible configurar norm_multiplier a un valor inferior a 1. Sin embargo, en la práctica, también se puede relajar a un valor superior para garantizar que la red profunda tenga suficiente poder de expresión.
La capa de Proceso Gaussiano (GP)
RandomFeatureGaussianProcess{.externo} implementa una aproximación basada en características aleatorias{.externo} a un modelo de proceso gaussiano que es entrenable de principio a fin con una red neuronal profunda. En el fondo, la capa del proceso gaussiano implementa una red de dos capas:
Aquí, es la entrada, y y son ponderaciones congeladas inicializadas aleatoriamente a partir de distribuciones gaussiana y uniforme, respectivamente (por lo tanto, a se les llama "características aleatorias"). es la ponderación del núcleo aprendible similar a la de una capa Dense.
Los principales parámetros de las capas GP son:
unidades: La dimensión de los logits de salida.num_inducing: La de dimensión de la ponderación oculta . Por defecto es 1024.normalize_input: Si se aplica la normalización de capas a la entrada .scale_random_features: Si se aplica la escala a la salida oculta.
Nota: Para una red neuronal profunda que sea sensible a la tasa de aprendizaje (por ejemplo, ResNet-50 y ResNet-110), se recomienda generalmente configurar normalize_input=True para estabilizar el entrenamiento, y configurar scale_random_features=False para evitar que la tasa de aprendizaje se modifique de forma inesperada al pasar por la capa GP.
gp_cov_momentumcontrola cómo se calcula la covarianza del modelo. Si se configura en un valor positivo (por ejemplo,0.999), la matriz de covarianza se calcula usando la actualización promedio móvil basada en el momentum (similar a la normalización por lotes). Si se configura en-1, la matriz de covarianza se actualiza sin momentum.
Nota: El método de actualización basado en el momentum puede ser sensible al tamaño del lote. Por lo tanto, se recomienda configurar gp_cov_momentum=-1 para calcular la covarianza con exactitud. Para que esto funcione correctamente, el estimador de la matriz de covarianza debe reiniciarse al comienzo de una nueva época para evitar contar los mismos datos dos veces. Para RandomFeatureGaussianProcess, esto puede hacerse llamando a su reset_covariance_matrix(). La siguiente sección muestra una sencilla implementación de esto usando la API incorporada de Keras.
Dado un lote de entrada con forma (batch_size, input_dim), la capa GP devuelve un tensor logits (forma (batch_size, num_classes)) para la predicción, y también un tensor covmat (forma (batch_size, batch_size)) que es la matriz de covarianza posterior de los logits del lote.
Nota: Observe que bajo esta implementación del modelo SNGP, los logits predictivos para todas las clases comparten la misma matriz de covarianza , que describe la distancia entre de los datos de entrenamiento.
Teóricamente, es posible ampliar el algoritmo para calcular diferentes valores de varianza para diferentes clases (como se presentó en el documento original de SNGP{.externo}). Sin embargo, esto es difícil de escalar para problemas con grandes espacios de salida (como la clasificación con ImageNet o el modelado del lenguaje).
Dada la clase base DeepResNet, el modelo SNGP puede implementarse fácilmente modificando las capas ocultas y de salida de la red residual. Para que sea compatible con la API model.fit() de Keras, modifique también el método call() del modelo para que sólo emita logits durante el entrenamiento
Usar la misma arquitectura que el modelo determinista.
Añada esta retrollamada a la clase modelo DeepResNetSNGP.
Entrenar el modelo
Use tf.keras.model.fit para entrenar el modelo.
Visualizar la incertidumbre
Primero calcule los logaritmos predictivos y las varianzas.
Ahora calcule la probabilidad predictiva posterior. El método clásico para calcular la probabilidad predictiva de un modelo probabilístico es usar el muestreo de Montecarlo, es decir,
donde es el tamaño de la muestra, y son muestreos aleatorios del (sngp_logits posterior al SNGP, sngp_covmat). Sin embargo, este enfoque puede resultar lento para aplicaciones sensibles a la latencia, como la conducción autónoma o las pujas en tiempo real. En su lugar, puede aproximar usando el método de campo medio{.externo}:
donde es la varianza SNGP, y se selecciona a menudo como o .
Nota: En lugar de fijar a un valor fijo, también puede tratarlo como un hiperparámetro, y afinarlo para optimizar el rendimiento de calibración del modelo. Esto se conoce como escalado de temperatura{.externo} en la literatura de incertidumbre del aprendizaje profundo.
Este método de campo medio se implementa como una función incorporada layers.gaussian_process.mean_field_logits:
Resumen SNGP
Ahora puede combinarlo todo. Todo el procedimiento (entrenamiento, evaluación y cálculo de la incertidumbre) puede realizarse en sólo cinco líneas:
Visualice la probabilidad de clase (izquierda) y la incertidumbre predictiva (derecha) del modelo SNGP.
Recuerde que en el gráfico de probabilidad de clase (izquierda), el amarillo y el morado son probabilidades de clase. Cuando está cerca del dominio de los datos de entrenamiento, SNGP clasifica correctamente los ejemplos con una confianza alta (es decir, asignando una probabilidad cercana a 0 o 1). Cuando se aleja de los datos de entrenamiento, SNGP pierde gradualmente confianza y su probabilidad de predicción se acerca a 0.5, mientras que la incertidumbre (normalizada) del modelo se eleva a 1.
Compárelo con la superficie de incertidumbre del modelo determinista:
Como ya se ha mencionado, un modelo determinista no es consciente de la distancia. Su incertidumbre viene definida por la distancia del ejemplo de prueba respecto al límite de decisión. Esto lleva al modelo a producir predicciones excesivamente seguras para los ejemplos fuera del dominio (rojo).
Comparación con otros enfoques de incertidumbre
Esta sección compara la incertidumbre de SNGP con el abandono de Monte Carlo{.externo} y Ensamble profundo{.externo}.
Ambos métodos se basan en el promedio de Monte Carlo de múltiples pasadas hacia delante de modelos deterministas. En primer lugar, configure el tamaño del ensamble .
Abandono de Monte Carlo
Dada una red neuronal entrenada con capas de Abandono, el abandono de Monte Carlo calcula la probabilidad predictiva media
haciendo un promedio sobre múltiples pasadas hacia delante con Abandono .
Ensamble profundo
Ensamble profundo es un método de última generación (pero costoso) para el aprendizaje profundo de incertidumbre. Para entrenar un ensamble profundo, primero hay que entrenar miembros del ensamble.
Recopile logits y calcule la probabilidad predictiva media .
Tanto el método de Abandono de Monte Carlo como el de Ensamble profundo mejoran la capacidad de incertidumbre del modelo al hacer que el límite de decisión sea menos seguro. Sin embargo, ambos heredan la limitación de la red profunda determinista al carecer de conciencia de la distancia.
Resumen
En este tutorial, usted:
Implementó el modelo SNGP en un clasificador profundo para mejorar su conocimiento de la distancia.
Entrenó el modelo SNGP de principio a fin usando la API
Model.fitde Keras.Visualizó el comportamiento de incertidumbre del SNGP.
Comparó el comportamiento de la incertidumbre entre los modelos SNGP, de abandono de Monte Carlo y de ensamble profundo.
Recursos y lecturas complementarias
Consulte el tutorial SNGP-BERT para ver un ejemplo de aplicación de SNGP en un modelo BERT para comprender el lenguaje natural con conocimiento de la incertidumbre.
Vaya al repositorio de GitHub de Líneas de referencia de incertidumbre{.externo} para implementar el modelo SNGP (y muchos otros métodos de incertidumbre) en una amplia variedad de conjuntos de datos de referencia (por ejemplo, CIFAR, ImageNet, Detección de toxicidad de rompecabezas, etc.).
Para una comprensión más profunda del método SNGP, consulte el artículo titulado Estimación de la incertidumbre simple y basada en principios con aprendizaje profundo determinista a través del conocimiento de la distancia{.externo}.