
Path: blob/master/site/es-419/tutorials/video/video_classification.ipynb
38566 views
Copyright 2022 The TensorFlow Authors.
 Ver fuente en GitHub
Ver fuente en GitHubClasificación de videos con una red neuronal convolucional 3D
Este tutorial demuestra el entrenamiento de una red neuronal convolucional 3D (CNN) para la clasificación de vídeos utilizando el conjunto de datos de reconocimiento de acciones UCF101. Una CNN 3D utiliza un filtro tridimensional para realizar las convoluciones. El núcleo puede deslizarse en tres direcciones, mientras que en una CNN 2D puede deslizarse en dos dimensiones. El modelo se basa en el trabajo publicado en A Closer Look at Spatiotemporal Convolutions for Action Recognition por D. Tran et al. (2017). En este tutorial, usted:
Construirá una canalización de entrada
Construirá un modelo de red neuronal convolucional 3D con conexiones residuales usando la API funcional de Keras
Entrenará el modelo
Evaluará y probará el modelo
Este video tutorial de clasificación es la segunda parte de una serie de video tutoriales de TensorFlow. Aquí están los otros tres tutoriales:
Cargar datos de vídeo: Este tutorial explica gran parte del código usado en este documento.
MoViNet para el reconocimiento de acciones en streaming: Familiarícese con los modelos MoViNet disponibles en TF Hub.
Aprendizaje por transferencia para la clasificación de vídeo con MoViNet: Este tutorial explica cómo usar un modelo de clasificación de vídeo preentrenado y entrenado en un conjunto de datos diferente con el conjunto de datos UCF-101.
Preparación
Comience instalando e importando algunas librerías necesarias, incluyendo: remotezip para inspeccionar el contenido de un archivo ZIP, tqdm para usar una barra de progreso, OpenCV para procesar archivos de vídeo, einops para realizar operaciones tensoriales más complejas, y tensorflow_docs para incorporar datos en un bloc de notas de Jupyter.
Nota: Use TensorFlow 2.10 para ejecutar este tutorial. Es posible que las versiones superiores a TensorFlow 2.10 no se ejecuten correctamente.
Carga y procesamiento de datos de video
La celda oculta inferior define funciones ayudantes para descargar una porción de datos del conjunto de datos UCF-101 y cargarla en un tf.data.Dataset. Puede aprender más sobre los pasos específicos del preprocesamiento en el tutorial Carga de datos de video, que le guiará a través de este código con más detalle.
La clase FrameGenerator al final del bloque oculto es la utilidad más importante en este caso. Crea un objeto iterable que puede alimentar los datos en la canalización de datos de TensorFlow. Específicamente, esta clase contiene un generador Python que carga los cuadros de video junto con su etiqueta codificada. La función del generador (__call__) produce el arreglo del marco emitido por frames_from_video_file y un vector codificado en un solo paso (one-hot) de la etiqueta asociada con el conjunto de cuadros.
Cree los conjuntos de entrenamiento, validación y prueba (train_ds, val_ds y test_ds).
Crear el modelo
El siguiente modelo de red neuronal convolucional 3D se basa en el artículo A Closer Look at Spatiotemporal Convolutions for Action Recognition de D. Tran et al. (2017). El artículo compara varias versiones de ResNets 3D. En lugar de operar sobre una sola imagen con dimensiones (height, width), como las ResNets estándares, estas operan sobre el volumen de vídeo (time, height, width). El enfoque más obvio a este problema sería reemplazar cada (layers.Conv2D) de convolución 2D por una convolución 3D (layers.Conv3D).
Este tutorial usa una convolución (2 + 1)D con conexiones residuales. La convolución (2 + 1)D permite descomponer las dimensiones espacial y temporal, creando así dos pasos separados. Una ventaja de este enfoque es que la factorización de las convoluciones en dimensiones espaciales y temporales ahorra parámetros.
Para cada ubicación de salida, una convolución 3D combina todos los vectores de un parche 3D del volumen para crear un vector en el volumen de salida.
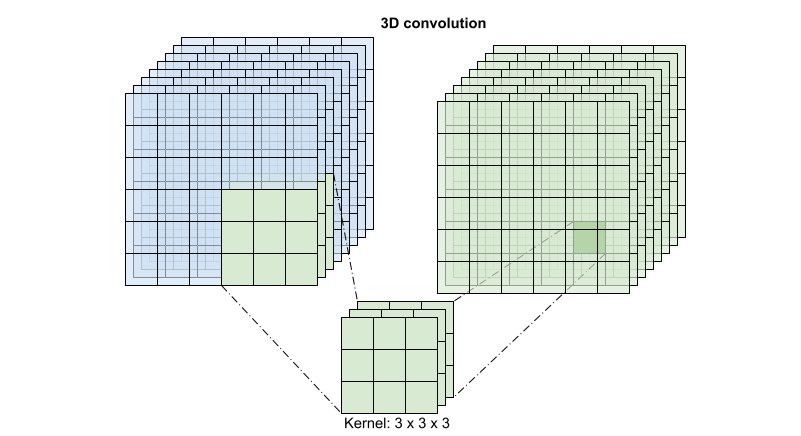
Esta operación toma entradas time * height * width * channels y produce salidas channels (suponiendo que el número de canales de entrada y de salida sea el mismo. Así, una capa de convolución 3D con un tamaño de kernel de (3 x 3 x 3) necesitaría una matriz de ponderación con entradas de 27 * canales ** 2. El documento de referencia encontró que un enfoque más eficaz y eficiente era factorizar la convolución. En lugar de una única convolución 3D para procesar las dimensiones temporal y espacial, propusieron una convolución "(2+1)D" que procesa las dimensiones espacial y temporal por separado. La figura siguiente muestra las convoluciones espacial y temporal factorizadas de una convolución (2 + 1)D.
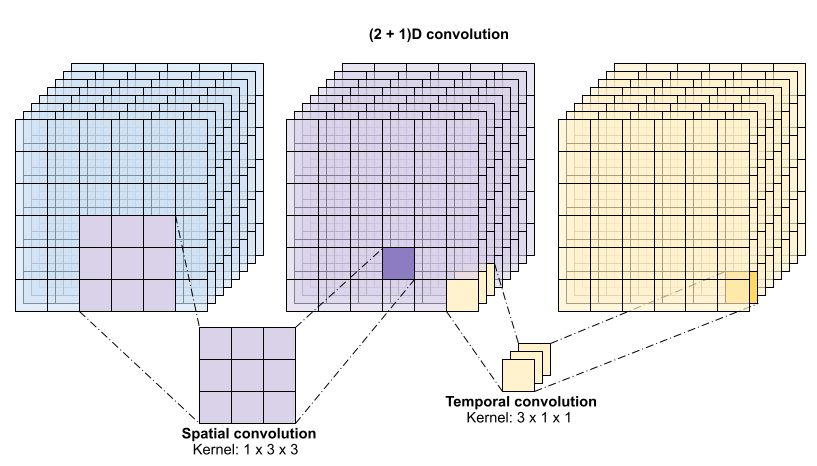
La principal ventaja de este enfoque es que reduce el número de parámetros. En la convolución (2 + 1)D, la convolución espacial toma datos de la forma (1, width, height), mientras que la convolución temporal toma datos de la forma (time, 1, 1). Por ejemplo, una convolución (2 + 1)D con tamaño de kernel (3 x 3 x 3) necesitaría matrices de ponderación de tamaño (9 * channels**2) + (3 * channels**2), menos de la mitad que la convolución 3D completa. Este tutorial implementa la ResNet18 (2 + 1)D, en la que cada convolución de la resnet se sustituye por una convolución (2+1)D.
Un modelo ResNet se elabora a partir de una secuencia de bloques residuales. Un bloque residual tiene dos ramas. La rama principal realiza el cálculo, pero dificulta el paso de los gradientes. La derivación residual pasa por alto el cálculo principal y, en la mayoría de los casos, se limita a añadir la entrada a la salida de la rama principal. Los gradientes fluyen fácilmente a través de esta rama. Por lo tanto, habrá una ruta fácil desde la función de pérdida hasta cualquiera de las ramas principales del bloque residual. Esto evita el problema del gradiente evanescente.
Cree la rama principal del bloque residual con la siguiente clase. A diferencia de la estructura estándar de ResNet, ésta utiliza la capa personalizada Conv2Plus1D en lugar de layers.Conv2D.
Para añadir la rama residual a la rama principal es necesario que tenga el mismo tamaño. La capa Project inferior se ocupa de los casos en los que se modifica el número de canales en la derivación. En concreto, se añade una secuencia de capa densamente conectada seguida de normalización.
Use add_residual_block para crear una conexión de salto entre las capas del modelo.
Es necesario cambiar el tamaño del vídeo para realizar un downsampling de los datos. En concreto, el downsampling de los fotogramas de vídeo permite que el modelo examine partes concretas de los fotogramas para detectar patrones que puedan ser específicos de una determinada acción. Mediante el downsampling, se puede descartar la información no esencial. Además, redimensionar el vídeo permitirá reducir la dimensionalidad y, por tanto, acelerar el procesamiento a través del modelo.
Usa la API funcional Keras para construir la red residual.
Entrenar el modelo
Para este tutorial, seleccione el optimizador tf.keras.optimizers.Adam y la función de pérdida tf.keras.losses.SparseCategoricalCrossentropy. Use el argumento metrics para ver la precisión del rendimiento del modelo en cada paso.
Entrene el modelo durante 50 épocas con el método Model.fit de Keras.
Nota: Este modelo de ejemplo se entrena con menos puntos de datos (300 ejemplos de entrenamiento y 100 de validación) para mantener un tiempo de entrenamiento razonable para este tutorial. Además, este modelo de ejemplo puede tardar más de una hora en entrenarse.
Visualizar los resultados
Cree gráficos de la pérdida y la precisión en los conjuntos de entrenamiento y validación:
Evaluar el modelo
Usar Model.evaluate de Keras para conocer la pérdida y la precisión en el conjunto de datos de prueba.
Nota: El modelo de ejemplo de este tutorial usa un subgrupo del conjunto de datos UCF101 para mantener un tiempo de entrenamiento razonable. La precisión y la pérdida pueden mejorarse con un mayor ajuste de hiperparámetros o con más datos de entrenamiento.
Para visualizar mejor el rendimiento del modelo, use una matriz de confusión. La matriz de confusión le permite evaluar el rendimiento del modelo de clasificación más allá de la precisión. Para construir la matriz de confusión para este problema de clasificación multiclase, obtenga los valores reales en el conjunto de pruebas y los valores predichos.
Los valores de precisión y memoria de cada clase también pueden calcularse utilizando una matriz de confusión.
Siguientes pasos
Para más información sobre cómo trabajar con datos de video en TensorFlow, consulte los siguientes tutoriales: