
Path: blob/master/site/ja/hub/tutorials/movinet.ipynb
38945 views
Copyright 2021 The TensorFlow Hub Authors.
Licensed under the Apache License, Version 2.0 (the "License");
ストリーミング行動認識のための MoViNet
 GitHub でソースを表示
GitHub でソースを表示このチュートリアルでは、事前トレーニング済みの動画分類モデルを使用して、特定の動画のアクティビティ(ダンス、水泳、サイクリングなど)を分類する方法を説明します。
このチュートリアルで使用されるモデルアーキテクチャは MoViNet(Mobile Video Networks)と呼ばれるものです。MoViNets は大型のデータセット(Kinetics 600)でトレーニングされた効率的な動画分類モデルファミリーです。
TF Hub にある i3d モデル とは反対に、MoViNets はストリーミング動画のフレームごとの推論もサポートしています。
事前トレーニング済みのモデルは TF Hub から利用できます。TF Hub コレクションには、TFLite 用に最適化された量子化モデルも含まれています。
これらのモデルのソースは TensorFlow Model Garden にあり、MoviNet モデルの構築とファインチューニングもカバーしたこのチュートリアルの長編が含まれています。
この MoviNet チュートリアルは、TensorFlow 動画チュートリアルシリーズの一部です。他に、以下の 3 つのチュートリアルがあります。
動画データを読み込む: このチュートリアルでは、TensorFlow データセットパイプラインにゼロから動画データを読み込んで前処理する方法を説明します。
動画分類用の 3D CNN モデルを構築する。このチュートリアルでは、3D データの空間と時間の側面を分解する (2+1)D CNN が使用されています。MRI スキャンなどの体積データを使用している場合は、(2+1)D CNN ではなく、3D CNN を使用することを検討してください。
MoviNet を使った動画分類の転移学習: このチュートリアルでは、異なるデータセットで事前にトレーニングされた動画分類モデルを UCF-101 データセットで使用する方法を説明します。
セットアップ
より小さなモデル(A0-A2)の推論の場合、この Colab には CPU で十分に対応できます。
kinetics 600 のラベルリストを取得し、最初のいくつかのラベルを出力します。
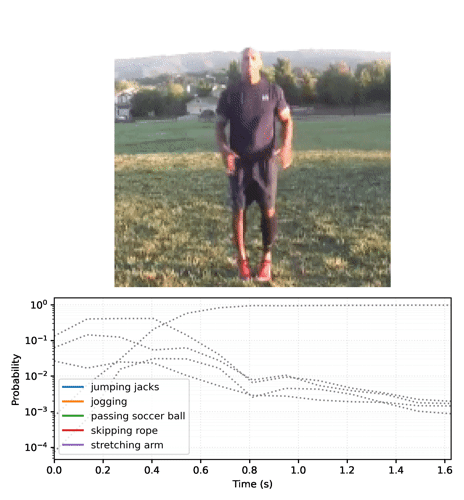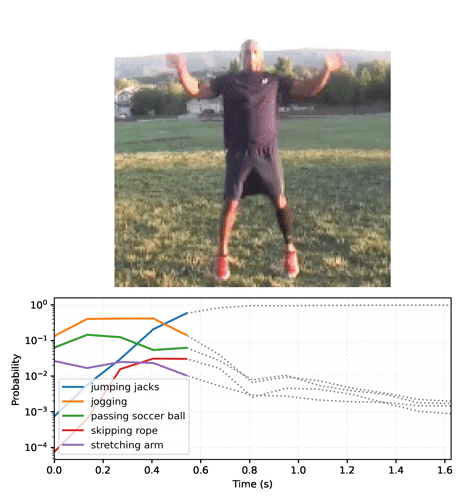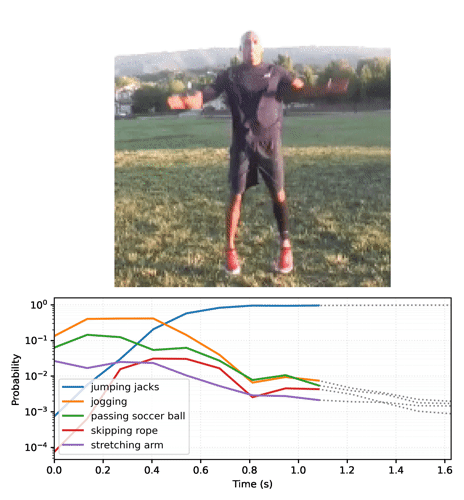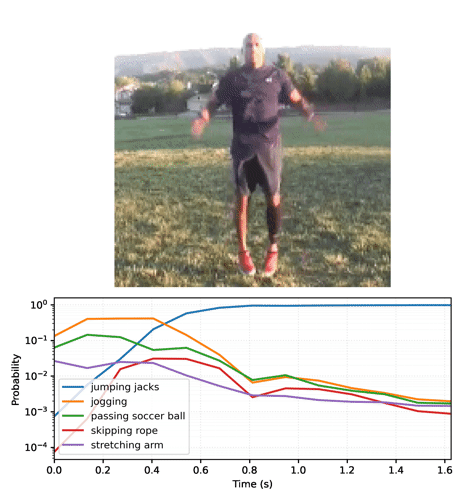
分類用の単純なサンプル動画を提供するために、ジャンピングジャックを行っている短い動画を読み込みます。

出典: Bobby Bluford コーチが YouTube で共有した映像。CC-BY ライセンス。
gif をダウンロードします。
gif ファイルを tf.Tensor に読み取る関数を定義します。
動画の形状は (frames, height, width, colors) です。
モデルの使用方法
このセクションには、TensorFlow Hub のモデルの使用方法を示す手順が含まれます。モデルの実演のみをご覧になる場合は、次のセクションに進んでください。
各モデルには、base と streaming の 2 つのバージョンがあります。
baseバージョンは動画を入力として取り、フレームで平均化された確率を返します。streamingバージョンは、動画フレームと RNN の状態を入力として取り、そのフレームの予測と新しい RNN の状態を返します。
base モデル
TensorFlow Hub の事前トレーニング済みモデルをダウンロードします。
このバージョンのモデルには、signature が 1 つあります。形状 (batch, frames, height, width, colors) の tf.float32 である image 引数を取ります。戻り値は、形状 (batch, classes) のロジットの tf.float32 テンソルです。
動画でこのシグネチャを実行するには、最初に外側の batch 次元を動画に追加する必要があります。
後で使用できるように上記の出力プロセッシングをパッケージ化する get_top_k を定義します。
logits を確率に変換し、動画の上位 5 つのクラスをルックアップします。モデルは、動画がおそらく jumping jacks であることを確定します。
streaming モデル
前のセクションでは、動画全体で実行するモデルを使用しました。最後に 1 つの予測を必要としない動画を処理する場合は通常、フレームごとに予測を更新する必要があります。これには、stream バージョンのモデルを使用できます。
stream バージョンのモデルを読み込みます。
このモデルの使用は、base モデルよりもわずかに複雑で、モデルの RNN の内部状態を追跡する必要があります。
init_states シグネチャは、動画の shape (batch, frames, height, width, colors) を入力として取り、初期の RNN 状態を含むテンソルの大型のディクショナリを返します。
RNN の初期状態を取得したら、その状態と動画のフレームを入力として渡すことができます(動画フレームの形状 (batch, frames, height, width, colors) を維持する必要があります)。モデルは (logits, state) ペアを返します。
最初のフレームを確認しただけでは、モデルは動画が「jumping jacks」であることに納得しません。
このモデルをループで実行し、フレームごとに更新された状態を渡すと、すぐに正しい結果に収束します。
最終的な確率が、base モデルを実行した前のセクションよりもはるかに確実であることに気づくことでしょう。base モデルは複数のフレームに対する予測の平均を返します。
経時的な予測をアニメーション化する
前のセクションでは、これらのモデルの使用方法について詳しく説明しました。このセクションではそれを基に、推論アニメーションを生成していきます。
以下の非表示セルは、このセクションで使用されるヘルパー関数を定義します。
動画のフレーム全体に streaming モデルを実行し、ロジットを収集することから始めます。
確率のシーケンスを動画に変換します。
参考資料
事前トレーニング済みのモデルは TF Hub から利用できます。TF Hub コレクションには、TFLite 用に最適化された量子化モデルも含まれています。
これらのモデルのソースは TensorFlow Model Garden にあり、MoviNet モデルの構築とファインチューニングもカバーしたこのチュートリアルの長編が含まれています。
次のステップ
TensorFlow での動画の操作についての詳細は、以下のチュートリアルをご覧ください。
動画データを読み込む
MoviNet を使った動画分類の転移学習