
Path: blob/master/site/ja/tutorials/customization/custom_training_walkthrough.ipynb
38471 views
Copyright 2018 The TensorFlow Authors.
カスタム訓練:ウォークスルー
 GitHub でソースを表示
GitHub でソースを表示このチュートリアルでは、カスタムトレーニングループを使って機械学習モデルをトレーニングし、ペンギンを種類別に分類する方法を説明します。このノートブックでは、TensorFlow を使用して、次の項目を達成します。
データセットをインポートする
単純な線形モデルを構築する
モデルをトレーニングする
モデルの有効性を評価する
トレーニングされたモデルを使用して予測を立てる
TensorFlow プログラミング
このチュートリアルでは、次の TensorFlow プログラミングタスクを実演しています。
TensorFlow Datasets API を使ってデータをインポートする
Keras API を使ってモデルとレイヤーを構築する
ペンギンの分類の問題
鳥類学者が、発見したペンギンを自動的に分類する方法を探していると仮定しましょう。機械学習では、ペンギンを静的に分類するためのアルゴリズムが多数用意されています。たとえば、高度な機械学習プログラムでは、写真を基にペンギンを分類できるものもあります。このチュートリアルで作成するモデルは、これよりも少しシンプルで、体重、フリッパーの長さ、くちばし、特に 嘴峰(しほう)の長さと幅に基づいてペンギンを分類します。
ペンギンには 18 種ありますが、このチュートリアルでは次の 3 種のみを分類してみることにしましょう。
ヒゲペンギン
ジェンツーペンギン
アデリーペンギン

幸いにも、体重、フリッパーの長さ、くちばしの測定値とその他のデータで含む334 羽のペンギンのデータセットが調査チームによって既に作成されて共有されています。このデータセットは、penguins TensorFlow Dataset としても提供されています。
セットアップ
penguis データセットに使用する tfds-nightly パッケージをインストールします。tfds-nightly パッケージは毎晩リリースされる TensorFlow Datasets(TFDS)のバージョンです。TFDS の詳細については、TensorFlow Datasets の概要をご覧ください。
次に、Colab メニューから Runtime > Restart Runtime を選択して、Colab ランタイムを再起動します。
ランタイムを再起動せずに、チュートリアルを先に進めないでください。
TensorFlow と他に必要な Python モジュールをインポートします。
データセットをインポートする
デフォルトの penguins/processed TensorFlow Dataset はすでにクリーニングされて正規化が済んでおり、モデルを構築できる準備が整っています。processed データをダウンロードする前に、簡易バージョンをプレビューして、元のペンギン調査データを理解しておきましょう。
このデータセットでは、ペンギンの種のラベルを数値で表現することにより、構築するモデルで扱いやすくしています。これらの数値は、次のペンギンの種に対応しています。
0: アデリーペンギン1: ヒゲペンギン2: ジェンツーペンギン
この順序で、ペンギンの種名を含むリストを作成します。このリストは、分類モデルの出力を解釈するために使用します。
特徴量とラベルについての詳細は、機械学習クラッシュコースの ML 用語セクションをご覧ください。
前処理済みのデータセットをダウンロードする
次に、tfds.load メソッドを使用して、前処理済みの penguins データセット(penguins/processed)をダウンロードします。すると、tf.data.Dataset オブジェクトのリストが返されます。penguins/processed データセットには独自のテストセットは用意されていないため、80:20 分割で、トレーニングセットとテストセットにデータセットをスライスします。テストデータセットは、後でモデルを検証する際に使用します。
このバージョンのデータセットは処理済みであるため、データが 4 つの正規化された特徴量と種ラベルに縮小されていることに注意してください。このフォーマットでは、データを素早く使用してモデルをトレーニングできるようになっているため、移行の処理は必要ありません。
バッチのいくつかの特徴量をプロットして、クラスターを可視化できます。
単純な線形モデルを構築する
なぜモデルか?
*モデル*は、特徴量とラベルの関係です。ペンギンの分類問題においては、このモデルは体重、フリッパー、および嘴峰の測定値、および予測されるペンギンの種の関係を定義しています。単純なモデルは、数行の代数で記述することは可能ですが、複雑な機械学習モデルにはパラメータの数も多く、要約が困難です。
機械学習を使用せずに、4 つの特徴量とペンギンの種の関係を判定することはできるのでしょうか。つまり、従来のプログラミング手法(多数の条件ステートメントを使用するなど)を使って、モデルを作成できるのでしょうか。おそらく、体重と嘴峰の測定値の関係を特定できるだけの長い時間を費やしてデータセットを分析すれば、特定の種に絞ることは可能かもしれません。これでは、複雑なデータセットでは不可能でなくとも困難極まりないことでしょう。適した機械学習アプローチであれば、ユーザーに代わってモデルを判定することができます。代表的なサンプルを適確な機械学習モデルタイプに十分にフィードすれば、プログラムによって関係を見つけ出すことができます。
モデルの選択
次に、トレーニングするモデルの種類を選択する必要があります。選択できる種類は多数あり、最適な種類を 1 つ選ぶにはそれなりの経験が必要となります。このチュートリアルでは、ニューラルネットワークを使用して、ペンギンの分類問題を解決することにします。ニューラルネットワークは、特徴量とラベルの複雑な関係を見つけ出すことができます。非常に構造化されたグラフで、1 つ以上の非表示レイヤーで編成されており、各非表示レイヤーは 1 つ以上のニューロンで構成されています。ニューラルネットワークにはいくつかのカテゴリがありますが、このプログラムでは、Dense または全結合のニューラルネットワークを使用します。このネットワークでは、1 つのレイヤーのニューロンが前のレイヤーのすべてのユーロんから入力接続を受け取ります。たとえば、図 2 では、1 つの入力レイヤー、2 つの非表示レイヤー、および 1 つの出力レイヤーで構成される Dense ニューラルネットワークが示されています。
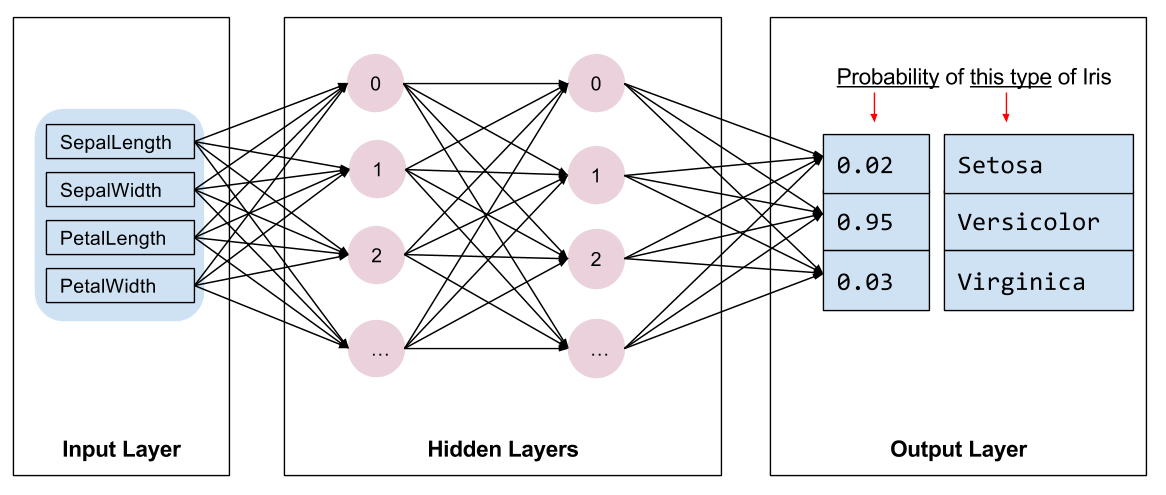 |
| 図2. 特徴量と隠れ層、予測をもつニューラルネットワーク {nbsp} |
図 2 のモデルをトレーニングし、ラベルなしのサンプルをフィードすると、このペンギンが特定のペンギン種であるという尤度によって 3 つの予測が生成されます。この予測は推論と呼ばれます。この例では、出力予測の和は 1.0 です。図 2 の場合、この予測は、アデリーは 0.02、ヒゲペンギンは 0.95、ジェンツーは 0.03 となります。つまり、モデルは、95% の確率で、ラベル無しのサンプルペンギンはヒゲペンギンであると予測していることになります。
Keras を使ったモデル構築
TensorFlow の tf.keras API は、モデルと層を作成するためのおすすめの方法です。Keras がすべてを結びつけるという複雑さを引き受けてくれるため、モデルや実験の構築がかんたんになります。
tf.keras.Sequential モデルは、レイヤーの線形スタックです。コンストラクタはレイヤーインスタンスのリスト(この場合は 2 つの tf.keras.layers.Dense レイヤー、各レイヤーの 10 個のノード、ラベルの予測である 3 つのノードを持つ出力レイヤー)を取ります。最初のレイヤーの input_shape パラメータはデータセットの特徴量の数に対応しており、必須です。
活性化関数(activation function) は、そのレイヤーの各ノードの出力の形を決定します。この関数の非線形性は重要であり、それがなければモデルは 1層しかないものと等価になってしまいます。利用可能な活性化関数 はたくさんありますが、隠れ層では ReLU が一般的です。
理想的な隠れ層の数やニューロンの数は問題やデータセットによって異なります。機械学習のさまざまな側面と同様に、ニューラルネットワークの最良の形を選択するには、知識と経験の両方が必要です。経験則から、一般的には隠れ層やニューロンの数を増やすとより強力なモデルを作ることができますが、効果的に訓練を行うためにより多くのデータを必要とします。
モデルを使用する
それでは、このモデルが特徴量のバッチに対して何を行うかを見てみましょう。
ご覧のように、サンプルのそれぞれは、各クラスの ロジット(logit) 値を返します。
これらのロジット値を各クラスの確率に変換するためには、 softmax 関数を使用します。
クラスに渡って tf.math.argmax を取ると、クラスのインデックスの予測を得られますが、モデルはまだトレーニングされていないため、これは良い予測ではありません。
モデルの訓練
訓練(Training) は、機械学習において、モデルが徐々に最適化されていく、あるいはモデルがデータセットを学習する段階です。目的は、見たことのないデータについて予測を行うため、訓練用データセットの構造を十分に学習することです。訓練用データセットを学習しすぎると、予測は見たことのあるデータに対してしか有効ではなく、一般化できません。この問題は 過学習(overfitting) と呼ばれ、問題の解き方を理解するのではなく答えを丸暗記するようなものです。
ペンギンの分類問題は、教師あり機械学習の例であり、モデルはラベルを含むサンプルからトレーニングされています。サンプルにラベルを含まない場合は、教師なし機械学習と呼ばれ、モデルは通常、特徴量からパターンを見つけ出します。
損失と勾配関数を定義する
トレーニングと評価の段階では、モデルの損失を計算する必要があります。これは、モデルの予測がどれくらい目標から外れているかを測定するものです。言い換えると、モデルのパフォーマンスがどれくらい劣っているかを示します。この値を最小化または最適化することが望まれます。
モデルは、モデルのクラスの確率予測と目標のラベルを取り、サンプル間の平均的な損失を返す tf.keras.losses.SparseCategoricalCrossentropy 関数を使用して損失を計算します。
tf.GradientTape コンテキストを使って、モデルを最適化する際に使われる 勾配(gradients) を計算しましょう。
オプティマイザの作成
オプティマイザは、loss 関数を最小化するために、計算された勾配をモデルのパラメータに適用します。損失関数は、曲面(図 3 を参照)として考えることができ、その周辺を探りながら最低ポイントを見つけることができます。勾配は最も急な上昇に向かってポイントするため、逆方向に進んで曲面を下方向に移動します。バッチごとに損失と勾配を対話的に計算することで、トレーニング中にモデルの調整を行うことができます。モデルは徐々に、重みとバイアスの最適な組み合わせを見つけて損失を最小化できるようになります。損失が低いほど、モデルの予測が最適化されます。
 |
| 図3. 3次元空間における最適化アルゴリズムの時系列可視化。 (Source: Stanford class CS231n, MIT License, Image credit: Alec Radford) |
TensorFlow には、トレーニングに使用できる多数の最適化アルゴリズムが用意されています。このチュートリアルでは、確率的勾配降下法(SGD)アルゴリズムを実装する tf.keras.optimizers.SGD を使用しています。learning_rate パラメータは、曲面を下降するイテレーションごとに取るステップサイズを設定します。このレートは、一般的により良い結果を達成できるように調整するハイパーパラメータです。
オプティマイザを 0.01 の学習率でインスタンス化します。これはトレーニングのイテレーションごとに、勾配が操作するスカラー値です。
次に、このオブジェクトを使用して、1 つの最適化ステップを計算します。
訓練ループ
すべての部品が揃ったので、モデルの訓練ができるようになりました。訓練ループは、モデルにデータセットのサンプルを供給し、モデルがよりよい予測を行えるようにします。下記のコードブロックは、この訓練のステップを構成します。
epoch(エポック) をひとつずつ繰り返します。エポックとは、データセットをひととおり処理するということです。
エポック内では、訓練用の
Dataset(データセット)のサンプルひとつずつから、その features(特徴量) (x) と label(ラベル) (y) を取り出して繰り返し処理します。サンプルの特徴量を使って予測を行い、ラベルと比較します。予測の不正確度を測定し、それを使ってモデルの損失と勾配を計算します。
optimizerを使って、モデルのパラメータを更新します。可視化のためにいくつかの統計量を記録します。
これをエポックごとに繰り返します。
num_epochs 変数は、データセットコレクションをループする回数です。以下のコードでは、num_epochs は 201 に設定されているため、このトレーニングループは 201 回実行します。直感に反し、モデルをより長くトレーニングしても、モデルがさらに最適化されることは保証されません。num_epochs は、ユーザーが調整できるハイパーパラメータです。通常、適切な数値を選択するには、経験と実験の両方が必要です。
または、組み込みの Keras Model.fit(ds_train_batch) メソッドを使用して、モデルをトレーニングすることもできます。
時間の経過に対する損失関数の可視化
モデルのトレーニングの進行状況を出力することは役立ちますが、TensorFlow に同梱された TensorBoard という可視化とメトリクスツールを使って進行状況を可視化することもできます。この単純な例では、matplotlib モジュールを使用して基本的なグラフを作成できます。
これらのグラフを解釈するには経験が必要ですが、一般的に、損失の減少と精度の上昇に注目できます。
モデルの有効性評価
モデルがトレーニングが完了したため、パフォーマンスの統計を取得できるようになりました。
評価とは、モデルがどれくらい効果的に予測を立てられるかを判定することです。ペンギンの分類においてモデルの有効性を判定するには、測定値をモデルに渡し、それが表すペンギンの種をモデルに問います。次に、モデルの予測を実際のラベルと比較します。たとえば、入力サンプルの半数で正しい種を選択したモデルであれば、その精度は 0.5 となります。図 4 には、わずかに有効性の高いモデルが示されており、80% の精度で、5 回の予測の内 4 回が正解となっています。
| サンプルの特徴量 | ラベル | モデルの予測値 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| 図 4. 80% 正確なペンギンの分類器 |
テストセットをセットアップする
モデルの評価はモデルの訓練と同様です。もっとも大きな違いは、サンプルが訓練用データセットではなくテスト用データセット(test set) からのものであるという点です。モデルの有効性を正しく評価するには、モデルの評価に使うサンプルは訓練用データセットのものとは違うものでなければなりません。
penguin データセットには、別途テストデータセットが用意されていないため、当然、前述のデータセットのダウンロードセクションのデータセットにもテストデータセットはありません。そこで、元のデータセットをテストデータセットとトレーニングデータセットに分割します。評価には、ds_test_batch データセットを使用してください。
テスト用データセットでのモデルの評価
トレーニングの段階とは異なり、このモデルはテストデータの 1 つのエポックしか評価しません。次のコードはテストセットの各サンプルを反復し、モデルの予測を実際のラベルに比較します。この比較は、テストセット全体におけるモデルの精度を測定するために使用されます。
また、model.evaluate(ds_test, return_dict=True) Keras 関数を使用して、テストデータセットの精度情報を取得することもできます。
たとえば、最後のバッチを調べて、モデルの予測が通常正しい予測であることを観察することができます。
訓練済みモデルを使った予測
モデルをトレーニングし、ペンギンの種を分類する上でモデルが良好であることを「証明」しました(ただし、完璧ではありません)。では、トレーニング済みのモデルを使用して、ラベルなしのサンプル、つまりラベルのない特徴量を含むサンプルで予測を立ててみましょう。
実際には、ラベルなしのサンプルは、アプリ、CSV ファイル、データフィードといったさまざまなソースから取得される場合がありますが、このチュートリアルでは、ラベルなしのサンプルを手動で提供して、それぞれのラベルを予測することにします。ラベル番号は、次のように指定されていることを思い出してください。
0: アデリーペンギン1: ヒゲペンギン2: ジェンツーペンギン