
Path: blob/master/site/ja/tutorials/load_data/video.ipynb
38270 views
Copyright 2022 The TensorFlow Authors.
動画データを読み込む
 GitHub でソースを表示
GitHub でソースを表示このチュートリアルでは、UCF101 人間行動データセットを使用して AVI 動画データを読み込んで前処理する方法を実演します。データを前処理すると、動画の分類/認識、キャプション、クラスタリングなどのタスクに使用できます。元のデータセットには、チェロの演奏、歯磨き、アイメイクなど、YouTube から収集された 101 のカテゴリのリアルなアクション動画が含まれています。このチュートリアルでは以下を見ていきます。
zip ファイルからデータを読み込む。
動画ファイルから一連のフレームを読み取る。
動画データを視覚化する。
フレームジェネレータ
tf.data.Datasetをラップする。
この動画読み込みと前処理チュートリアルは、TensorFlow 動画チュートリアルシリーズの一部です。他に、以下の 3 つのチュートリアルがあります。
動画分類用の 3D CNN モデルを構築する: このチュートリアルは、3D データの空間と時間の側面を分解する (2+1)D CNN が使用されています。MRI スキャンなどの体積データを使用している場合は、(2+1)D CNN ではなく、3D CNN を使用することを検討してください。
MoviNet でストリーミングの行動認識を実行する: TF Hub で提供されている MoviNet モデルについて説明されています。
MoviNet を使った動画分類の転移学習: このチュートリアルでは、異なるデータセットで事前にトレーニングされた動画分類モデルを UCF-101 データセットで使用する方法を説明します。
セットアップ
まず、ZIP ファイルの内容を検査するための remotezip、進捗バーを使用するための tqdm、動画ファイルを処理するための OpenCV、Jupyter ノートブックにデータを埋め込むための tensorflow_docs などの必要なライブラリをインストールしてインポートします。
UCF101 データセットのサブセットをダウンロードする
UCF101 データセットには、101 カテゴリの動画内のさまざまなアクションが含まれており、主にアクション認識で使用されます。 このデモでは、これらのカテゴリのサブセットを使用します。
上記の URL には、UCF 101 データセットの zip ファイルが含まれています。remotezip ライブラリを使用してその URL の zip ファイルの内容を調べる関数を作成します。
いくつかの動画とトレーニング用の限られた数のクラスから始めます。上記のコードブロックを実行した後、クラス名が各動画のファイル名に含まれていることに注意してください。
ファイル名からクラス名を取得する get_class 関数を定義します。次に、すべてのファイル(上記の files)のリストを各クラスのファイルをリストするディクショナリに変換する get_files_per_class という関数を作成します。
クラスごとのファイルのリストを取得したら、データセットを作成するために、使用するクラスの数と、クラスごとに必要な動画の数を選択します。
データセット内に存在するクラスのサブセットと、クラスごとに特定の数のファイルを選択する select_subset_of_classes という新しい関数を作成します。
動画をトレーニングセット、検証セット、およびテストセットに分割するヘルパー関数を定義します。動画は zip ファイルを含む URL からダウンロードされ、それぞれのサブディレクトリに配置されます。
次の関数は、まだデータのサブセットに配置されていない残りのデータを返します。残りのデータを次に指定されたデータのサブセットに配置します。
次の download_ucf_101_subset 関数を使用すると、UCF101 データセットのサブセットをダウンロードして、トレーニングセット、検証セット、テストセットに分割できます。使用するクラスの数を指定できます。splits 引数を使用すると、ディクショナリを渡すことができます。ディクショナリの主な値はサブセットの名前(例: 「トレーニング」)とクラスごとの動画の数です。
データをダウンロードすると、UCF101 データセットのサブセットのコピーが作成されます。次のコードを実行して、データのすべてのサブセットの中にある動画の総数を出力します。
また、データ ファイルのディレクトリをプレビューすることもできます。
各動画ファイルからフレームを作成する
frames_from_video_file 関数は、動画をフレームに分割し、動画ファイルからランダムに選択された n_frames のスパンを読み取り、それらを NumPy array として返します。メモリと計算のオーバーヘッドを削減するには、小さいフレーム数を選択してください。さらに、各動画から同じ数のフレームを選択すると、データのバッチ処理が容易になります。
動画データを視覚化する
一連のフレームを NumPy 配列として返す frames_from_video_file 関数。Patrick Gillett による Wikimedia{:.external} の新しい動画でこの関数を使用してみてください。
この動画を調べるだけでなく、UCF-101 データを表示することもできます。これを行うには、次のコードを実行します。
次に、TensorFlow データパイプラインにデータをフィードするイテラブルオブジェクトを作成するために、FrameGenerator クラスを定義します。ジェネレーター (__call__)関数は、frames_from_video_file によって生成されたフレーム配列と、一連のフレームに関連付けられたラベルのワンホットエンコードされたベクトルを生成します。
TensorFlow Dataset としてラップする前に FrameGenerator オブジェクトをテストします。またトレーニングデータセットについては、データがシャッフルされるように、トレーニングモードを必ず有効にしてください。
最後に、TensorFlow データ入力パイプラインを作成します。ジェネレーターオブジェクトから作成するこのパイプラインを使用すると、ディープラーニングモデルにデータをフィードできます。この動画パイプラインでは、各要素はフレームとそれに関連付けられたラベルの 1 つのセットです。
ラベルがシャッフルされてたことを確認します。
データセットを構成してパフォーマンスを改善する
I/O がブロックされることなくディスクからデータを取得できるように、バッファ付きプリフェッチを使用します。以下の 2 つの関数は、データを読み込むときに使用する必要がある重要な方法です。
Dataset.cacheは、最初のエポック中に画像をディスクから読み込んだ後、メモリに保持します。これにより、モデルのトレーニング中にデータセットがボトルネックになることを回避できます。データセットが大きすぎてメモリに収まらない場合は、この方法を使用して、パフォーマンスの高いオンディスクキャッシュを作成することもできます。Dataset.prefetchは、トレーニング中にデータの前処理とモデルの実行をオーバーラップさせます。詳しくは、tf.dataによるパフォーマンスの向上を参照してください。
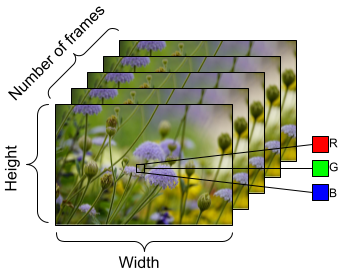
モデルにフィードするデータを準備するには、以下に示すようにバッチ処理を使用します。AVI ファイルなどの動画データを扱う場合、データを [batch_size, number_of_frames, height, width, channels] の5 次元オブジェクトの形状にする必要があることに注意してください。対照的に、画像には [batch_size, height, width, channels] の 4 つの次元があります。下の画像は、動画データの形状がどのように表現されるかを示したものです。
次のステップ
ここで作成したラベル付きの動画フレームの TensorFlow Dataset はディープラーニングモデルで使用できます。事前トレーニング済みの EfficientNet{:.external} を使用する次の分類モデルは、数分で高精度にトレーニングされます。
TensorFlow での動画の操作についての詳細は、以下のチュートリアルをご覧ください。