
Path: blob/master/site/ja/tutorials/text/image_captioning.ipynb
38323 views
Copyright 2018 The TensorFlow Authors.
<style> td { text-align: center; } th { text-align: center; } </style>
ビジュアルアテンションを用いた画像キャプショニング
 GitHub でソースを表示
GitHub でソースを表示以下の例のような画像が与えられた場合、目標は「波に乗っているサーファー」などのキャプションを生成することです。
 |
| サーフィンしている男性(出典: wikimedia) |
|---|
ここで使用されているモデルアーキテクチャは、「Show, Attend and Tell: Neural Image Caption Generation with Visual Attention」からアイデアを得たものですが、2 レイヤー Transformer デコーダを使用するように更新されています。このチュートリアルを最大限に活用するには、テキスト生成、seq2seq モデルとアテンション、または transformer の使用経験があるとよいでしょう。
以下は、このチュートリアルに組み込まれるモデルアーキテクチャです。特徴量は画像から抽出され、Transformer デコーダのクロスアテンションレイヤーに渡されています。
| モデルアーキテクチャ |
|---|
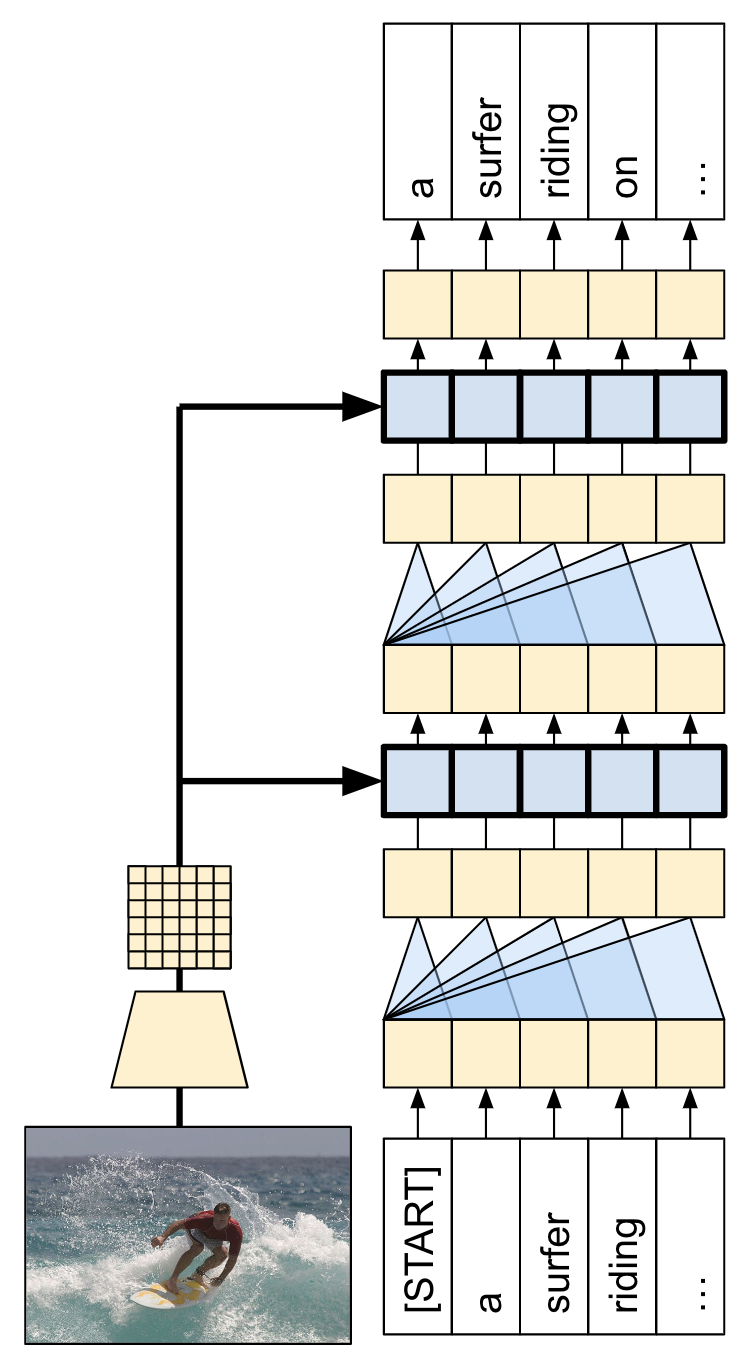 |
Transformer デコーダは主に、アテンションレイヤーから構築されます。セルフアテンションを使用して、生成されるシーケンスを処理し、クロスアテンションを使用して、画像に注意を向けます。
クロスアテンションレイヤーのアテンションの重みを検査することで、モデルが単語を生成する過程で、モデルが画像のどの部分を見ているかを知ることができます。
このノートブックは、エンドツーエンドの例を示します。このノートブックを実行すると、データセットのダウンロード、画像特徴量の抽出とキャッシュ処理、そしてデコーダモデルのトレーニングが行われます。その後で、モデルを使用して、新しい画像のキャプションが生成されるようになります。
セットアップ
このチュートリアルでは多数の import を使用します。ほとんどがデータセットの読み込み目的です。
[オプション] データ処理
このセクションでは、captions データセットをダウンロードして、トレーニングの準備を行います。入力テキストをトークン化し、事前トレーニング済みの特徴量抽出器モデルを通じてすべての画像の実行結果をキャッシュします。このセクションの内容を完全に理解することは重要ではありません。
データセットを選択する
このチュートリアルは、データセットの選択肢を提供するようにセットアップされています。Flickr8k、または Conceptual Captions データセットの小さなスライスのいずれかを選択します。これらはゼロからダウンロードして変換されますが、TensorFlow Datasets で提供されている Coco Captions と完全な Conceptual Captions というキャプションデータセットを使用するようにチュートリアルを変更することは困難ではありません。
Flickr8k
Conceptual Captions
データセットをダウンロードする
Flickr8k には 1 つの画像につき 5 つのキャプションが含まれているため、より小さなダウンロードサイズでより多くのデータを得られる良い選択肢と言えます。
上記のいずれのデータセットのローダーも、(image_path, captions) ペアを含む tf.data.Dataset を返します。Flickr8k データセットには 1 つの画像につき 5 つのキャプションが含まれているのに対し、Conceptual Captions のキャプションは 1 つです。
画像特徴量抽出器
画像モデル(imagenet で事前トレーニング済み)を使用して各画像から特徴量を抽出します。このモデルは画像分類器としてトレーニングされていますが、設定 include_top=False は最終的な分類レイヤーなしのモデルを返すため、特徴量マップの最後のレイヤーを使用できます。
以下は、画像を読み込んでモデルに合わせてサイズを変更する関数です。
モデルは、入力バッチで各画像の特徴量マップを返します。
テキストトークナイザ/ベクタナイザをセットアップする
次の手順で、TextVectorization レイヤーを使用して、テキストキャプションを整数シーケンスに変換します。
adapt を使用して、すべてのキャプションをイテレートし、キャプションを単語に分割して、上位の単語の語彙を計算します。
各単語を語彙のインデックスにマッピングして、すべてのキャプションをトークン化します。すべての出力シーケンスは、長さ 50 までパディングされます。
結果を表示するために、単語からインデックスおよびインデックスから単語へのマッピングを作成します。
データセットを準備する
train_raw と test_raw データセットには、一対多の (image, captions) ペアが含まれます。
この関数は、画像とキャプションが 1:1 になるように、画像を複製します。
Keras トレーニングと互換性を持たせるため、データセットには (inputs, labels) ペアを含める必要があります。テキスト生成では、トークンは、入力とラベルのいずれでもあり、1 ステップずつシフトされます。この関数は、(images, texts) ペアを ((images, input_tokens), label_tokens) ペアに変換します。
この関数は、以下の手順でデータセットに演算を追加します。
画像を読み込みます(読み込みに失敗する画像は無視されます)。
キャプションの数に合わせて画像を複製します。
image, captionペアをシャッフルして再バッチ化します。テキストをトークン化し、トークンをシフトして
label_tokensを追加します。RaggedTensor表現のテキストをパディング付きの高密度Tensor表現に変換します。
以下のようにして、特徴量抽出器をモデルにインストールし、データセットでトレーニングすることが可能です。
[オプション] 画像特徴量をキャッシュする
画像特徴量抽出器には変化がなく、このチュートリアルでは画像拡張を使用していないため、画像特徴量をキャッシュすることができます。テキストトークン化についても同様です。キャッシュをセットアップするのに時間がかかりますが、その時間は、トレーニングと検証中に、各エポックで取り返すことができます。以下のコードでは、save_dataset と load_dataset の 2 つの関数を定義しています。
トレーニングの準備が完了したデータ
前処理手順が完了したら、データセットは以下のようになります。
このデータセットは、Keras でのトレーニングに適した (input, label) ペアを返すようになりました。inputs は (images, input_tokens) ペアです。images は特徴量抽出器モデルで処理が完了しています。input_tokens の各場所では、モデルはそれまでのテキストを見て、labels 内の同じ位置に並んでいる次のテキストを予測しようとします。
入力トークンとラベルは、1 ステップずつシフトしているだけで、同じです。
Transformer デコーダモデル
このモデルは、事前トレーニング済みの画像エンコーダが十分であることを前提としているため、テキストエンコーダの構築のみに焦点を当てています。このチュートリアルでは 2 レイヤーの Transformer デコーダを使用します。
実装は、Transformers チュートリアルとほぼ同一です。詳細は、そちらをご覧ください。
| Transformer エンコーダとデコーダ |
|---|
| |
モデルは、主に以下の 3 つのパーツで実装されます。
入力 - トークン埋め込みと位置エンコーディング(
SeqEmbedding)。デコーダ - Transformer デコーダレイヤーのスタック(
DecoderLayer)で、それぞれに以下が含まれます。カジュアルなセルフアテンションレイヤー(
CausalSelfAttention)。出力の各場所はそれまでの出力に注目します。クロスアテンションレイヤー(
CrossAttention)。出力の各場所は入力画像に注目します。フィードフォワードネットワーク(
FeedForward)レイヤー。各出力場所をさらに個別に処理します。
出力 - 出力語彙に対するマルチクラス分類。
入力
入力テキストはすでにトークンに分割され、ID のシーケンスに変換されています。
CNN や RNN とは異なり、Transformer のアテンションレイヤーは、シーケンスの順序に対して不変であることを思い出しましょう。なんらかの位置入力がないと、シーケンスではなく順序付けられていないセットが表示されます。そのため、Embedding レイヤーには、各トークンの単純なベクトル埋め込みの他に、シーケンスの各位置の埋め込みも含められます。
SeqEmbedding レイヤーは以下のように定義されています。
各トークンの埋め込みベクトルをルックアップします。
各シーケンス位置の埋め込みベクトルをルックアップします。
その両方を追加します。
mask_zero=Trueを使用して、モデルの keras-masks を初期化します。
注意: この実装は、Transformer チュートリアルのように固定埋め込みを使用する代わりに、位置埋め込みを学習します。埋め込みの学習ではコードがわずかに少なくなりますが、より長いシーケンスには一般化されません。
デコーダ
デコーダは標準的な Transformer デコーダで、それぞれに CausalSelfAttention、CrossAttention、および FeedForward-decoder の 3 つのサブレイヤーを含む DecoderLayers のスタックが含まれます。実装は Transformer チュートリアルとほぼ同一であるため、詳細はそちらをご覧ください。
以下は、CausalSelfAttention レイヤーです。
以下は、CrossAttention レイヤーです。return_attention_scores の使用に注意してください。
以下は、FeedForward レイヤーです。layers.Dense レイヤーは入力の最後の軸に適用されることを思い出しましょう。入力は (batch, sequence, channels) の形状になるため、batch と sequence 軸にポイントワイズが自動的に適用されます。
次に、これらの 3 つのレイヤーをより大きな DecoderLayer に配置します。各デコーダレイヤーは、3 つの小さなレイヤーをシーケンスで適用します。各サブレイヤーの後、out_seq の形状は (batch, sequence, channels) になります。デコーダレイヤーは、後で可視化できる attention_scores も返します。
出力
最低でも、出力レイヤーには、各位置で各トークンのロジット予測を生成するための layers.Dense レイヤーが必要です。
しかし、この動作を少しでも改良するために追加できる他の特徴量は少ししかありません。
不正なトークンを処理する: モデルはテキストを生成します。パディング、不明、または開始トークン(
''、'[UNK]'、'[START]')を絶対に生成してはいけません。したがって、これらのバイアスは大きな負の値に設定します。注意: これらのトークンは、損失関数ででも無視する必要があります。
スマート初期化: 高密度レイヤーのデフォルトの初期化では、最初にほぼ一様の尤度で各トークンを予測するモデルが得られます。実際のトークン分布は一様からはほど遠いものです。出力レイヤーの初期バイアスの最適な値は、各トークンの確率の対数です。したがって、
adaptメソッドを含めてトークンをカウントし、最適な初期バイアスを設定します。こうすることで、初期損失が一様分布のエントロピー(log(vocabulary_size))から分布の限界エントロピー(-p*log(p))に減少します。
スマート初期化によって、初期損失をが大幅に減少します。
モデルを構築する
モデルを構築するには、複数のパーツを組み合わせる必要があります。
画像
feature_extractorとテキストtokenizer。seq_embeddingレイヤー。トークン ID のバッチをベクトル(batch, sequence, channels)に変換します。テキストと画像データを処理する
DecoderLayersレイヤーのスタック。output_layer。次の単語のポイントワイズの予測を返します。
トレーニングにモデルを呼び出すと、image, txt ペアが返されます。この関数をさらに使いやすくするために、入力について柔軟になりましょう。
画像に 3 つのチャンネルがある場合、feature_extractor に通します。そうでない場合は、すでに通過済みであることを前提とします。
テキストに dtype
tf.stringがある場合、tokenizer に通します。
その後のモデルの実行はほんの数ステップです。
抽出された画像特徴量をフラット化し、デコーダレイヤーに入力できるようにします。
トークン埋め込みをルックアップします。
画像特徴量とテキスト埋め込みで
DecoderLayerを実行します。出力レイヤーを実行して、各位置の次のトークンを予測します。
キャプションを生成する
トレーニングに進む前に、キャプションを生成するコードを記述します。これを使用して、トレーニングの進捗状況を確認します。
テスト画像のダウンロードから始めましょう。
このモデルで画像にキャプションを付けるには、以下のようにします。
img_featuresを抽出します。[START]トークンで出力トークンのリストを初期化します。img_featuresとtokensをモデルに渡します。ロジットのリストが返されます。
これらのロジットに基づいて、次のトークンを選択します。
それをトークンのリストに追加し、ループを続けます。
'[END]'トークンが生成されたら、ループを抜けます。
では、これを行うだけの「単純な」メソッドを追加しましょう。
以下は、その画像に生成されたいくつかのキャプションです。モデルはトレーニングされていないため、まだあまり意味を成しません。
temperature パラメータを使うと、3 つのモード間を補間できます。
Greedy デコーディング(
temperature=0.0)- 各ステップで最も可能性の高い次のトークンを選択します。ロジットに基づくランダムサンプリング(
temperature=1.0)。一様のランダムサンプリング(
temperature >> 1.0)。
モデルはトレーニングされていないため、また頻度ベースの初期化を使用しているため、"greedy" 出力(最初の出力)には通常、最も一般的なトークン tokens: ['a', '.', '[END]'] のみが含まれます。
トレーニング
モデルをトレーニングするには、追加コンポーネントがいくつか必要となります。
損失と指標
オプティマイザ
オプションのコールバック
損失と指標
以下は、マスクされた損失と精度の実装です。
損失のマスクを計算する際は、loss < 1e8 に注意してください。この項は、banned_tokens の人為的で、ありえないほど大きな損失を破棄します。
コールバック
トレーニング中のフィードバックでは、keras.callbacks.Callback を、サーファーの画像のキャプションを各エポックの最後に生成するようにセットアップします。
これは、前の例のような 3 つの出力文字列を生成します。前と同様に、最初に「greedy」を使用し、各ステップでロジットの argmax を選択します。
また、callbacks.EarlyStopping を使用して、モデルが過学習し始めたらトレーニングを終了するようにします。
トレーニング
トレーニングを構成して実行します。
より頻繁にレポートするには、Dataset.repeat() メソッドを使用し、steps_per_epoch と validation_steps 引数を Model.fit に設定します。
Flickr8k でこのようにセットアップすると、データセット全体の完全なパスは 900 以上のバッチですが、レポートエポックより下は 100 ステップとなります。
トレーニングランの損失と精度をプロットします。
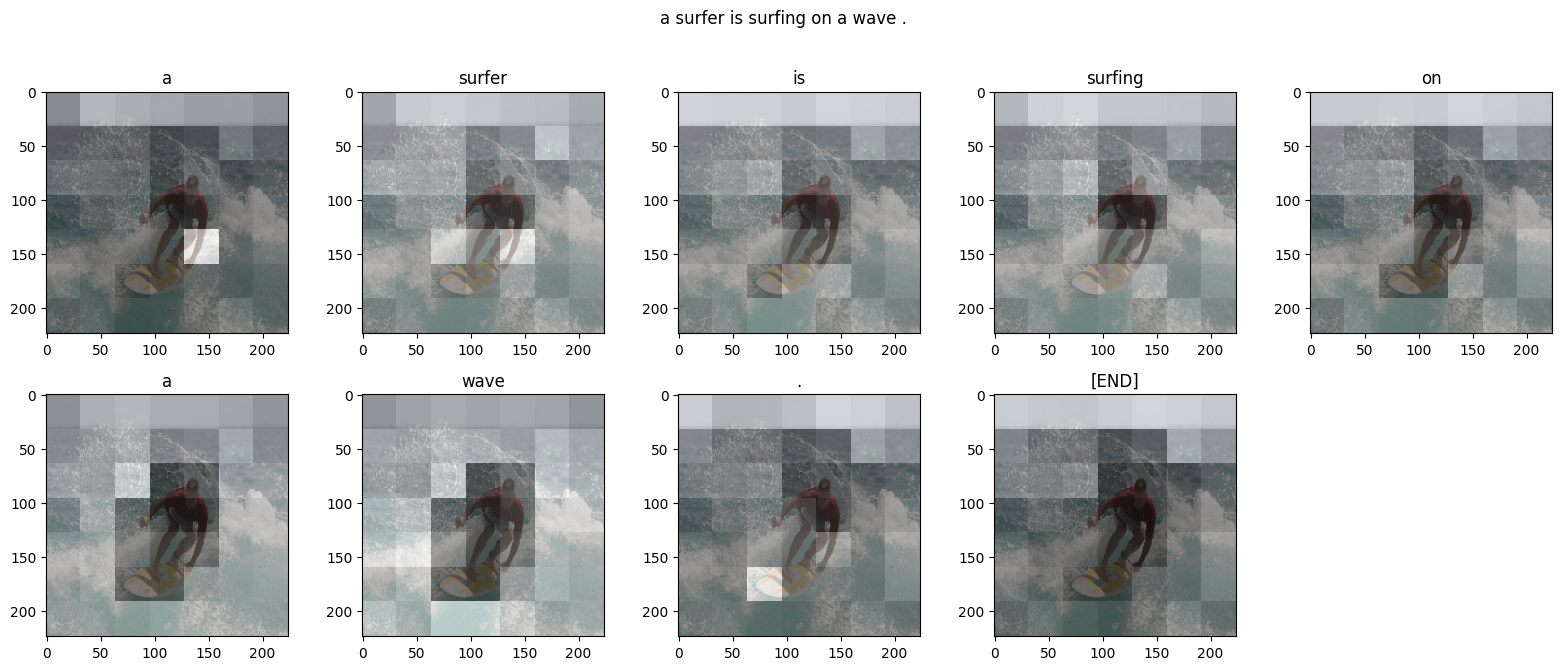
アテンションプロット
次に、トレーニング済みのモデルを使用して、画像に simple_gen メソッドを実行します。
出力をトークンに分割し直します。
DecoderLayers はそれぞれ、CrossAttention レイヤーのアテンションスコアをキャッシュします。各アテンションマップの形状は (batch=1, heads, sequence, image) です。
したがって、batch 軸に沿ってマップをスタックし、(batch, heads) 軸で平均しながら、image 軸を height, width に分割し直します。
シーケンス予測ごとに、多につのアテンションマップを得られました。各マップの値の和は 1 になります。
したがって、出力の各トークンを生成する際にモデルが注意を向けていた場所は以下です。
次に、これをより使いやすい関数にまとめます。
あなた独自の画像でためそう
トレーニングしたばかりのモデルで独自の画像にキャプションを付ける方法を以下に示します。比較的少量のデータでトレーニングされているので、使用する画像がトレーニングデータと異なることがあることに注意してください(奇妙な結果がでるかもしれません!)