
Path: blob/master/site/ja/tutorials/text/nmt_with_attention.ipynb
38578 views
Copyright 2019 The TensorFlow Authors.
アテンションを用いたニューラル機械翻訳
Note: これらのドキュメントは私たちTensorFlowコミュニティが翻訳したものです。コミュニティによる 翻訳はベストエフォートであるため、この翻訳が正確であることや英語の公式ドキュメントの 最新の状態を反映したものであることを保証することはできません。 この翻訳の品質を向上させるためのご意見をお持ちの方は、GitHubリポジトリtensorflow/docsにプルリクエストをお送りください。 コミュニティによる翻訳やレビューに参加していただける方は、 [email protected] メーリングリストにご連絡ください。
 View source on GitHub
View source on GitHubこのノートブックでは、スペイン語から英語への翻訳を行う Sequence to Sequence (seq2seq) モデルを訓練します。このチュートリアルは、 Sequence to Sequence モデルの知識があることを前提にした上級編のサンプルです。
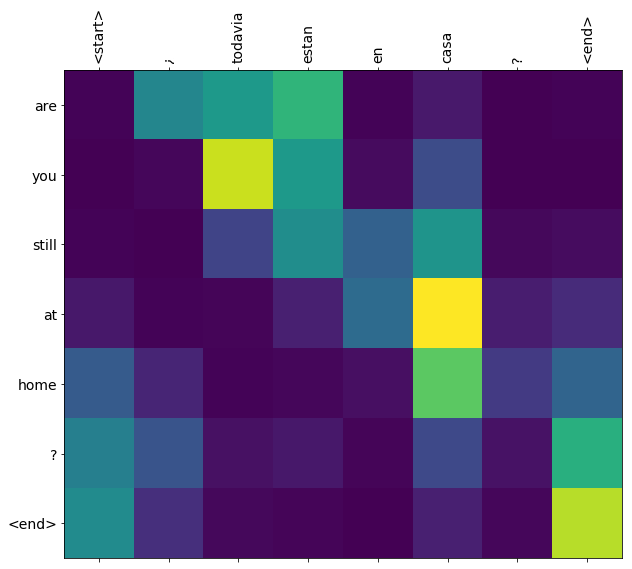
このノートブックのモデルを訓練すると、"¿todavia estan en casa?" のようなスペイン語の文を入力して、英訳: "are you still at home?" を得ることができます。
この翻訳品質はおもちゃとしてはそれなりのものですが、生成されたアテンションの図表の方が面白いかもしれません。これは、翻訳時にモデルが入力文のどの部分に注目しているかを表しています。
Note: このサンプルは P100 GPU 1基で実行した場合に約 10 分かかります。
データセットのダウンロードと準備
ここでは、http://www.manythings.org/anki/ で提供されている言語データセットを使用します。このデータセットには、次のような書式の言語翻訳ペアが含まれています。
さまざまな言語が用意されていますが、ここでは英語ースペイン語のデータセットを使用します。利便性を考えてこのデータセットは Google Cloud 上に用意してありますが、ご自分でダウンロードすることも可能です。データセットをダウンロードしたあと、データを準備するために下記のようないくつかの手順を実行します。
それぞれの文ごとに、開始 と 終了 のトークンを付加する
特殊文字を除去して文をきれいにする
単語インデックスと逆単語インデックス(単語 → id と id → 単語のマッピングを行うディクショナリ)を作成する
最大長にあわせて各文をパディングする
実験を速くするためデータセットのサイズを制限(オプション)
100,000 を超える文のデータセットを使って訓練するには長い時間がかかります。訓練を速くするため、データセットのサイズを 30,000 に制限することができます(もちろん、データが少なければ翻訳の品質は低下します)。
tf.data データセットの作成
エンコーダー・デコーダーモデルの記述
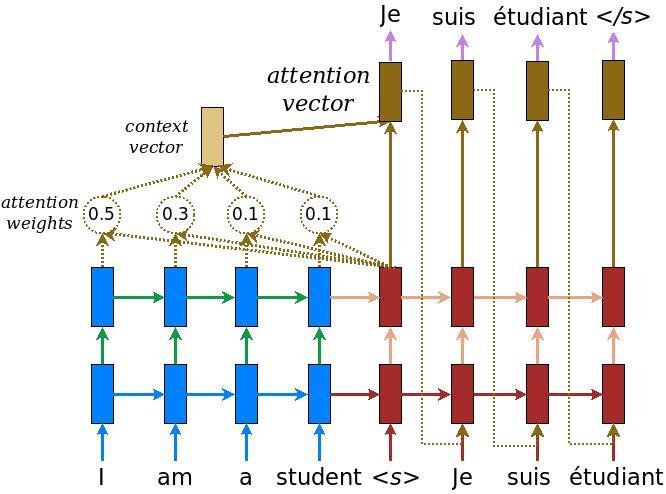
TensorFlow の Neural Machine Translation (seq2seq) tutorial に記載されているアテンション付きのエンコーダー・デコーダーモデルを実装します。この例では、最新の API セットを使用します。このノートブックは、上記の seq2seq チュートリアルにある attention equations を実装します。下図は、入力の単語ひとつひとつにアテンション機構によって重みが割り当てられ、それを使ってデコーダーが文中の次の単語を予測することを示しています。下記の図と式は Luong の論文 にあるアテンション機構の例です。
入力がエンコーダーを通過すると、shape が (batch_size, max_length, hidden_size) のエンコーダー出力と、shape が (batch_size, hidden_size) のエンコーダーの隠れ状態が得られます。
下記に実装されている式を示します。
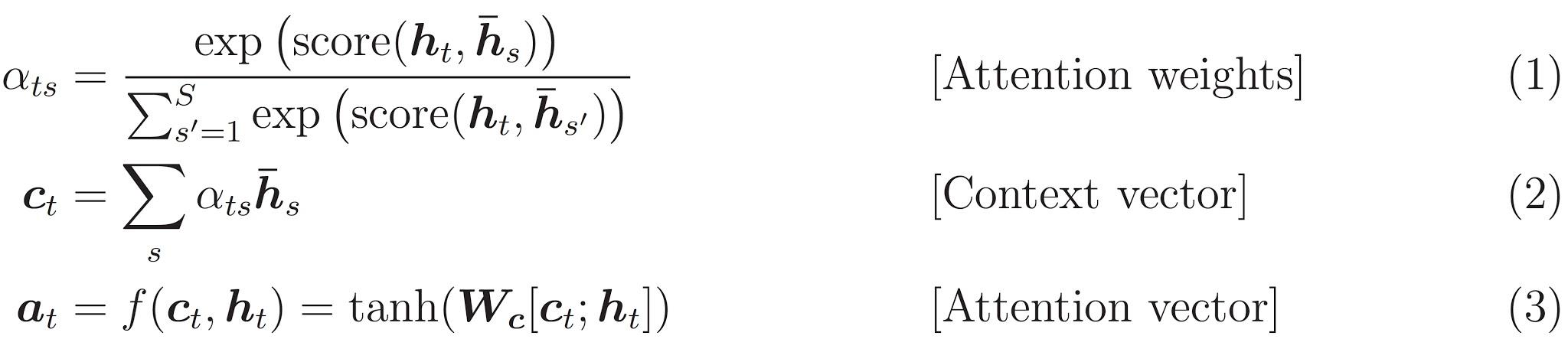
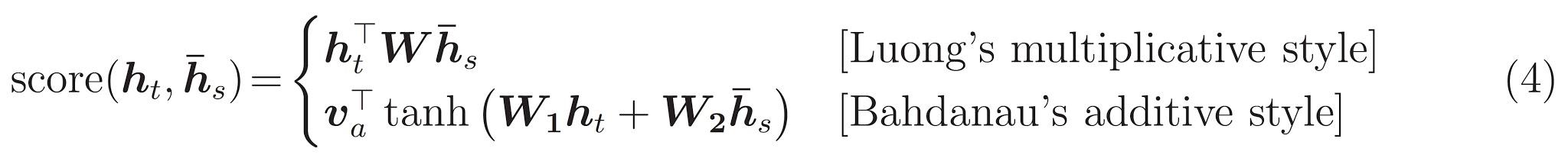
このチュートリアルでは、エンコーダーでは Bahdanau attention を使用します。簡略化した式を書く前に、表記方法を定めましょう。
FC = 全結合 (Dense) レイヤー
EO = エンコーダーの出力
H = 隠れ状態
X = デコーダーへの入力
擬似コードは下記のとおりです。
score = FC(tanh(FC(EO) + FC(H)))attention weights = softmax(score, axis = 1)softmax は既定では最後の軸に対して実行されますが、スコアの shape が (batch_size, max_length, hidden_size) であるため、最初の軸 に適用します。max_lengthは入力の長さです。入力それぞれに重みを割り当てようとしているので、softmax はその軸に適用されなければなりません。context vector = sum(attention weights * EO, axis = 1). 上記と同様の理由で axis = 1 に設定しています。embedding output= デコーダーへの入力 X は Embedding レイヤーを通して渡されます。merged vector = concat(embedding output, context vector)この結合されたベクトルがつぎに GRU に渡されます。
それぞれのステップでのベクトルの shape は、コードのコメントに指定されています。
オプティマイザと損失関数の定義
チェックポイント(オブジェクトベースの保存)
訓練
入力 を エンコーダー に通すと、エンコーダー出力 と エンコーダーの隠れ状態 が返される
エンコーダーの出力とエンコーダーの隠れ状態、そしてデコーダーの入力(これが 開始トークン)がデコーダーに渡される
デコーダーは 予測値 と デコーダーの隠れ状態 を返す
つぎにデコーダーの隠れ状態がモデルに戻され、予測値が損失関数の計算に使用される
デコーダーへの次の入力を決定するために Teacher Forcing が使用される
Teacher Forcing は、正解単語 をデコーダーの 次の入力 として使用するテクニックである
最後に勾配を計算し、それをオプティマイザに与えて誤差逆伝播を行う
翻訳
評価関数は、Teacher Forcing を使わないことを除いては、訓練ループと同様である。タイムステップごとのデコーダーへの入力は、過去の予測値に加えて、隠れ状態とエンコーダーのアウトプットである。
モデルが 終了トークン を予測したら、予測を停止する。
また、タイムステップごとのアテンションの重み を保存する。
Note: エンコーダーの出力は 1 つの入力に対して 1 回だけ計算されます。
最後のチェックポイントを復元しテストする
次のステップ
異なるデータセットをダウンロードして翻訳の実験を行ってみよう。たとえば英語からドイツ語や、英語からフランス語。
もっと大きなデータセットで訓練を行ったり、もっと多くのエポックで訓練を行ったりしてみよう。