
Path: blob/master/site/ja/tutorials/text/transformer.ipynb
38550 views
Copyright 2019 The TensorFlow Authors.
言語理解のためのTransformerモデル
 View source on GitHub
View source on GitHubNote: これらのドキュメントは私たちTensorFlowコミュニティが翻訳したものです。コミュニティによる 翻訳はベストエフォートであるため、この翻訳が正確であることや英語の公式ドキュメントの 最新の状態を反映したものであることを保証することはできません。 この翻訳の品質を向上させるためのご意見をお持ちの方は、GitHubリポジトリtensorflow/docsにプルリクエストをお送りください。 コミュニティによる翻訳やレビューに参加していただける方は、 [email protected] メーリングリストにご連絡ください。
このチュートリアルでは、ポルトガル語を英語に翻訳するTransformerモデルを訓練します。これは上級編のサンプルで、テキスト生成やアテンション(注意機構)の知識を前提としています。
Transformerモデルの背後にある中心的なアイデアはセルフアテンション(自己注意)、 つまり、シーケンスの表現を計算するために入力シーケンスの異なる位置に注意を払うことができることにあります。
Transformerモデルは、RNNsやCNNsの代わりに セルフアテンション・レイヤーを重ねたものを使って、可変長の入力を扱います。この一般的なアーキテクチャにはいくつもの利点があります。
データの中の時間的/空間的な関係を前提にしません。これは、オブジェクトの集合(例えば、StarCraftのユニット)を扱うには理想的です。
レイヤーの出力はRNNのような系列ではなく、並列に計算可能です。
たくさんのRNNのステップや畳み込み層を経ることなく、離れた要素どうしが互いの出力に影響を与えることができます(例えば、Scene Memory Transformerを参照)。
長距離の依存関係を学習可能です。これは、シーケンスを扱うタスクにおいては難しいことです。
このアーキテクチャの欠点は次のようなものです。
時系列では、あるタイムステップの出力が、入力とその時の隠れ状態だけからではなく、過去全てから計算されます。
テキストのように、入力に時間的/空間的な関係が存在する場合、何らかの位置エンコーディングを追加しなければなりません。さもなければ、モデルは実質的にバッグ・オブ・ワード(訳注:Bag of Word、含まれる単語の集合)を見ることになります。
このノートブックのモデルを訓練したあとには、ポルトガル語の文を入力し、英語の翻訳を得ることができます。
入力パイプラインの設定
TFDSを使って、TED Talks Open Translation ProjectからPortugese-English translation datasetをロードします。
このデータセットには、約50000の訓練用サンプルと、1100の検証用サンプル、2000のテスト用サンプルが含まれています。
訓練用データセットから、カスタムのサブワード・トークナイザーを作成します。
このトークナイザーは、単語が辞書にない場合には文字列をサブワードに分解してエンコードします。
入力とターゲットに開始及び終了トークンを追加します。
データセットの各要素にこの関数を適用するために、Dataset.mapを使いたいと思います。Dataset.mapはグラフモードで動作します。
グラフテンソルは値を持ちません。
グラフモードでは、TensorFlowの演算と関数しか使えません。
このため、この関数を直接.mapすることはできません。tf.py_functionでラップする必要があります。tf.py_functionは(値とそれにアクセスするための.numpy()メソッドを持つ)通常のテンソルを、ラップされたPython関数に渡します。
Note: このサンプルを小さく、より速くするため、長さが40トークンを超えるサンプルを削除します。
パディングとバッチ化の両方を行います。
Note: TensorFlow 2.2 から、padded_shapes は必須ではなくなりました。デフォルトではすべての軸をバッチ中で最も長いものに合わせてパディングします。
後でコードをテストするために、検証用データセットからバッチを一つ取得しておきます。
位置エンコーディング
このモデルには再帰や畳込みが含まれないので、モデルに文中の単語の相対的な位置の情報を与えるため、位置エンコーディングを追加します。
位置エンコーディングベクトルは埋め込みベクトルに加算します。埋め込みはトークンをd次元空間で表現します。そこでは、同じような意味を持つトークンが近くに位置することになります。しかし、埋め込みは単語の文中の相対的位置をエンコードしません。したがって、位置エンコーディングを加えることで、単語は、d次元空間の中で、意味と文中の位置の近さにもとづいて近くに位置づけられます。
もう少し知りたければ 位置エンコーディング のノートブックを参照してください。位置エンコーディングを計算する式は下記のとおりです。
マスキング
シーケンスのバッチ中のパディングされた全てのトークンをマスクします。これにより、モデルがパディングを確実に入力として扱わないようにします。マスクは、パディング値0の存在を示します。つまり、0の場所で1を出力し、それ以外の場所では0を出力します。
シーケンス中の未来のトークンをマスクするため、 ルックアヘッド・マスクが使われています。言い換えると、このマスクはどのエントリーを使うべきではないかを示しています。
これは、3番めの単語を予測するために、1つ目と2つ目の単語だけが使われるということを意味しています。同じように4つ目の単語を予測するには、1つ目、2つ目と3つ目の単語だけが使用され、次も同様となります。
スケール済み内積アテンション
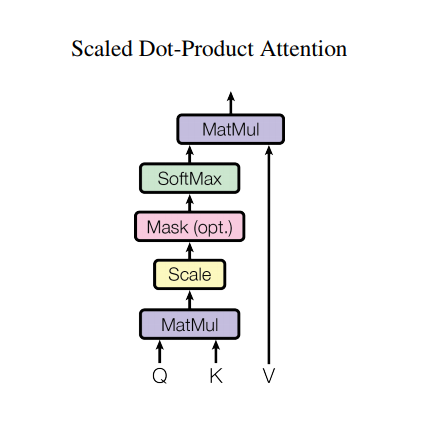
Transformerで使われているアテンション関数は3つの入力;Q(query), K(key), V(value)を取ります。このアテンションの重みの計算に使われている式は下記の通りです。
内積アテンションは、深度の平方根をファクターとしてスケールされています。これは、深度が大きくなると、内積が非常に大きくなり、ソフトマックス関数の勾配を計算すると非常に小さな値しか返さなくなってしまうためです。
例えば、QとKが平均0分散1だと思ってください。これらの行列積は、平均0分散はdkとなります。したがって、(他の数字ではなく)dkの平方根をスケーリングに使うことで、Q と K の行列積においても平均 0 分散 1 となり、緩やかな勾配を持つソフトマックスが得られることが期待できるのです。
マスクには、(負の無限大に近い)-1e9が掛けられています。これは、マスクがQとKのスケール済み行列積と合計され、ソフトマックスの直前に適用されるからです。目的は、これらのセルをゼロにしてしまうことで、大きなマイナスの入力は、ゼロに近い出力となります。
ソフトマックス正規化がKに対して行われるため、その値がQに割り当てる重要度を決めることになります。
出力は、アテンションの重みとV(value)ベクトルの積を表しています。これにより、注目したい単語がそのまま残され、それ以外の単語は破棄されます。
すべてのクエリをまとめます。
マルチヘッド・アテンション
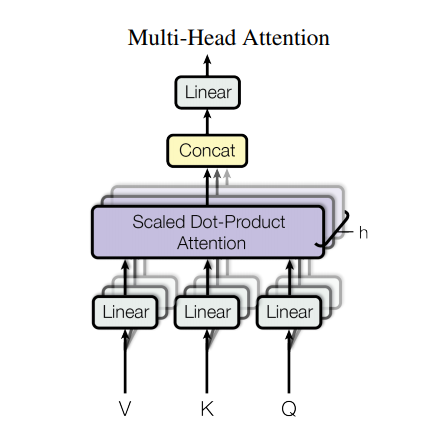
マルチヘッド・アテンションは4つのパートから成っています。
線形レイヤーとマルチヘッドへの分割
スケール済み内積アテンション
マルチヘッドの結合
最終線形レイヤー
各マルチヘッド・アテンション・ブロックは3つの入力:Q(query), K(key), V(value)を取ります。 これらは、線形(Dense)レイヤーを通され、マルチヘッドに分割されます。
上記で定義したscaled_dot_product_attentionは(効率のためにブロードキャストで)各ヘッドに適用されます。アテンション・ステップにおいては、適切なマスクを使用しなければなりません。その後、各ヘッドのアテンション出力は(tf.transposeとtf.reshapeを使って)結合され、最後のDenseレイヤーに通されます。
単一のアテンション・ヘッドのかわりに、Q、K、およびVは複数のヘッドに分割されます。なぜなら、それによって、モデルが異なる表現空間の異なる位置の情報について、連携してアテンションを計算できるからです。また、分割後の各ヘッドの次元を小さくすることで、全体の計算コストを、すべての次元を持つ単一のアテンション・ヘッドを用いた場合と同一にできます。
試しに、MultiHeadAttentionレイヤーを作ってみましょう。シーケンス y の各位置において、MultiHeadAttention はシーケンスのすべての位置に対して8つのヘッドを用いてアテンションを計算し、各位置それぞれで同じ長さの新しいベクトルを返します。
ポイントワイズのフィードフォワード・ネットワーク
ポイントワイズのフィードフォワード・ネットワークは、2つの全結合層とそれをつなぐReLU活性化層からなります。
エンコーダーとデコーダー
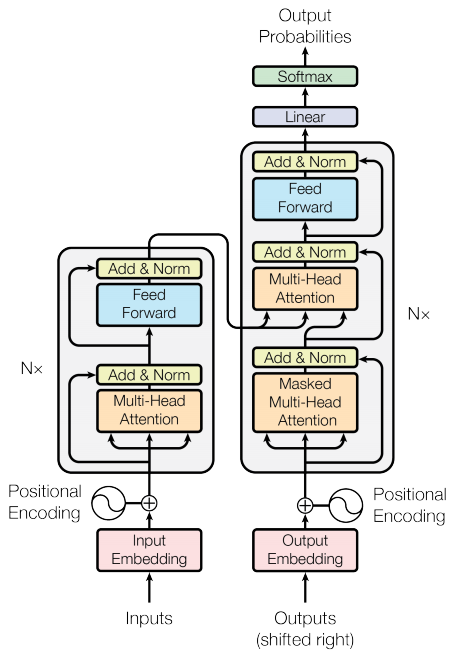
Transformerモデルは、標準のアテンション付きシーケンス・トゥー・シーケンスモデルと同じ一般的なパターンを踏襲します。
入力の文は、
N層のエンコーダー・レイヤーを通り、シーケンス中の単語/トークンごとに出力を生成する。デコーダーは、エンコーダーの出力と自分自身の入力(セルフアテンション)に注目し、次の単語を予測する。
エンコーダー・レイヤー
それぞれのエンコーダー・レイヤーは次のようなサブレイヤーから成っています。
マルチヘッド・アテンション(パディング・マスク付き)
ポイントワイズ・フィードフォワード・ネットワーク
サブレイヤーにはそれぞれ残差接続があり、その後にレイヤー正規化が続きます。残差接続は、深いネットワークでの勾配消失問題を回避するのに役立ちます。
それぞれのサブレイヤーの出力はLayerNorm(x + Sublayer(x))です。正規化は、(最後の)d_model軸に対して行われます。TransformerにはN層のエンコーダーがあります。
デコーダー・レイヤー
各デコーダー・レイヤーは次のようなサブレイヤーからなります。
マスク付きマルチヘッド・アテンション( ルックアヘッド・マスクおよびパディング・マスク付き)
(パディング・マスク付き)マルチヘッド・アテンション。V(value) と K(key) はエンコーダーの出力を入力として受け取る。Q(query)はマスク付きマルチヘッド・アテンション・サブレイヤーの出力を受け取る。
ポイントワイズ・フィードフォワード・ネットワーク
各サブレイヤーは残差接続を持ち、その後にレイヤー正規化が続きます。各サブレイヤーの出力はLayerNorm(x + Sublayer(x))です。正規化は、(最後の)d_model軸に沿って行われます。
Transformerには、N層のデコーダー・レイヤーが存在します。
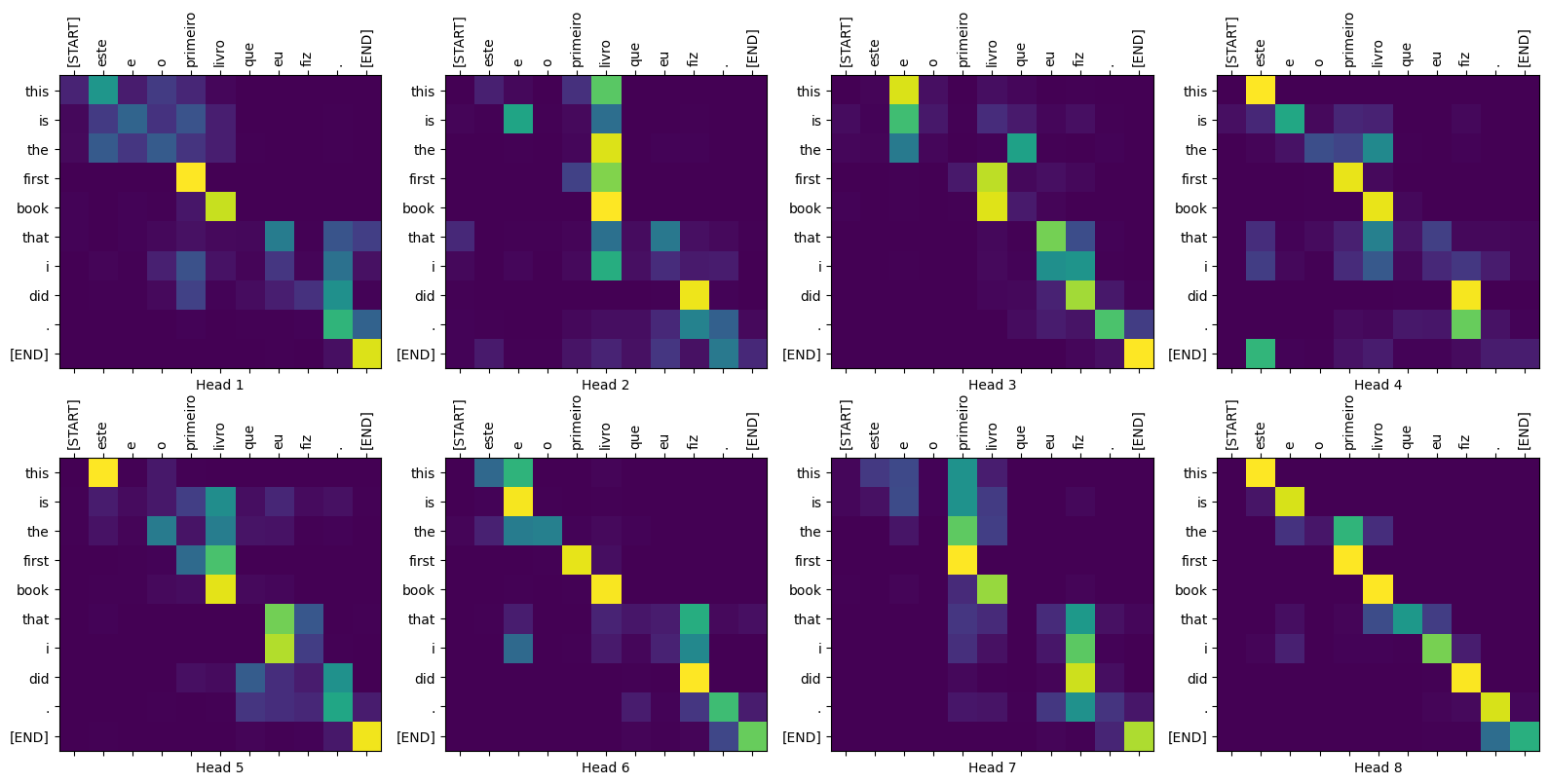
Qがデコーダーの最初のアテンション・ブロックの出力を受け取り、Kがエンコーダーの出力を受け取るとき、アテンションの重みは、デコーダーの入力の、エンコーダーの出力に対する重要度を表します。言い換えると、デコーダーは、エンコーダーの出力と自分自身の出力のセルフ・アテンションを見て、次の単語を予想します。上記の、スケール済み内積アテンションのセクションのデモを参照してください。
エンコーダー
Encoderは次のものからできています。
入力の埋め込み
位置エンコーディング
N 層のエンコーダー・レイヤー
入力は埋め込み層を通り、位置エンコーディングと合算されます。この加算の出力がエンコーダー・レイヤーの入力です。エンコーダーの出力はデコーダーの入力になります。
デコーダー
Decoder は次のもとからできています。
出力埋め込み
位置エンコーディング
N 層のデコーダー・レイヤー
ターゲットは埋め込みを通り、位置エンコーディングと加算されます。この加算の出力がデコーダーの入力になります。デコーダーの出力は、最後の線形レイヤーの入力となります。
Transformerの作成
Transformerは、エンコーダー、デコーダーと、最後の線形レイヤーからなります。デコーダーの出力は、線形レイヤーの入力であり、その出力が返されます。
ハイパーパラメーターの設定
このサンプルを小さく、比較的高速にするため、 num_layers, d_model, and dffの値は小さくされています。
Transformerのベースモデルで使われている値はnum_layers=6, d_model = 512, dff = 2048です。 Transformerの他のバージョンについては、論文を参照してください。
Note: 下記の値を変更することで、さまざまなタスクでSoTA(訳注:State of The Art、その時点での最高性能)を達成したモデルが得られます。
オプティマイザー
論文の中の式に従って、カスタムの学習率スケジューラーを持った、Adamオプティマイザーを使用します。
損失とメトリクス
ターゲットシーケンスはパディングされているため、損失を計算する際にパディング・マスクを適用することが重要です。
訓練とチェックポイント生成
チェックポイントのパスとチェックポイント・マネージャーを作成します。これは、nエポックごとにチェックポイントを保存するのに使用されます。
ターゲットは、tar_inpとtar_realに分けられます。tar_inpはデコーダーの入力として渡されます。tar_realは同じ入力を1つシフトしたものです。tar_inputの位置それぞれで、tar_realは予測されるべき次のトークンを含んでいます。
たとえば、sentence = "SOS A lion in the jungle is sleeping EOS" だとすると、次のようになります。
tar_inp = "SOS A lion in the jungle is sleeping"
tar_real = "A lion in the jungle is sleeping EOS"
Transformerは、自己回帰モデルです。1回に1箇所の予測を行い、その出力を次に何をすべきかの判断に使用します。
訓練時にこのサンプルはテキスト生成チュートリアルのように、ティーチャーフォーシングを使用します。ティーチャーフォーシングとは、その時点においてモデルが何を予測したかに関わらず、真の出力を次のステップに渡すというものです。
Transformerが単語を予測するたびに、セルフアテンションのおかげで次の単語を予測するために入力シーケンスの過去の単語を参照することができます。
モデルが期待される出力を盗み見ることがないように、モデルはルックアヘッド・マスクを使用します。
ポルトガル語を入力言語とし、英語をターゲット言語とします。
評価
評価は次のようなステップで行われます。
ポルトガル語のトークナイザー(
tokenizer_pt)を使用して入力文をエンコードします。さらに、モデルの訓練に使用されたものと同様に、開始および終了トークンを追加します。これが、入力のエンコードです。デコーダーの入力は、
start token == tokenizer_en.vocab_sizeです。パディング・マスクとルックアヘッド・マスクを計算します。
decoderは、encoder outputと自分自身の出力(セルフアテンション)を見て、予測値を出力します。最後の単語を選択し、そのargmaxを計算します。
デコーダーの入力に予測された単語を結合し、デコーダーに渡します。
このアプローチでは、デコーダーは自分自身が予測した過去の単語にもとづいて次の単語を予測します。
Note: ここで使われているモデルは、より早く実行できるようにした能力の低いものであるため、予測はあまり正確ではありません。論文の結果を再現するには、データセット全体を使用し、上記のハイパーパラメーターを変更して、ベースのTransformerモデルまたはTransformer XLを使用します。
パラメータをplotするために、異なるレイヤーやデコーダーのアテンション・ブロックを渡すことができます。
まとめ
このチュートリアルでは、位置エンコーディング、マルチヘッド・アテンション、マスキングの重要性と、 Transformerの作成方法を学習しました。
Transformerを訓練するために、異なるデータセットを使ってみてください。また、上記のハイパーパラメーターを変更してベースTransformerやTransformer XLを構築することもできます。ここで定義したレイヤーを使ってBERTを構築して、SoTAのモデルを作ることもできます。さらには、より良い予測を得るために、ビームサーチを組み込むこともできます。