
Path: blob/master/site/ja/tutorials/understanding/sngp.ipynb
38541 views
Copyright 2021 The TensorFlow Authors.
SNGP による不確実性を考慮したディープラーニング
 GitHub でソースを表示
GitHub でソースを表示医療上の決定や自走といった安全性が非常に重要であるか、本質的にノイズの多いデータ(自然言語の理解など)が使用される AI アプリケーションでは、ディープ分類器がその不確実性を確実に定量化できることが重要です。ディープ分類器は、それ自体の制限と、人間の専門家に制御を引き渡すタイミングを認識できなければなりません。このチュートリアルでは、**Spectral-normalized Neural Gaussian Process(スペクトル正規化されたニューラルガウス過程)(SNGP{.external})**という手法を使用して、不確実性の定量化におけるディープ分類器の性能を改善する方法を説明します。
SNGP の中核にある構想は、ネットワークに単純な変更を適用することで、ディープ分類器の距離認識を改善することです。モデルの距離認識は、予測確率がテストサンプルとトレーニングデータ間の距離をどれくらい反映するかを示す尺度です。これは、絶対的基準の確率モデル(RBF カーネルを使ったガウス過程{.external} など)に共通する望ましいプロパティではありますが、ディープニューラルネットワークを使ったモデルにはありません。SNGP は、予測精度を維持しながら、ガウス過程の動作をディープ分類器に注入する単純な方法を提供しています。
このチュートリアルでは、scikit-learn の two moons{.external} データセットに対してディープ残余ネットワーク(ResNet)ベースの SNGP モデルを実装し、その不確実性サーフェスと、モンテカルロドロップアウト{.external}やディープアンサンブル{.external}といった他の 2 つの一般的な不確実性アプローチの不確実性サーフェスを比較します。
このチュートリアルでは、トイ 2D データセットで SNGP モデルを説明します。BERT ベースを使用して SNGP を実際の自然言語理解タスクに適用する例については、SNGP-BERT チュートリアルをご覧ください。広範なベンチマークデータセット(CIFAR-100、ImageNet、Jigsaw toxicity detection など)での SNGP モデル(およびその他多数の不確実性手法)の高品質実装については、Uncertainty Baselines{.external} ベンチマークをご覧ください。
SNGP について
SNGP は、ディープ分類器の不確実性特性を改善しながら、同等の精度とレイテンシを維持する単純なアプローチです。ディープ残余ネットワークの場合、SNGP はモデルに 2 つの単純な変更を加えます。
スペクトル正規化を非表示残余レイヤーに適用します。
Dense 出力レイヤーをガウス過程レイヤーに置き換えます。
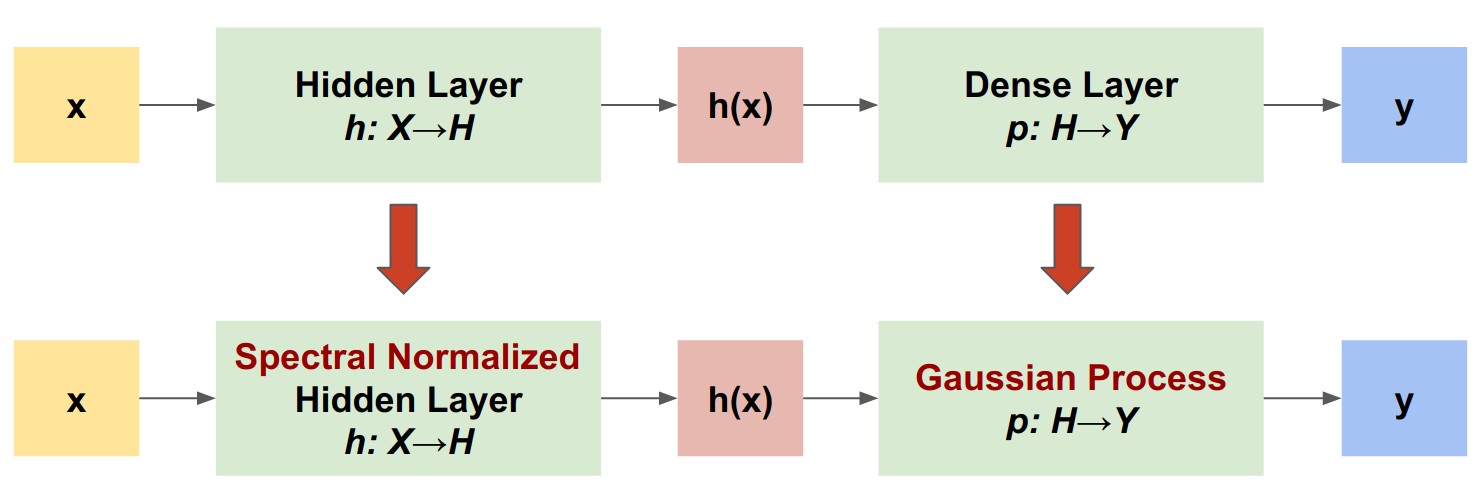
他の不確実性アプローチ(モンテカルロドロップアウトやディープアンサンブルなど)と比べ、SNGP にはいくつかのメリットがあります。
広範な最新鋭の残余ベースアーキテクチャ((Wide)ResNet、DenseNet、BERT など)と機能。
シングルモデルメソッドである(アンサンブル平均化に依存しない)。そのため、SNGP には単一の決定論的ネットワークと同程度のレイテンシがあり、ImageNet{.external} や Jigsaw Toxic Comments 分類{.external}などの大型のデータセットに簡単にスケーリングできます。
距離認識プロパティにより、強力なドメイン外検出パフォーマンスを持ち合わせている。
このモデルには、以下のような欠点があります。
SNGP の予測不確実性は、ラプラス近似{.external}を使って計算される。そのため、理論的に、SNGP の事後確率の不確実性は、正確なガウス過程の不確実性と異なります。
SNGP トレーニングには、新しいエポックの開始時に共分散のリセットステップが必要である。これにより、トレーニングパイプラインに微小な複雑性が付加される可能性があります。このチュートリアルでは、Keras コールバックを使ってこれを簡単に実装する方法を説明します。
MNIST モデルをビルドする
可視化マクロを定義します。
two moon データセット
scikit-learn の two moon データセット{.external}から、トレーニングデータセットと評価データセットを作成します。
2D 入力空間全体に対するモデルの予測動作を評価します。
モデルの不確実性を評価するために、サードクラスに属するドメイン外(OOD)データセットを追加します。このモデルはトレーニング中にこれらの OOD サンプルを観測することはありません。
ここでは、青とオレンジで正と負のクラスが表現されており、赤で OOD データが表されています。不確実性をうまく定量化するモデルは、トレーニングデータに近い( が 0 または 1 に近い)場合に信頼性があり、トレーニングデータのリージョンから遠い( が 0.5 に近い)場合に不確実であることが期待されます。
決定論的モデル
モデルを定義する
(ベースライン)決定論的モデルから始めます。ドロップアウトの正則化を伴うマルチレイヤーの残余ネットワーク(ResNet)です。
このチュートリアルは、128 個の非表示ユニットを持つ 6 レイヤーの ResNet を使用しています。
モデルをトレーニングします。
SparseCategoricalCrossentropy を損失関数と Adam オプティマイザとして使用するようにトレーニングパラメータを構成します。
バッチサイズを 128、エポックを 100 として、モデルをトレーニングします。
不確実性を可視化する
次に、決定論的モデルの予測を可視化します。まず、クラスの確率をプロットします:
このプロットでは、黄色と紫で 2 つのクラスの予測確率が表現されています。この決定論的モデルは、非線形決定境界で、2 つの既知のクラス(青とオレンジ)をうまく分類していますが、距離認識ではなく、観測されていない赤のドメイン外(OOD)サンプルを確信的にオレンジクラスとして分類しています。
予測分散を計算して、モデルの不確実性を可視化します:
このプロットでは、黄色で高い不確実性を示し、紫で低い不確実性を示しています。決定論的 ResNet の不確実性は、テストサンプルの決定境界からの距離のみに依存しています。このため、トレーニングドメイン外になると、モデルの過学習が発生しています。次のセクションでは、SNGP がこのデータセットでどのように動作するかを説明します。
SNGP モデル
SNGP モデルを定義する
SNGP モデルを実装しましょう。SpectralNormalization と RandomFeatureGaussianProcess のいずれの SNGP コンポーネントも、tensorflow_model の組み込みレイヤーで使用できます。
次に、これらの 2 つのコンポーネントをさらに詳しく調べましょう。(完全な SNGP モデルのセクションでも、SNGP がどのように実装されているかについて知ることができます。)
SpectralNormalization ラッパー
SpectralNormalization{.external} は Keras レイヤーラッパーです。以下のようにして既存の Dense レイヤーに適用できます。
スペクトル正規化は、そのスペクトル基準( の最大固有値)を徐々にターゲット値の norm_multiplier に誘導することで、非表示の重み を正則化します。
注意: 通常、norm_multiplier を 1 より小さい値に設定することが推奨されます。ただし、実際には、ディープネットワークに十分な表現力を持たせるために、より大きな値に緩和することもできます。
ガウス過程(GP)レイヤー
RandomFeatureGaussianProcess{.external} は、ランダム特徴量ベースの近似{.external}を、ディープニューラルネットワークでエンドツーエンドのトレーニング可能なガウス過程モデルに実装します。内部的には、ガウス過程レイヤーは以下の 2 層ネットワークを実装します。
ここで、 は入力で、 と はそれぞれガウスと一様分布からランダムに初期化される凍結された重みです。(そのため、 は「ランダム特徴量」と呼ばれます。) は Dense レイヤーに似た学習可能なカーネルの重みです。
以下は、GP レイヤーの主なパラメーターです。
units: 出力ロジットの次元num_inducing: 非表示の重み の次元 。デフォルトは 1024 です。normalize_input: レイヤーの正規化を入力 に適用するかどうか。scale_random_features: スケール を非表示の出力に適用するかどうか。
注意: 学習率に敏感なディープニューラルネットワーク(ResNet-50 や ResNet-110 など)の場合は、一般的に、トレーニングを安定化するには normalize_input=True に設定し、GP レイヤーを通過する際に期待されない方法で学習率が変更されないようにするには scale_random_features=False に設定することが推奨されます。
gp_cov_momentumは、モデル共分散が計算される方法を制御します。正の値(0.999など)に設定された場合、共分散行列は運動量ベースの移動平均の更新を使って計算されます。-1に設定された場合、共分散行列は運動量無しで更新されます。
注意: 運動量ベースの移動平均の更新方法は、バッチサイズに敏感な場合があります。そのため、一般的に、gp_cov_momentum=-1 に設定して、共分散を正確に計算することが推奨されます。これが正しく動作するには、同じデータが 2 回カウントされないようにするために、共分散行列の Estimator を新しいエポックの開始時にリセットする必要があります。RandomFeatureGaussianProcess の場合、これは、reset_covariance_matrix() を呼び出して行えます。次のセクションでは、Keras の組み込み API を使ってこれを簡単に実装する方法を説明します。
形状 (batch_size, input_dim) のバッチ入力がある場合、GP レイヤーは予想に logits テンソル(形状 (batch_size, num_classes))だけでなく、バッチロジットの事後確率共分散行列である covmat テンソル(形状 (batch_size, batch_size))も返します。
注意: この SNGP モデルの実装では、全クラスの予測ロジット が同じ共分散行列を共有していることに注目してください。これは、トレーニングデータからの 間の距離を示しています。
理論的に言えば、異なるクラスに対する異なるバリアンスの値を計算するようにアルゴリズムを拡張することが可能ですが(SNGP 論文の原文を参照{.external})、これを、大規模な出力空間を伴う問題(ImageNet または言語モデリングによる分類など)にスケーリングすることは困難です。
基底クラスの DeepResNet がある場合、SNGP モデルは、残余ネットワークの非表示レイヤーと出力レイヤーを変更することで簡単に実装できます。Keras model.fit() API との互換性を得るために、モデルの call() メソッドも変更して、トレーニング中にのみ logits を出力するようにします。
決定論的モデルと同じアーキテクチャを使用します。
このコールバックを DeepResNetSNGP モデルクラスに追加します。
モデルをトレーニングします。
tf.keras.model.fit を使用してモデルをトレーニングします。
不確実性を可視化する
まず、予測ロジットとバリアンスを計算します。
次に、事後予測確率を計算します。確率モデルの予測確率を計算するには、以下のモンテカルロサンプリングを使用するのが古典的です。
ここで、 はサンプルサイズで、 は、SNGP 事後確率 (sngp_logits,sngp_covmat) からのランダムサンプルです。ただし、このアプローチでは、自走車両やリアルタイム入札といった遅延に敏感なアプリケーションでは遅くなる可能性があります。代わりに、平均場法{.external} を使用して、 を概算することができます。
ここで、 は SNGP バリアンスで、 は または として選択されることがよくあります。
注意: を固定値に設定する代わりに、それをハイパーパラメータとして扱い、モデルの較正パフォーマンスを最適化するように調整することもできます。これは、ディープラーニングの不確実性に関する文献では、温度スケーリング{.external}として知られています。
この平均場法は、組み込み関数の layers.gaussian_process.mean_field_logits として実装されます。
SNGP のまとめ
これで、すべてを一まとめにできるようになりました。トレーニング、評価、および不確実性の計算という手続き全体を、わずか 5 行で完了することができます。
SNGP モデルのクラス確率(左)と予測不確実性(右)を可視化します。
クラス確率プロット(左)では、黄色と紫がクラス確率であることを思い出しましょう。トレーニングデータのドメインに近づくと、SNGP はサンプルを高い信頼で正しく分類します(0 または 1 に近い確率を割り当てます)。トレーニングデータから遠い場合、SNGP の信頼は徐々に低くなり、予測確率が 0.5 に近づく一方で、(正規化された)モデル不確実性が 1 に上昇します。
これを、決定論的モデルの不確実性サーフェスと比較します。
前述のとおり、決定論的モデルは距離認識ではありません。その不確実性は、決定境界からのテストサンプルの距離で定義されています。このため、モデルはドメイン外サンプル(赤)の過信予測を生成してしまいます。
他の不確実性アプローチとの比較
このセクションでは、SNGP の不確実性をモンテカルロドロップアウト{.external}とディープアンサンブル{.external}と比較します。
これらのいずれの手法も、決定論的モデルの複数フォワードパスのモンテカルロアベレージングに基づきます。まず、アンサンブルサイズ を設定します。
モンテカルロドロップアウト
ドロップアウトレイヤーを持つトレーニング済みのネットワークがある場合、モンテカルロドロップアウトは、以下の平均予測確率
を、複数のドロップアウト有効フォワードパス で平均化して計算します。
ディープアンサンブル
ディープアンサンブルは、ディープラーニング不確実性の最新の(ただし高価な)手法です。ディープアンサンブルをトレーニングするには、まず、 個のアンサンブルメンバーをトレーニングする必要があります。
ロジットを収集し、平均予測確率 を計算します。
モンテカルロドロップアウトとディープアンサンブルのいずれの手法も、決定境界の確実性を抑えることで、モデルの不確実性の能力を改善しています。ただし、いずれも、距離認識が欠けているという、決定論的ディープネットワークの制約を継承しています。
まとめ
このチュートリアルでは、以下のことを行いました。
ディープ分類器に SNGP モデルを実装し、距離認識を改善しました。
Keras
Model.fitAPI を使用して、SNGP モデルをエンドツーエンドでトレーニングしました。SNGP の不確実性の動作を可視化しました。
SNGP、モンテカルロドロップアウト、およびディープアンサンブルのモデルで不確実性の動作を比較しました。
リソースとその他の文献
不確実性を認識する自然言語の理解に関する BERT モデルに SNGP を適用する例については、SNGP-BERT チュートリアルをご覧ください。
広範なベンチマークデータセット(CIFAR、ImageNet、Jigsaw 毒性検出など)での SNGP モデルの実装については、Uncertainty Baselines GitHub リポジトリ{.external}にアクセスしてください。
SNGP をさらに理解するには、『Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness{.external}』という論文をご覧ください。