
Path: blob/master/site/ko/hub/tutorials/movinet.ipynb
38573 views
Copyright 2021 The TensorFlow Hub Authors.
Licensed under the Apache License, Version 2.0 (the "License");
스트리밍 동작 인식을 위한 MoViNet
 GitHub에서 소스 보기
GitHub에서 소스 보기이 튜토리얼에서는 사전 학습된 비디오 분류 모델을 사용하여 주어진 비디오에서 활동(예: 춤, 수영, 자전거 타기 등)을 분류하는 방법을 보여줍니다.
이 튜토리얼에서 사용된 모델 아키텍처는 MoViNet(Mobile Video Networks)이라고 합니다. MoVieNets는 거대한 데이터세트(Kinetics 600)에서 훈련된 효율적인 비디오 분류 모델 집합입니다.
TF Hub에서 사용 가능한 i3d 모델과 달리 MoViNet은 스트리밍 비디오에서 프레임별 추론도 지원합니다.
사전 훈련된 모델은 TF Hub에서 사용할 수 있습니다. TF Hub 컬렉션에는 TFLite에 최적화된 양자화된 모델도 포함되어 있습니다.
이러한 모델의 소스는 TensorFlow Model Garden에서 제공합니다. 여기에는 MoViNet 모델 구축 및 미세 조정에 대한 내용도 담긴 이 튜토리얼의 상세 버전이 포함됩니다.
이 MoViNet 튜토리얼은 TensorFlow 비디오 튜토리얼 시리즈의 일부입니다. 다른 세 개의 튜토리얼은 다음과 같습니다.
비디오 데이터 로드: 이 튜토리얼에서는 처음부터 비디오 데이터를 TensorFlow 데이터세트 파이프라인으로 로드하고 전처리하는 방법을 설명합니다.
비디오 분류를 위한 3D CNN 모델 구축: 이 튜토리얼에서는 3D 데이터의 공간적 및 시간적 측면을 분해하는 (2+1)D CNN을 사용합니다. MRI 스캔과 같은 체적 데이터를 사용하는 경우 (2+1)D CNN 대신 3D CNN을 사용하는 것이 좋습니다.
MoViNet을 사용한 비디오 분류 전이 학습: 이 튜토리얼에서는 UCF-101 데이터세트와 함께 상이한 데이터세트에서 훈련된 사전 훈련 비디오 분류 모델을 사용하는 방법에 대해 설명합니다.
설정
더 작은 모델(A0-A2)에 대한 추론의 경우, 이 Colab에 대한 CPU가 충분합니다.
kinetics 600 레이블 목록을 가져오고 처음 몇 개의 레이블을 인쇄합니다.
분류를 위한 간단한 예제 비디오를 제공하기 위해 팔 벌려 뛰기를 수행 중인 짧은 gif를 로드할 수 있습니다.

저작자 표시: CC-BY 라이선스에 따라 Coach Bobby Bluford가 YouTube에서 공유한 영상입니다.
gif를 다운로드합니다.
gif 파일을 tf.Tensor로 읽는 함수를 정의합니다.
비디오의 형상은 (frames, height, width, colors)입니다.
모델을 사용하는 방법
이 섹션에는 TensorFlow Hub의 모델을 사용하는 방법을 보여주는 연습이 포함되어 있습니다. 작동 중인 모델만 보고 싶다면 다음 섹션으로 건너뛰세요.
각 모델에는 base 및 streaming의 두 가지 버전이 있습니다.
base버전은 비디오를 입력으로 사용하고 프레임에 대한 평균 확률을 반환합니다.streaming버전은 비디오 프레임과 RNN 상태를 입력으로 사용하고 해당 프레임과 새 RNN 상태에 대한 예측을 반환합니다.
기본 모델
TensorFlow Hub에서 사전 훈련된 모델을 다운로드합니다.
이 버전의 모델에는 하나의 signature가 있습니다. 형상이 (batch, frames, height, width, colors)인 tf.float32의 image 인수를 취합니다. 그리고 하나의 출력, 즉 형상이 (batch, classes)인 로짓의 tf.float32 텐서를 포함하는 사전을 반환합니다.
비디오에서 이 서명을 실행하려면 먼저 비디오에 외부 batch 차원을 추가해야 합니다.
위의 출력 처리를 나중에 패키징하는 get_top_k 함수를 정의합니다.
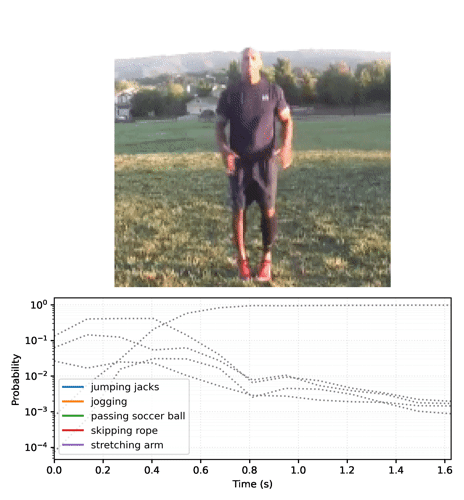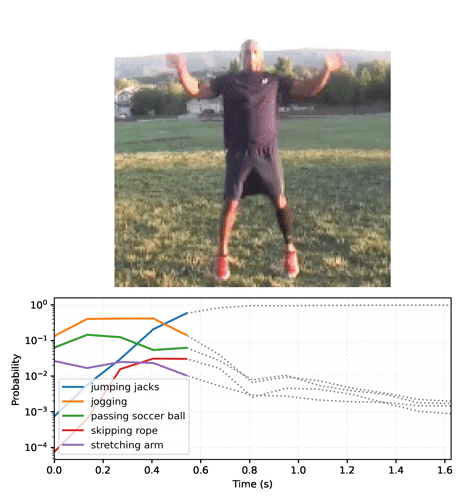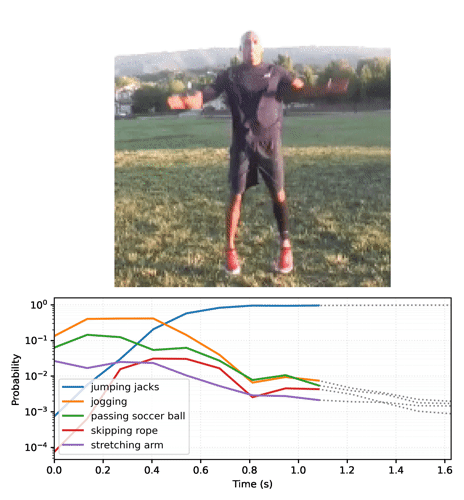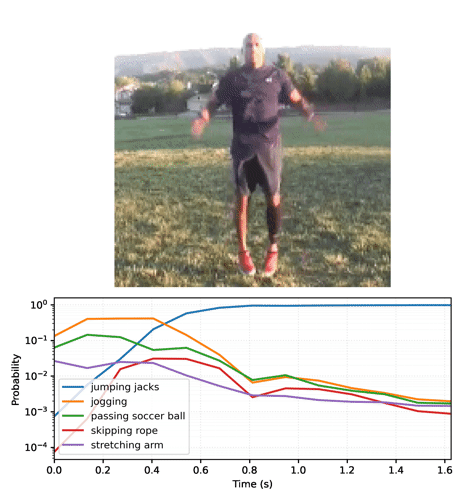
logits을 확률로 변환하고 비디오의 상위 5개 클래스를 찾습니다. 모델은 비디오가 jumping jacks일 가능성이 있음을 확인합니다.
스트리밍 모델
이전 섹션에서는 전체 비디오를 실행하는 모델을 사용했습니다. 종종 비디오를 처리할 때 마지막에 하나의 예측을 원하지 않고 프레임별로 예측을 업데이트하고 싶을 수 있습니다. 모델의 stream 버전을 사용하면 가능합니다.
모델의 stream 버전을 로드합니다.
이 모델을 사용하는 것은 base 모델보다 약간 더 복잡합니다. 모델의 RNN에 대한 내부 상태를 추적해야 합니다.
init_states 서명은 비디오의 형상 (batch, frames, height, width, colors)를 입력으로 사용하고 초기 RNN 상태를 포함하는 텐서의 방대한 사전을 반환합니다.
RNN의 초기 상태가 확보되면 상태와 비디오 프레임을 입력으로 전달할 수 있습니다(비디오 프레임의 (batch, frames, height, width, colors) 형상 유지). 모델은 (logits, state) 쌍을 반환합니다.
첫 번째 프레임을 본 후 모델은 비디오가 "팔 벌려 뛰기"인지 확신하지 못합니다.
루프에서 모델을 실행하여 각 프레임과 함께 업데이트된 상태를 전달하면 모델이 올바른 결과로 빠르게 수렴됩니다.
base 모델을 실행한 이전 섹션보다 최종 확률이 훨씬 더 확실하다는 것을 알 수 있습니다. base 모델은 전체 프레임에 대한 예측의 평균을 반환합니다.
시간 경과에 따른 예측 애니메이션
이전 섹션에서는 이러한 모델을 사용하는 방법에 대해 자세히 설명했습니다. 이 섹션은 이를 바탕으로 멋진 추론 애니메이션을 생성합니다.
아래의 숨겨진 셀은 이 섹션에서 사용되는 도우미 함수를 정의합니다.
비디오 프레임에서 스트리밍 모델을 실행하고 로짓을 수집하여 시작합니다.
확률 시퀀스를 비디오로 변환합니다.
리소스
사전 훈련된 모델은 TF Hub에서 사용할 수 있습니다. TF Hub 컬렉션에는 TFLite에 최적화된 양자화된 모델도 포함되어 있습니다.
이러한 모델의 소스는 TensorFlow Model Garden에서 제공합니다. 여기에는 MoViNet 모델 구축 및 미세 조정에 대한 내용도 담긴 이 튜토리얼의 상세 버전이 포함됩니다.
다음 단계
TensorFlow에서 비디오 데이터 작업에 대해 자세히 알아보려면 다음 튜토리얼을 확인하세요.