
Path: blob/master/site/ko/tutorials/load_data/video.ipynb
38279 views
Copyright 2022 The TensorFlow Authors.
비디오 데이터 로드
 GitHub에서 소스 보기
GitHub에서 소스 보기이 튜토리얼은 UCF101 인간 행동 데이터세트를 사용하여 AVI 비디오 데이터를 로드하고 전처리하는 방법을 보여줍니다. 데이터를 전처리하면 비디오 분류/인식, 캡션 또는 클러스터링과 같은 작업에 사용할 수 있습니다. 원본 데이터세트에는 첼로 연주, 양치질, 눈 화장 등 101개 범주로 YouTube에서 수집한 사실적인 동작 비디오가 포함되어 있습니다. 다음을 수행하는 방법을 배우게 됩니다.
zip 파일에서 데이터를 로드합니다.
비디오 파일에서 프레임 시퀀스를 읽습니다.
비디오 데이터를 시각화합니다.
프레임 생성기
tf.data.Dataset을 래핑합니다.
이 비디오 로드 및 전처리 튜토리얼은 TensorFlow 비디오 튜토리얼 시리즈의 첫 번째 부분입니다. 다른 세 개의 튜토리얼은 다음과 같습니다.
비디오 분류를 위한 3D CNN 모델 구축: 이 튜토리얼에서는 3D 데이터의 공간적 및 시간적 측면을 분해하는 (2+1)D CNN을 사용합니다. MRI 스캔과 같은 체적 데이터를 사용하는 경우 (2+1)D CNN 대신 3D CNN을 사용하는 것이 좋습니다.
스트리밍 동작 인식을 위한 MoViNet: TF Hub에서 사용할 수 있는 MoViNet 모델에 익숙해집니다.
MoViNet을 사용한 비디오 분류 전이 학습: 이 튜토리얼에서는 UCF-101 데이터세트와 함께 상이한 데이터세트에서 훈련된 사전 훈련 비디오 분류 모델을 사용하는 방법에 대해 설명합니다.
설정
ZIP 파일의 내용을 검사하기 위한 remotezip, 진행률 표시줄을 사용하기 위한 tqdm, 비디오 파일을 처리하기 위한 OpenCV, Jupyter 노트북에 데이터를 삽입하기 위한 tensorflow_docs를 포함하여 몇 가지 필요한 라이브러리를 설치하고 가져오는 것으로 시작합니다.
UCF101 데이터세트의 하위 집합 다운로드
UCF101 데이터세트에는 주로 동작 인식에 사용되는 비디오의 다양한 동작이 101개의 범주로 포함되어 있습니다. 이 데모에서 이러한 범주 중 일부를 사용합니다.
위 URL에는 UCF 101 데이터세트가 포함된 zip 파일이 포함되어 있습니다. remotezip 라이브러리를 사용하여 해당 URL에 있는 zip 파일의 내용을 검사하는 함수를 만듭니다.
몇 개의 비디오와 제한된 수의 훈련용 클래스로 시작합니다. 위의 코드 블록을 실행한 후 각 비디오의 파일 이름에 클래스 이름이 포함되어 있음을 확인하세요.
파일 이름에서 클래스 이름을 검색하는 get_class 함수를 정의합니다. 그런 다음 모든 파일(위의 files) 목록을 각 클래스에 대한 파일을 나열하는 사전으로 변환하는 get_files_per_class라는 함수를 만듭니다.
클래스별 파일 목록이 준비되면 데이터세트를 만들기 위해 사용할 클래스 수와 클래스당 원하는 비디오 수를 선택할 수 있습니다.
데이터세트 내에 있는 클래스의 하위 집합과 클래스당 특정 수의 파일을 선택하는 select_subset_of_classes라는 새 함수를 만듭니다.
비디오를 훈련, 검증 및 테스트 세트로 분할하는 헬퍼 함수를 정의합니다. 비디오는 zip 파일로 URL에서 다운로드되어 각각의 하위 디렉터리에 배치됩니다.
다음 함수는 데이터의 하위 집합에 아직 배치되지 않은 나머지 데이터를 반환합니다. 이 나머지 데이터를 지정된 다음 데이터 하위 집합에 배치할 수 있습니다.
다음 download_ucf_101_subset 함수를 사용하면 UCF101 데이터세트의 하위 집합을 다운로드하고 훈련, 검증 및 테스트 세트로 분할할 수 있습니다. 사용하려는 클래스 수를 지정할 수 있습니다. splits 인수를 사용하면 키 값이 하위 집합의 이름(예: "train")과 클래스당 가지려는 비디오 수인 사전을 전달할 수 있습니다.
데이터를 다운로드한 후에는 이제 UCF101 데이터세트의 하위 집합 복사본이 있어야 합니다. 다음 코드를 실행하여 모든 데이터 하위 집합 사이에 가지고 있는 총 비디오 수를 인쇄합니다.
이제 데이터 파일의 디렉터리를 미리 볼 수도 있습니다.
각 비디오 파일에서 프레임 만들기
frames_from_video_file 함수는 비디오를 여러 프레임으로 분할하고 비디오 파일에서 무작위로 선택된 n_frames 범위를 읽은 다음, NumPy array로 반환합니다. 메모리와 계산 오버헤드를 줄이려면 적은 수의 프레임을 선택합니다. 또한 각 비디오에서 동일한 수의 프레임을 선택하면 데이터 배치 작업을 더 쉽게 수행할 수 있습니다.
비디오 데이터 시각화하기
프레임 세트를 NumPy 배열로 반환하는 frames_from_video_file 함수입니다. Patrick Gillett가 Wikimedia{:.external}에 올린 새 동영상에서 이 기능을 사용해 보세요.
이 비디오를 검토하는 외에 UCF-101 데이터를 표시할 수도 있습니다. 이렇게 하려면 다음 코드를 실행합니다.
다음으로, TensorFlow 데이터 파이프라인에 데이터를 공급할 수 있는 반복 가능한 객체를 생성하기 위해 FrameGenerator 클래스를 정의합니다. 생성기(__call__) 함수는 frames_from_video_file에 의해 생성된 프레임 배열과 프레임 세트와 연관된 레이블의 원-핫 인코딩된 벡터를 생성합니다.
TensorFlow Dataset 객체로 래핑하기 전에 FrameGenerator 객체를 테스트합니다. 또한 훈련 데이터세트의 경우 데이터가 섞이도록 훈련 모드를 활성화해야 합니다.
마지막으로, TensorFlow 데이터 입력 파이프라인을 만듭니다. 생성기 객체에서 생성하는 이 파이프라인을 사용하면 딥 러닝 모델에 데이터를 공급할 수 있습니다. 이 비디오 파이프라인에서 각 요소는 단일 프레임 세트 및 관련 레이블입니다.
레이블이 섞였는지 확인합니다.
성능을 높이도록 데이터세트 구성하기
I/O가 차단되지 않고 디스크에서 데이터를 생성할 수 있도록 버퍼링된 프리페치를 사용합니다. 데이터를 로드하는 동안 사용해야 하는 두 가지 중요한 함수는 다음과 같습니다.
Dataset.cache: 첫 번째 epoch 동안 디스크에서 로드된 후 프레임 세트를 메모리에 유지합니다. 이 함수는 모델을 훈련하는 동안 데이터세트가 병목을 일으키지 않도록 합니다. 데이터세트가 너무 커서 메모리에 맞지 않는 경우 이 방법을 사용하여 고성능 디스크 캐시를 생성할 수도 있습니다.Dataset.prefetch: 훈련하는 동안 데이터 전처리와 모델 실행을 중첩시킵니다. 자세한 내용은tf.data로 성능 향상을 참조하세요.
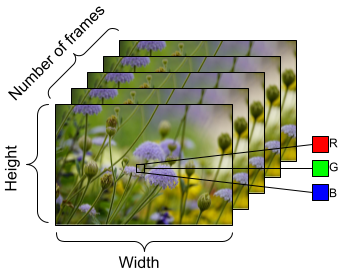
모델에 공급할 데이터를 준비하려면 아래와 같이 배치 처리를 사용합니다. AVI 파일과 같은 비디오 데이터로 작업할 때 데이터는 5차원 객체로 형성되어야 합니다. 이러한 차원은 [batch_size, number_of_frames, height, width, channels]와 같습니다. 이에 비해 이미지에는 [batch_size, height, width, channels] 4가지 차원이 있습니다. 아래 이미지는 비디오 데이터의 형태가 표현되는 방식을 보여주는 그림입니다.
다음 단계
레이블이 있는 비디오 프레임의 TensorFlow Dataset을 만들었으므로 이제 딥 러닝 모델에 이를 사용할 수 있습니다. 사전 훈련된 EfficientNet{:.external}을 사용하는 다음 분류 모델은 몇 분 안에 높은 정확도로 훈련됩니다.
TensorFlow에서 비디오 데이터 작업에 대해 자세히 알아보려면 다음 튜토리얼을 확인하세요.