
Path: blob/master/site/ko/tutorials/text/image_captioning.ipynb
38312 views
Copyright 2018 The TensorFlow Authors.
<style> td { text-align: center; } th { text-align: center; } </style>
눈에 띄는 이미지 캡션
 GitHub에서 소스 보기
GitHub에서 소스 보기아래 예와 같은 이미지가 주어졌을 때의 목표는 "파도를 타는 서퍼"와 같은 캡션을 생성하는 것입니다.
 |
| 서핑하는 남자, 출처: wikimedia |
|---|
여기에서 사용된 모델 아키텍처는 Show, Attend and Tell: Neural Image Caption Generation with Visual Attention의 영감을 받았지만 2단 레이어 트랜스포머 디코더를 사용하도록 업데이트되었습니다. 이 튜토리얼을 최대한 활용하려면 텍스트 생성, seq2seq 모델 및 어텐션 또는 트랜스포머를 약간 경험해 보셔야 합니다.
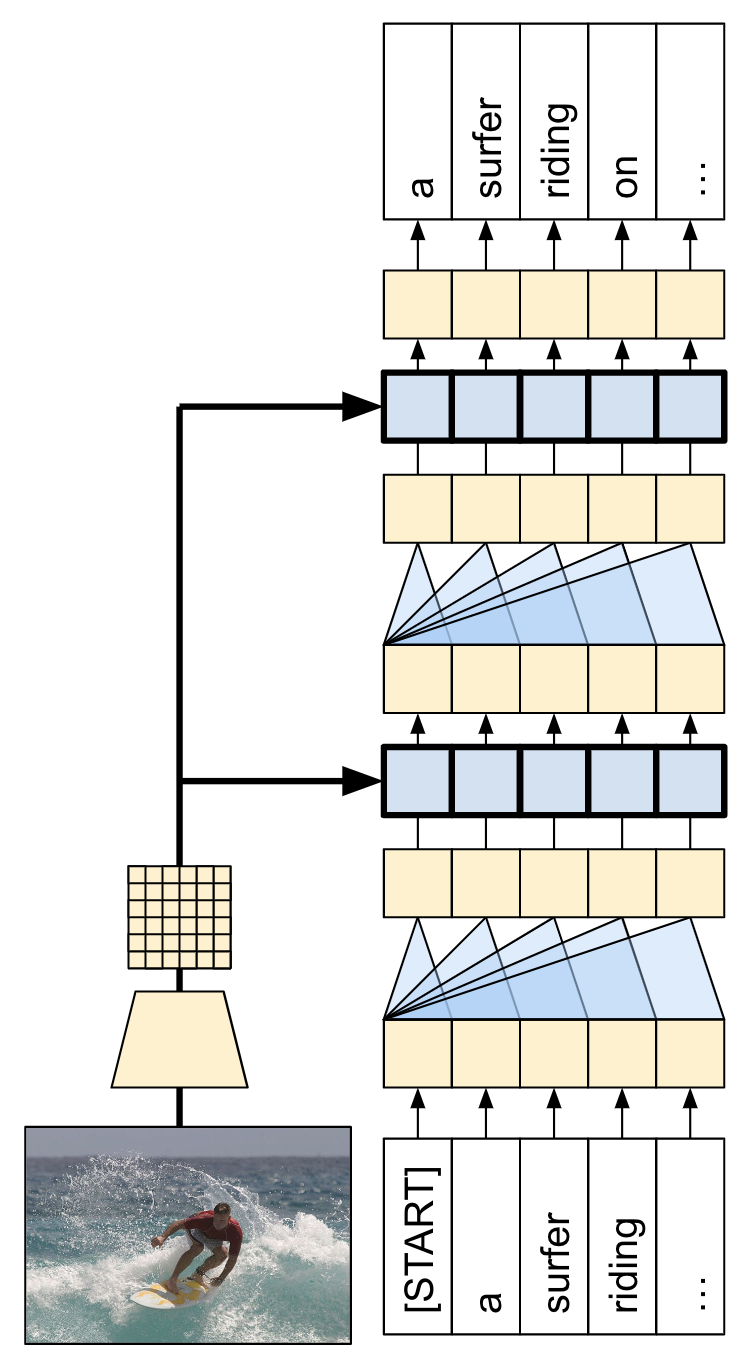
이 튜토리얼에서 빌드된 모델 아키텍처는 아래와 같습니다. 특성은 이미지에서 추출되어 트랜스포머 디코더의 크로스 어텐션 레이어로 전달되었습니다.
| 모델 아키텍처 |
|---|
|
트랜스포머 디코더는 주로 어텐션 레이어에서 빌드됩니다. 이는 셀프 어텐션을 사용하여 생성되는 시퀀스를 처리하고 크로스 어텐션을 사용하여 이미지를 처리합니다.
크로스 어텐션 레이어의 어텐션 가중치를 검사하면 모델이 단어를 생성할 때 이미지의 어떤 부분을 모델이 보고 있는지 알 수 있습니다.

이 노트북은 엔드 투 엔드 예제입니다. 노트북을 실행하면 노트북은 데이터세트를 다운로드하며 이미지 특성을 추출하고 캐싱하여 디코더 모델을 훈련합니다. 그런 다음 모델을 사용하여 새로운 이미지에 캡션을 생성합니다.
설치
이 튜토리얼은 주로 데이터세트를 로딩하기 위해 가져오기를 많이 사용합니다.
[선택 사항] 데이터 처리
이 섹션은 캡션 데이터세트를 다운로드하고 훈련을 위해 이를 준비합니다. 입력 텍스트를 토큰화하고 사전 훈련된 특정 추출 모델을 통해 모든 이미지를 실행한 결과를 캐싱합니다. 이는 이 섹션의 모든 것을 이해하는 데 중요하지는 않습니다.
데이터세트 선택
이 튜토리얼은 데이터세트를 선택할 수 있도록 설정되었습니다. Flickr8k 또는 Conceptual Captions 데이터세트의 작은 슬라이스 중 하나입니다. 이 두 가지는 처음부터 다운로드되고 변환되었지만 TensorFlow Datasets(Coco Captions 및 전체 Conceptual Captions)에서 사용할 수 있는 캡션 데이터세트를 사용하기 위해 튜토리얼을 변환하는 것은 어렵지 않습니다.
Flickr8k
Conceptual Captions
데이터세트 다운로드
Flickr8k는 이미지당 5개의 캡션과 더욱 소규모의 다운로드를 위한 더 많은 데이터를 포함하고 있어 좋은 선택입니다.
위의 두 데이터세트에 대한 로더는 (image_path, captions) 쌍을 포함하는 tf.data.Dataset를 반환합니다. Conceptual Captions는 이미지당 캡션 1개를 포함하는 한편 Flickr8k는 이미지당 5개의 캡션을 포함합니다.
이미지 특성 추출기
각 이미지에서 특성을 추출하기 위해 이미지 모델(imagenet에서 사전 훈련됨)을 사용할 것입니다. 모델은 이미지 분류기로 훈련되었지만, 설정 include_top=False는 최종 분류 레이어 없이 모델을 반환하므로 특성 맵의 최종 레이어를 사용할 수 있습니다.
다음은 모델에 맞게 이미지를 로드하고 크기를 조정하는 함수입니다.
모델은 입력 매치의 각 이미지에 대한 특성 맵을 반환합니다.
텍스트 토크나이저/벡터라이저 설정
TextVectorization 레이어를 사용하여 다음 단계에 따라 텍스트 캡션을 정수 시퀀스로 변환하게 됩니다.
adapt를 사용하여 모든 캡션을 반복하고 캡션을 단어로 분할하고 상위 단어의 어휘를 계산합니다.
각 단어를 어휘의 인덱스에 매핑하여 모든 캡션을 토큰화합니다. 모든 출력 시퀀스는 길이 50으로 채워집니다.
단어에서 인덱스로, 인덱스에서 단어로의 매핑을 생성하여 결과를 표시합니다.
데이터세트 준비
train_raw 및 test_raw 데이터세트는 1:많은 (image, captions) 쌍을 포함합니다.
이 함수는 이미지를 복제하여 캡션에 1:1 이미지가 있게 됩니다.
keras 훈련과 호환되려면 데이터세트는 (inputs, labels) 쌍을 포함해야 합니다. 텍스트 생성의 경우 토큰은 한 단계 이동된 입력과 라벨입니다. 이 함수는 (images, texts) 쌍을 ((images, input_tokens), label_tokens) 쌍으로 변환합니다.
이 함수는 연산을 데이터세트에 추가합니다. 단계는 다음과 같습니다.
이미지를 로드합니다(로드에 실패한 이미지는 무시합니다).
이미지를 복제하여 캡션의 숫자와 매칭합니다.
image, caption쌍을 섞고 리배치합니다.텍스트를 토큰화하고 토큰을 이동하여
label_tokens을 추가합니다.RaggedTensor표현에서 텍스트를 패딩 처리된 밀도 높은Tensor표현으로 변환합니다.
모델에 특성 추출기를 설치하고 다음과 같이 데이터세트에서 훈련할 수 있습니다.
[선택 사항] 이미지 특성 캐싱하기
이미지 특성 추출기가 변경되지 않으며 이 튜토리얼은 이미지 증강을 사용하지 않으므로 이미지 특성은 캐싱될 수 있습니다. 텍스트 토큰화의 경우도 동일합니다. 캐시를 설정하는 데 드는 시간은 훈련 및 검증 중 각 epoch에서 다시 획득됩니다. 아래의 코드는 두 개의 함수인 save_dataset 및 load_dataset를 정의합니다.
훈련을 위한 데이터 준비
이러한 사전 처리 단계 후, 데이터세트는 다음과 같습니다.
데이터세트는 이제 keras 훈련에 적합한 (input, label) 쌍을 반환합니다. inputs은 (images, input_tokens) 쌍입니다. images는 특성-추출기 모델로 처리됩니다. input_tokens의 각 위치의 경우 모델은 지금까지의 텍스트를 보고 labels의 같은 위치에서 나열된 다음 텍스트를 예측하려고 시도합니다.
입력 토큰 및 라벨은 동일하며, 다음과 같이 한 단계만 이동하면 됩니다.
트랜스포머 디코더 모델
이 모델은 사전 훈련된 이미지 인코더가 충분하다고 가정하며 텍스트 디코더를 빌드하는 데만 집중합니다. 이 튜토리얼은 2단 레이어 트렌스포머 디코더를 사용합니다.
이 구현은 Transformers 튜토리얼의 구현과 거의 동일합니다. 더 자세한 내용은 이를 다시 참조하세요.
| 트랜스포머 인코더 및 디코더. |
|---|
| |
모델은 다음과 같은 세 가지 주요 부분으로 구현됩니다.
입력 - 토큰 임베딩 및 위치 인코딩(
SeqEmbedding).디코더 - 각각 다음을 포함하는 트랜스포머 디코더 레이어(
DecoderLayer)의 스택추후에 각 출력 위치가 지금까지 출력에 대해 처리할 수 있는 인과적 셀프 어텐션(
CausalSelfAttention).각 출력 위치가 입력 이미지를 추리할 수 있는 크로스 어텐션 레이어(
CrossAttention).각 출력 위치를 독립적으로 추가로 처리하는 피드 포워드 네트워크(
FeedForward) 레이어.
출력 - 출력 어휘에 대한 멀티 클래스 분류.
입력
입력 텍스트는 이미 토큰으로 분할되고 ID 시퀀스로 변환되었습니다.
CNN 또는 RNN와는 다르게 트랜스포머의 어텐션 레이어는 시퀀스의 순서에 대해 변하지 않는다는 점을 기억하세요. 몇몇 위치 입력이 없다면 시퀀스가 아닌 순서 없는 세트만 봅니다. 따라서 각 토큰 ID에 대한 단순한 벡터 임베딩 외에도 임베딩 레이어는 시퀀스 내 각 위치에 대한 임베딩 또한 포함합니다.
SeqEmbedding 레이어는 다음과 같이 정의됩니다.
각 토큰에 대한 임베딩 벡터를 검색합니다.
각 시퀀스 위치에 대한 임베딩 벡터를 검색합니다.
두 개를 모두 합합니다.
mask_zero=True를 사용하여 모델에 대한 keras 마스크를 초기화합니다.
참고: 이 구현은 Transformer 튜토리얼에서와 같이 고정된 임베딩을 사용하는 대신 위치 임베딩을 학습합니다. 임베딩을 학습하는 것은 코드가 약간 적지만 더 긴 시퀀스로 일반화되지는 않습니다.
디코더
디코더는 표준 트랜스포머 디코더로, 각 세 개의 하위 레이어인 CausalSelfAttention, CrossAttention 및 FeedForward를 포함하는 DecoderLayers의 스택을 포함합니다. 구현은 Transformer 튜토리얼과 거의 동일하며, 자세한 내용은 이를 참조하세요.
다음은 CausalSelfAttention 레이어입니다.
아래는 CrossAttention 레이어입니다. return_attention_scores를 사용하는 데 유의하세요.
아래는 FeedForward 레이어입니다. layers.Dense 레이어는 입력의 최종 축에 적용된다는 점을 기억하세요. 입력의 형태는 (batch, sequence, channels)이므로 batch 및 sequence 축에 걸쳐 포인트별로 자동으로 적용됩니다.
다음으로 이러한 세 가지 레이어를 더 큰 규모의 DecoderLayer에 배열합니다. 각 디코더 레이어는 시퀀스에 세 개의 더 작은 레이어를 적용합니다. 각 하위 레이어 다음의 out_seq 형태는 (batch, sequence, channels)입니다. 디코더 레이어는 또한 추후 시각화를 위한 attention_scores를 반환합니다.
출력
출력 레이어는 각 위치에서 각 토큰에 대한 로짓 예측을 생성하려면 최소한 layers.Dense 레이어가 필요합니다.
하지만 이 작업을 좀 더 잘 수행할 수 있도록 추가할 수 있는 몇 가지 다른 특성이 있습니다.
잘못된 토큰 처리: 모델은 텍스트를 생성합니다. 패드, 알 수 없는, 또는 시작 토큰(
'','[UNK]','[START]')을 생성해서는 안됩니다. 따라서 이들에 대한 편향을 큰 음수 값으로 설정합니다.참고: 손실 함수의 이러한 토큰 역시 무시해야 합니다.
스마트 초기화: 밀도가 높은 레이어의 기본 초기화는 거의 균일한 확률로 각 토큰을 초기에 예측하는 모델을 제공합니다. 실제 토큰 분포는 균일한 것과는 거리가 멉니다. 출력 레이어의 초기 편향을 위한 최적값은 각 토큰의 확률 로그입니다. 따라서
adapt메서드를 포함해 토큰의 수를 세고 최적의 초기 편향을 설정합니다. 이는 균일한 분포(log(vocabulary_size))의 엔트로피로부터의 분포의 한계 엔트로피(-p*log(p))로 초기 손실을 줄입니다.
스마트 초기화는 초기 손실을 다음과 같이 상당히 줄입니다.
모델 빌드하기
모델을 빌드하려면 몇몇 부분을 조합해야 합니다.
이미지
feature_extractor및 텍스트tokenizer.토큰 ID의 배치를 벡터
(batch, sequence, channels)로 변환하기 위한seq_embedding레이어.텍스트 및 이미지 데이터를 처리할
DecoderLayers레이어의 스택.다음 단어가 무엇이어야 하는지에 대한 포인트별 예측을 반환하는
output_layer.
훈련을 위해 모델을 호출하면 image, txt 쌍을 수신합니다. 이 함수를 더욱 유용하게 하려면 입력에 대해 더 유연해지세요.
이미지에 3개의 채널이 있다면 feature_extractor를 통해 실행합니다. 그렇지 않으면 이미 실행된 것으로 가정합니다.
텍스트에 dtype
tf.string이 있다면 토크나이저를 통해 실행하세요.
그런 다음 모델을 실행하는 것은 몇 단계만 수행하면 됩니다.
추출된 이미지 특성을 평면화하여 디코더 레이어에 대한 입력이 될 수 있도록 합니다.
토큰 임베딩을 검색합니다.
이미지 특성 및 텍스트 임베딩에서
DecoderLayer의 스택을 실행합니다.출력 레이어를 실행하여 각 위치에서 다음 토큰을 예측합니다.
캡션 생성하기
훈련을 시작하기 전에, 코드를 약간 작성해 캡션을 생성합니다. 이를 사용하여 훈련이 어떻게 진행되는지 확인합니다.
다음과 같이 테스트 이미지를 다운로드하여 시작합니다.
이 모델로 이미지를 캡션하려면 다음을 수행합니다.
img_features추출[START]토큰으로 출력 토큰 목록 초기화.img_features및tokens를 모델로 전달.이는 로짓 목록을 반환합니다.
이러한 로짓을 기반으로 다음 토큰을 선택합니다.
토큰 목록에 이를 추가하고 루프를 계속합니다.
'[END]'토큰이 생성되었다면 루프를 벗어나세요.
이를 위해 "간단한" 메서드를 추가합니다.
다음은 모델의 훈련되지 않은, 해당 이미지를 위해 생성된 일부 캡션으로 아직 의미가 그다지 없습니다.
온도 매개변수를 통해 다음 세 모드 사이에 삽입할 수 있습니다.
그리디 디코딩(
temperature=0.0) - 각 단계에서 가장 확률이 높은 다음 토큰을 선택합니다.로짓(
temperature=1.0)에 따른 랜덤 샘플링.균일 랜덤 샘플링(
temperature >> 1.0).
모델이 훈련되지 않았고 빈도 기반 초기화를 사용하였으므로 "그리디" 출력은 (우선) 일반적으로 가장 일반적인 토큰인 ['a', '.', '[END]']만 포함합니다.
훈련
모델을 훈련하려면 다음과 같은 몇몇 추가 컴포넌트가 필요합니다.
손실 및 메트릭
옵티마이저
선택적 콜백
손실 및 메트릭
다음은 마스킹 된 손실 및 정확성에 대한 구현입니다.
손실에 대한 마스크를 계산할 때 loss < 1e8를 주의하세요. 이 항은 banned_tokens에 대한 인공적이고 불가능할 정도로 높은 손실을 버립니다.
콜백
훈련 중 피드백을 위해 keras.callbacks.Callback을 설정해 각 epoch의 끝에 서퍼 이미지에 대한 일부 캡션을 생성합니다.
이는 첫 번째가 "그리디"인 이전과 같은 이전 예시와 같은 세 개의 출력 문자열을 생성하여 각 단계에서 로짓의 argmax를 선택합니다.
또한 callbacks.EarlyStopping을 사용하여 모델이 과적합을 시작할 때 훈련을 중단합니다.
훈련
훈련을 구성하고 실행합니다.
빈도 보고를 더 많이 하려면, Dataset.repeat() 메서드를 사용하고 steps_per_epoch 및 validation_steps 인수를 Model.fit으로 설정합니다.
Flickr8k에서 이러한 설정을 통해 데이터세트에 대한 전체 전달은 배치가 900개 이상이지만 보고-epoch 아래에는 100개의 단계가 있습니다.
훈련 실행 동안의 손실 및 정확성 플롯:
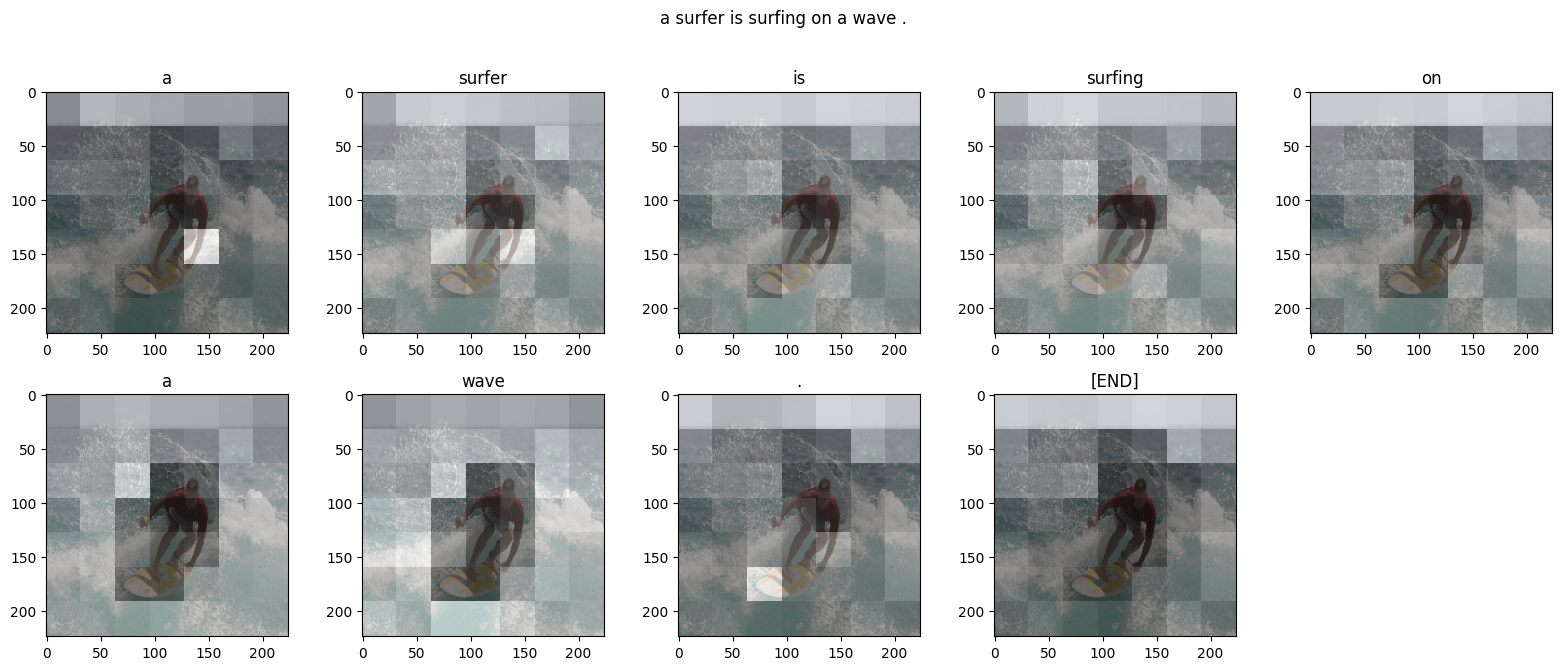
어텐션 플롯
이제 훈련된 모델을 사용하여 이미지에서 해당 simple_gen 메서드를 실행합니다.
출력을 토큰으로 다시 분할합니다.
각 DecoderLayers는 CrossAttention 레이어에 대한 어텐션 스코어를 캐싱합니다. 각 어텐션 맵의 형태는 (batch=1, heads, sequence, image)입니다.
따라서 image 축을 height, width로 다시 분할하는 한편 batch 축을 따라 맵을 스택한 다음 (batch, heads) 축에 대해 평균을 냅니다.
이제 각 시퀀스 예측을 위한 단일 어텐션 맵이 하나 있습니다. 각 맵의 값은 합계가 1이어야 합니다.
따라서 다음은 출력에 대한 각 토큰을 생성하는 동안 모델이 어텐션에 주목하는 곳입니다.
이제 더 유용한 함수로 함께 다음과 같이 통합합니다.
자체 이미지로 시도해보기
재미를 위해 방금 훈련한 모델로 자체 이미지를 캡션하는 데 사용할 수 있는 방법을 제공했습니다. 상대적으로 적은 양의 데이터로 훈련되었으므로 이미지가 훈련 데이터와 다를 수 있습니다(결과가 이상할 수 있습니다!).