
Path: blob/master/site/ko/tutorials/text/nmt_with_attention.ipynb
38594 views
Copyright 2019 The TensorFlow Authors.
어텐션을 사용한 인공 신경망 기계 번역
 깃허브(GitHub) 소스 보기
깃허브(GitHub) 소스 보기이 노트북은 스페인어를 영어로 변역하기 위해 시퀀스-투-시퀀스 (seq2seq) 모델을 훈련시킵니다. 또한 이 노트북은 시퀀스-투-시퀀스 모델의 사전적인 지식을 요구하는 심화된 예제입니다.
이 노트북에서 신경망 기계 번역 모델을 훈련하면 *"¿todavia estan en casa?"*와 같은 스페인 문장을 입력했을 때 *"are you still at home?"*처럼 영어로 번역된 문장을 얻을 수 있을 것입니다
번역의 질은 간단한 예제로는 타당하지만 시각화된 어텐션 플롯은 아마 더 흥미로울 것입니다. 아래의 플롯은 모델을 훈련하는 동안에 입력 문장의 각 단어가 갖고 있는 모델 어텐션을 시각화하여 보여준 것입니다:
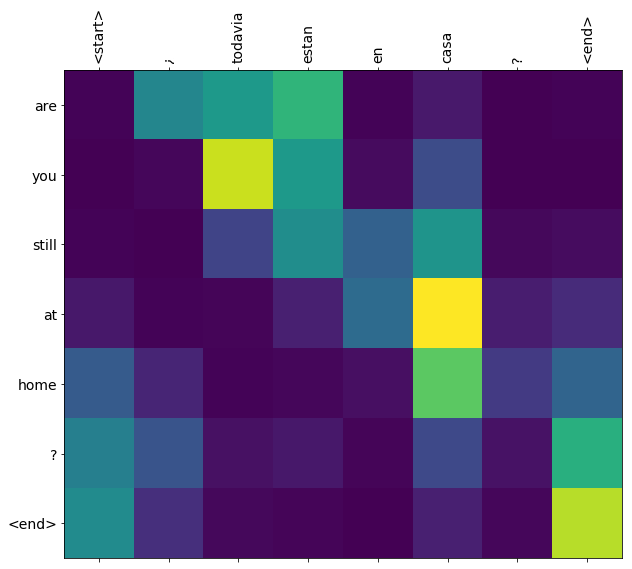
노트: 이 예제를 단일 P100 GPU에서 실행하기 위해서는 약 10분 정도 걸립니다.
데이터셋 다운로드하고 준비하기
http://www.manythings.org/anki/ 에서 제공한 언어 데이터셋을 사용할 것입니다. 이 데이터셋은 언어 번역의 쌍이 다음과 같은 형식으로 포함되어 있습니다:
다양한 언어가 이용가능하지만 이 예제에서는 영어-스페인 데이터셋을 사용할 것입니다. 편의를 위해서 이 데이터셋의 복사본을 Google Cloud에서 호스팅 했지만 직접 다운로드해야 합니다. 데이터셋을 다운로드한 후에 데이터를 준비하고자 다음의 단계를 수행합니다.
각 문장에 start와 end 토큰을 추가합니다.
특정 문자를 제거함으로써 문장을 정리합니다.
단어 인덱스와 아이디(ID) 인덱스를 생성합니다. (단어 → 아이디(ID), 아이디(ID) → 단어로 매핑된 딕셔너리).
각 문장을 입력층의 최대 길이만큼 패딩(padding)을 수행합니다.
더 빠른 실행을 위해 데이터셋의 크기 제한하기(선택)
10만개 이상의 문장이 있는 완전한 데이터셋을 훈련하는 것은 오랜 시간이 걸립니다. 훈련 속도를 높이기 위해서 데이터셋의 크기를 3만개의 문장으로 제한합니다. (물론, 번역의 질은 데이터가 적어질수록 저하됩니다):
tf.data 데이터셋 생성하기
인코더 모델과 디코더 모델 쓰기
어텐션(attention)을 가진 인코더-디코더 모델을 수행합니다. 어텐션(attention)은 TensorFlow Neural Machine Translation (seq2seq) tutorial에서 읽을 수 있습니다. 이 예제는 더 최신의 API 집합을 사용합니다. 이 노트북은 seq2seq 튜토리얼로부터 어텐션 방정식을 수행합니다. 아래의 다이어그램은 각각의 입력 단어가 어텐션 메커니즘에 의해 가중치가 할당된 모습입니다. 이러한 어텐션 메커니즘은 디코더가 문장에서 다음 단어를 예측하기 위해 사용됩니다. 아래의 그림과 공식은 Luong's paper에서 나온 어텐션 메커니즘의 예시입니다.
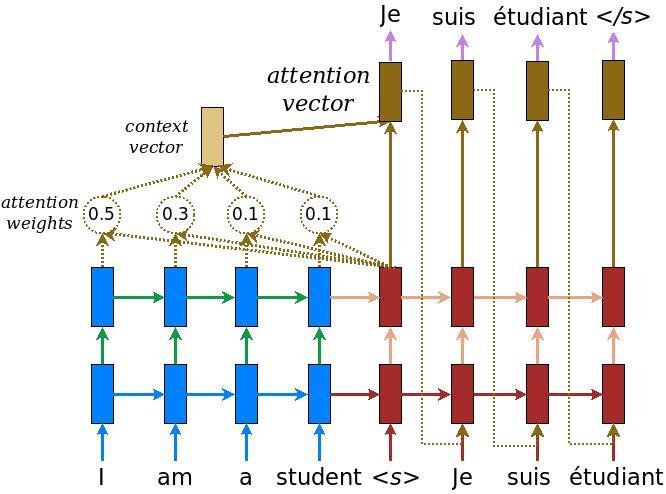
입력은 *(batch_size, max_length, hidden_size)*의 형태로 이루어진 인코더 결과와 *(batch_size, hidden_size)*쌍으로 이루어진 인코더 은닉 상태(hidden state)를 제공하는 인코더 모델을 통해 입력됩니다.
아래의 공식은 위에서 사용한 방정식을 나타낸 것이다:
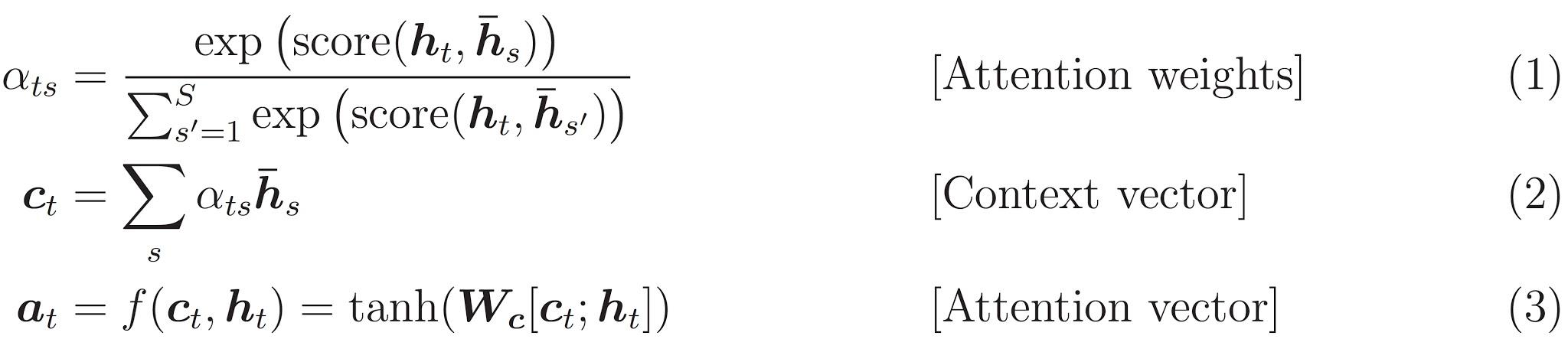
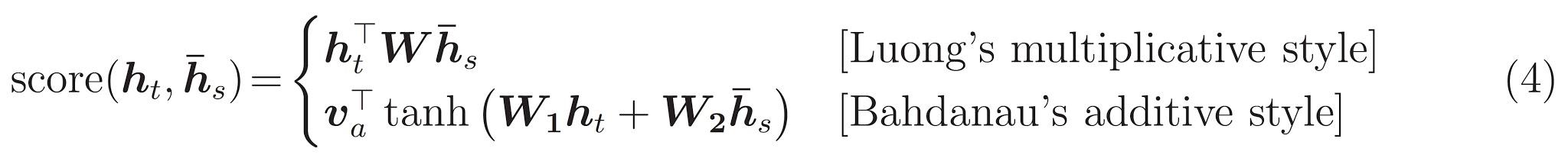
이 튜토리얼은 인코더를 위해 Bahdanau 어텐션을 사용합니다. 단순화된 형태로 쓰기 전에 표기법을 아래와 같이 정의합니다:
FC = 완전 연결(Dense)층
EO = 인코더 결과
H = 은닉 상태(hidden state)
X = 디코더에 대한 입력
그리고 다음은 슈도코드입니다:
스코어(score)는 FC(tanh(FC(EO) + FC(H)))로 계산합니다.어텐션 가중치는 softmax(score, axis = 1)로 계산합니다. 기본적으로 소프트맥스는 마지막 축을 적용하지만 스코어(score)의 형태가 *(batch_size, max_length, hidden_size)*이기 때문에 첫번째 축을 적용합니다.Max_length은 입력의 길이입니다. 각각의 입력에 가중치를 할당하려고 시도하기 때문에 소프트맥스는 그 축을 적용할 수 있습니다.컨텍스트 벡터(context vector)는 sum(어텐션 가중치 * EO, axis = 1)로 계산합니다. 위와 같은 이유로 첫번째 축을 선택합니다.임베딩 결과(embedding output)는 디코더 X에 대한 입력이 임베딩층을 통과한 결과입니다.병합된 벡터(merged vector)는 concat(임베딩 결과, 컨텍스트 백터(context vector))와 같습니다.그런 다음 병합된 벡터는 GRU에 주어집니다.
매 단계마다 모든 벡터의 형태는 코드내 주석에 명시되어 있습니다:
최적화 함수와 손실 함수 정의하기
체크포인트 (객체 기반 저장)
언어 모델 훈련하기
인코더 결과와 *인코더 은닉 상태(hidden state)*를 반환하는 인코더를 통해서 입력을 전달합니다.
인코더 결과, 인코더 은닉 상태(hidden state), 디코더 입력 (start 토큰)을 디코더에 전달합니다.
전달 받은 값을 통해 디코더는 예측 값과 *디코더 은닉 상태(hidden state)*를 반환합니다.
그 다음에 디코더 은닉 상태(hidden state)가 다시 모델에 전달되고 예측 값을 사용하여 손실을 계산합니다.
디코더에 대한 다음 입력을 결정하기 위해서 *교사 강요(teacher forcing)*를 사용합니다.
*교사 강요(teacher forcing)*는 타겟 단어가 디코더에 다음 입력으로 전달하기 위한 기술입니다.
마지막 단계는 그레디언트(gradients)를 계산하여 이를 옵티마이저(optimizer)와 역전파(backpropagate)에 적용합니다.
훈련된 모델로 번역하기
평가 함수는 여기서 *교사 강요(teacher forcing)*를 사용하기 못하는 것을 제외하고는 훈련 루프와 비슷합니다. 각 마지막 시점(time step)에서 이전 디코더 인코더의 결과와 은닉 상태(hidden state)를 가진 예측 값을 디코더에 입력합니다.
모델이 *end 토큰을 예측할 때 예측하는 것을 중지합니다. *.
그리고 매 마지막 시점(time step)에 대한 어텐션 가중치를 저장합니다.
노트: 인코더 결과는 하나의 입력에 대해 단 한 번만 계산됩니다.
마지막 체크포인트(checkpoint)를 복원하고 테스트하기
다음 단계
앞서 영어-스페인어 데이터셋을 이용해 모델을 훈련하였습니다. 이제 영어-프랑스어, 영어-한국어 등의 댜양한 다른 언어 데이터셋을 활용하여 모델을 훈련시켜 보십시오.
또한 이 예제에서는 데이터셋을 제한하여 모델을 만들어 보았습니다. 이제 더 많은 데이터셋 혹은 더 많은 에포크(epochs)를 적용하여 모델을 훈련해보십시오.