
Path: blob/master/site/ko/tutorials/understanding/sngp.ipynb
38561 views
Copyright 2021 The TensorFlow Authors.
SNGP를 사용한 불확실성 인식 딥 러닝
 GitHub에서 보기
GitHub에서 보기의료 의사 결정 및 자율 주행과 같이 안전이 중요한 AI 애플리케이션 또는 데이터에 본질적으로 노이즈가 많은 경우(예: 자연어 이해) 딥 분류기가 불확실성을 안정적으로 정량화하는 것이 중요합니다. 딥 분류기는 자체적인 한계와 언제 인간 전문가에게 제어권을 넘겨야 하는지 알 수 있어야 합니다. 이 튜토리얼은 **스펙트럼 정규화 신경 가우시안 프로세스(SNGP{.external})**라는 기술을 사용하여 불확실성을 정량화하는 딥 분류기의 능력을 향상시키는 방법을 보여줍니다.
SNGP의 핵심 아이디어는 네트워크에 간단한 수정을 적용하여 딥 분류기의 거리 인식을 향상시키는 것입니다. 모델의 거리 인식은 모델의 예측 확률이 테스트 예제와 훈련 데이터 사이의 거리를 어떻게 반영하는지 측정한 것입니다. 이것은 표준 확률 모델(예: RBF 커널이 있는 가우시안 프로세스{.external})에 일반적이지만 딥 신경망을 사용한 모델에는 부족한 바람직한 속성입니다. SNGP는 예측 정확도를 유지하면서 이 가우시안 프로세스 동작을 딥 분류기에 주입하는 간단한 방법을 제공합니다.
이 튜토리얼은 scikit-learn의 두 개의 달{.external} 데이터세트에 대한 ResNet(deep residual network) 기반 SNGP 모델을 구현하고 이 모델의 불확실성 표면을 Monte Carlo 드롭아웃{.external} 및 딥 앙상블{.external}의 두 가지 주요 불확실성 접근 방식의 불확실성 표면과 비교합니다.
이 튜토리얼은 장난감 2D 데이터세트의 SNGP 모델을 보여줍니다. BERT 기반을 사용하여 실제 자연어 이해 작업에 SNGP를 적용하는 예는 SNGP-BERT 튜토리얼을 확인하세요. 다양한 벤치마크 데이터세트(예: CIFAR-100, ImageNet, Jigsaw 독성 감지)에 대한 SNGP 모델(및 기타 여러 불확실성 방법)의 고품질 구현은 불확실성 베이스라인{.external} 벤치마크를 참조하세요.
SNGP 소개
SNGP는 유사한 수준의 정확도와 대기 시간을 유지하면서 딥 분류기의 불확실성 품질을 개선하는 간단한 접근 방식입니다. ResNet(deep residual network)가 주어지면 SNGP는 모델에 두 가지 간단한 변경을 수행합니다.
숨겨진 잔차 레이어에 스펙트럼 정규화를 적용합니다.
밀집 출력 레이어를 가우시안 프로세스 레이어로 대체합니다.
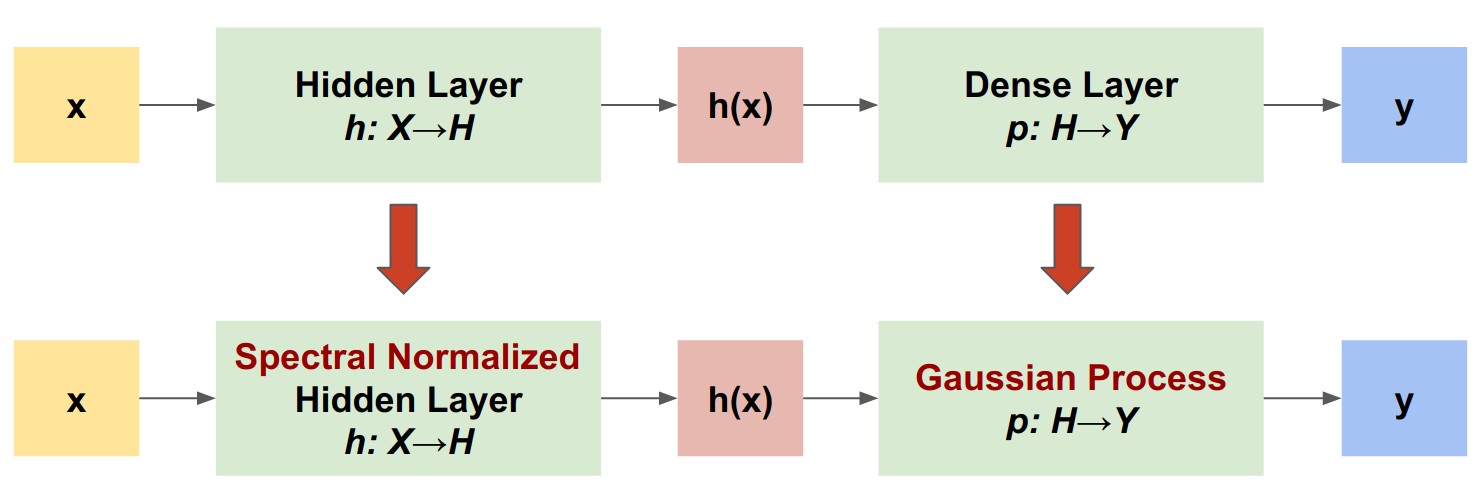
다른 불확실성 접근 방식(예: Monte Carlo 드롭아웃 또는 딥 앙상블)과 비교할 때 SNGP에는 다음과 같은 몇 가지 장점이 있습니다.
광범위한 첨단 잔차 기반 아키텍처(예: (Wide) ResNet, DenseNet 또는 BERT)에서 작동합니다.
앙상블 평균에 의존하지 않는 단일 모델 방법입니다. 따라서 SNGP는 단일 결정성 네트워크와 유사한 수준의 대기 시간을 가지며 ImageNet{.external} 및 Jigsaw Toxic Comments 분류{.external}와 같은 대규모 데이터세트로 쉽게 확장할 수 있습니다.
거리 인식 속성 덕분에 강력한 도메인 외부 감지 성능을 제공합니다.
이 방법의 단점은 다음과 같습니다.
SNGP의 예측 불확실성은 라플라스 근사{.external}를 사용하여 계산됩니다. 따라서 이론적으로 SNGP의 사후 불확실성은 정확한 가우시안 프로세스의 불확실성과 다릅니다.
SNGP 훈련에는 새 epoch가 시작될 때 공분산 재설정 단계가 필요합니다. 이로 인해 훈련 파이프라인의 복잡성이 약간 커질 수 있습니다. 이 튜토리얼은 Keras 콜백을 사용하여 이를 구현하는 간단한 방법을 보여줍니다.
설치
시각화 매크로를 정의합니다.
두 개의 달 데이터세트
scikit-learn 두 개의 달 데이터세트{.external}로부터 훈련 및 평가 데이터세트를 만듭니다.
전체 2D 입력 공간에서 모델의 예측 동작을 평가합니다.
모델 불확실성을 평가하려면 세 번째 클래스에 속하는 도메인 외(OOD) 데이터세트를 추가합니다. 모델은 훈련 중에 이러한 OOD 예제를 관찰하지 않습니다.
여기서 파란색과 주황색은 양수 및 음수 클래스를 나타내고 빨간색은 OOD 데이터를 나타냅니다. 불확실성을 잘 정량화하는 모델은 훈련 데이터에 근접할 때(즉, 가 0 또는 1에 가까움) 확실해지고 훈련 데이터 영역에서 멀어질 때(즉, 가 0.5에 가까움) 불확실해질 것으로 예상됩니다.
결정성 모델
모델 정의하기
(베이스라인) 결정성 모델에서 시작: 드롭아웃 정규화가 있는 멀티 레이어 ResNet(residual network).
이 튜토리얼은 128개의 숨겨진 유닛이 있는 6단 레이어 ResNet을 사용합니다.
모델 훈련하기
SparseCategoricalCrossentropy를 손실 함수로 사용하고 Adam 옵티마이저를 사용하도록 훈련 매개변수를 구성합니다.
배치 크기가 128인 100회 epoch에 대해 모델을 훈련합니다.
불확실성 시각화
이제 결정성 모델의 예측을 시각화합니다. 먼저 클래스 확률을 플로팅합니다:
이 플롯에서 노란색과 자주색은 두 클래스에 대한 예측 확률입니다. 이 결정성 모델은 두 개의 알려진 클래스(파란색과 주황색)를 비선형 결정 경계로 분류하는 작업을 효과적으로 수행했습니다. 그러나 이는 거리를 인식하지 않으며 관찰되지 않은 빨간색 도메인 외(OOD) 예제를 주황색 클래스로 확실하게 분류했습니다.
예측 분산을 계산하여 모델 불확실성 시각화:
이 플롯에서 노란색은 높은 불확실성을 나타내고 보라색은 낮은 불확실성을 나타냅니다. 결정성 ResNet의 불확실성은 결정 경계로부터 테스트 예제의 거리에만 의존합니다. 이로 인해 훈련 영역을 벗어날 때 모델이 과도한 확신을 갖게 됩니다. 다음 섹션에서는 이 데이터세트에서 SNGP가 어떻게 다르게 작동하는지 보여줍니다.
SNGP 모델
SNGP 모델 정의
이제 SNGP 모델을 구현해 보겠습니다. SNGP 구성 요소인 SpectralNormalization 및 RandomFeatureGaussianProcess는 모두 tensorflow_model의 내장 레이어에서 사용할 수 있습니다.
이 두 구성 요소를 자세히 살펴보겠습니다. 전체 SNGP 모델 섹션으로 이동하여 SNGP의 구현 방법을 알아볼 수도 있습니다.
SpectralNormalization 래퍼
SpectralNormalization{.external}은 Keras 레이어 래퍼입니다. 다음과 같이 기존 밀집 레이어에 적용할 수 있습니다.
스펙트럼 정규화는 스펙트럼 표준(즉, 의 가장 큰 고유값)을 목표 값 norm_multiplier로 점진적으로 유도하여 숨겨진 가중치 를 정규화합니다.
참고: 일반적으로 norm_multiplier를 1보다 작은 값으로 설정하는 것이 좋습니다. 그러나 실제로는 딥 네트워크가 충분한 표현력을 갖도록 더 큰 값으로 완화할 수도 있습니다.
가우시안 프로세스(GP) 레이어
RandomFeatureGaussianProcess{.external}는 딥 신경망으로 엔드 투 엔드 훈련이 가능한 가우시안 프로세스 모델에 무작위 특성 기반 근사{.external}를 구현합니다. 가우시안 프로세스 레이어는 내부에서 2단 레이어 네트워크를 구현합니다.
Here, is the input, and and are frozen weights initialized randomly from Gaussian and Uniform distributions, respectively. (Therefore, are called "random features".) is the learnable kernel weight similar to that of a Dense layer.
GP 레이어의 주요 매개변수는 다음과 같습니다.
units: 출력 로짓의 차원입니다.num_inducing: 숨겨진 가중치 의 차원 입니다. 기본값은 1024입니다.normalize_input: 입력 에 레이어 정규화를 적용할지 여부를 나타냅니다.scale_random_features: 숨겨진 출력에 척도를 적용할지 여부를 나타냅니다.
참고: 학습률에 민감한 딥 신경망(예: ResNet-50 및 ResNet-110)의 경우 일반적으로 normalize_input=True로 설정하여 훈련을 안정화하고 scale_random_features=False로 설정하여 GP 레이어를 통과할 때 학습률이 예상치 못하게 수정되는 것을 방지하는 것이 좋습니다.
gp_cov_momentum은 모델 공분산이 계산되는 방식을 제어합니다. 양수 값(예:0.999)으로 설정하면 모멘텀 기반 이동 평균 업데이트(배치 정규화와 유사)를 사용하여 공분산 행렬이 계산됩니다.-1로 설정하면 공분산 행렬이 모멘텀 없이 업데이트됩니다.
참고: 모멘텀 기반 업데이트 방법은 배치 크기에 민감할 수 있습니다. 따라서 일반적으로 공분산을 정확하게 계산하려면 gp_cov_momentum=-1을 설정하는 것이 좋습니다. 이것이 제대로 작동하려면 동일한 데이터를 두 번 계산하지 않도록 새 epoch가 시작될 때 공분산 행렬 추정기를 재설정해야 합니다. RandomFeatureGaussianProcess의 경우 이를 위해 reset_covariance_matrix()를 호출할 수 있습니다. 다음 섹션에서는 Keras의 내장 API를 사용하여 이를 쉽게 구현하는 방법을 보여줍니다.
형상이 (batch_size, input_dim)인 배치 입력이 주어지면 GP 레이어는 예측을 위한 logits 텐서(형상 (batch_size, num_classes)), 그리고 배치 로짓의 사후 공분산 행렬인 covmat 텐서(형상 (batch_size, batch_size))를 반환합니다.
참고: 이 SNGP 모델 구현에서 모든 클래스에 대한 예측 로짓 는 훈련 데이터에서 사이의 거리를 설명하는 동일한 공분산 행렬인 를 공유합니다.
이론적으로, 다양한 클래스에 대해 서로 다른 분산 값을 계산하도록 알고리즘을 확장할 수 있습니다(원본 SNGP 논문{.external}에 소개된 대로). 그러나 이것을 출력 공간이 큰 문제(예: ImageNet을 사용한 분류 또는 언어 모델링)로 확장하기는 어렵습니다.
기본 클래스 DeepResNet이 주어지면 SNGP 모델은 잔여 네트워크의 숨겨진 레이어와 출력 레이어를 수정하여 쉽게 구현할 수 있습니다. model.fit() API와의 호환성을 위해 훈련 중에 logits만 출력하도록 모델의 call() 메서드도 수정합니다.
결정성 모델과 동일한 아키텍처를 사용합니다.
DeepResNetSNGP 모델 클래스에 이 콜백을 추가합니다.
모델 훈련하기
tf.keras.model.fit을 사용하여 모델을 훈련합니다.
불확실성 시각화
먼저 예측 로짓과 분산을 계산합니다.
이제 사후 예측 확률을 계산합니다. 확률 모델의 예측 확률을 계산하는 고전적인 방법은 다음과 같이 Monte Carlo 샘플링을 사용하는 것입니다.
여기서 은 샘플 크기이고 는 SNGP 사후 (sngp_logits, sngp_covmat)의 무작위 샘플입니다. 그러나 이 접근 방식은 자율 주행 또는 실시간 입찰과 같이 대기 시간에 민감한 애플리케이션의 경우 속도가 느릴 수 있습니다. 대신 평균 필드 방법{.external}을 사용하여 를 근사시킬 수 있습니다.
where is the SNGP variance, and is often chosen as or .
참고: 를 고정 값으로 고정하는 대신 하이퍼파라미터로 취급하고 이를 조정하여 모델의 보정 성능을 최적화할 수도 있습니다. 이는 딥 러닝 불확실성 자료에서 온도 스케일링{.external}이라고 알려져 있습니다.
이 평균 필드 메서드는 내장 함수 layers.gaussian_process.mean_field_logits로 구현됩니다.
SNGP 요약
이제 모든 부분을 합칠 수 있습니다. 훈련, 평가 및 불확실성 계산의 전체 절차를 단 5줄로 수행할 수 있습니다.
SNGP 모델의 클래스 확률(왼쪽)과 예측 불확실성(오른쪽)을 시각화합니다.
클래스 확률 플롯(왼쪽)에서 노란색과 자주색이 클래스 확률임을 상기하십시오. 훈련 데이터 영역에 가까울 때 SNGP는 높은 신뢰도로 예제를 올바르게 분류합니다(즉, 거의 0 또는 1의 확률 할당). 훈련 데이터에서 멀어지면 SNGP는 점차 신뢰가 떨어지고 예측 확률은 0.5에 가까워지는 반면 (정규화된) 모델 불확실성은 1로 상승합니다.
이것을 결정성 모델의 불확실성 표면과 비교합니다.
앞에서 언급했듯이 결정성 모델은 거리를 인식하지 않습니다. 불확실성은 결정 경계에서 테스트 예제의 거리로 정의됩니다. 이로 인해 모델은 도메인 외 예제(빨간색)에 대해 과도하게 확신하는 예측을 생성합니다.
다른 불확실성 접근 방식과의 비교
이 섹션에서는 SNGP의 불확실성을 Monte Carlo 드롭아웃{.external} 및 딥 앙상블{.external}과 비교합니다.
이 두 가지 방법은 모두 결정성 모델의 다중 순방향 통과에 대한 Monte Carlo 평균화를 기반으로 합니다. 먼저 앙상블 크기 을 설정합니다.
Monte Carlo 드롭아웃
드롭아웃 레이어가 있는 훈련된 신경망이 주어지면 Monte Carlo 드롭아웃은 평균 예측 확률을 계산합니다.
by averaging over multiple Dropout-enabled forward passes .
딮 앙상블
딥 앙상블은 딥 러닝 불확실성을 위한 첨단(그러나 비용이 많이 드는) 방식입니다. 딥 앙상블을 훈련하려면 먼저 앙상블 구성원을 훈련합니다.
로짓을 수집하고 평균 예측 확률 를 계산합니다.
Monte Carlo 드롭아웃 및 딥 앙상블 방법은 모두 결정 경계를 덜 확실하게 만들어 모델의 불확실성 능력을 향상시킵니다. 그러나 둘 모두 거리 인식이 부족한 결정성 딥 네트워크의 한계를 물려받습니다.
요약
이 튜토리얼에서는 다음을 수행했습니다.
거리 인식을 개선하기 위해 딥 분류기에 SNGP 모델을 구현했습니다.
Keras
Model.fitAPI를 사용하여 SNGP 모델을 전체적으로 훈련했습니다.SNGP의 불확실성 동작을 시각화했습니다.
SNGP, Monte Carlo 드롭아웃 및 딥 앙상블 모델 간의 불확실성 동작을 비교했습니다.
리소스 및 추가 자료
불확실성 인식 자연어 이해를 위해 BERT 모델에 SNGP를 적용하는 예는 SNGP-BERT 튜토리얼을 확인하세요.
다양한 벤치마크 데이터세트(예: CIFAR, ImageNet, Jigsaw 독성 감지 등)에서 SNGP 모델(및 기타 여러 불확실성 방법)을 구현하려면 Uncertainty Baselines GitHub 리포지토리{.external}로 이동하세요.
SNGP 방법을 더 깊이 있게 이해하려면 Simple and Principled Uncertainty Estimation with Deterministic Deep Learning via Distance Awareness{.external} 제목의 논문을 확인하세요.