
Path: blob/master/site/ko/tutorials/video/video_classification.ipynb
38497 views
Copyright 2022 The TensorFlow Authors.
 GitHub에서 소스 보기
GitHub에서 소스 보기3D 컨볼루셔널 신경망을 사용한 비디오 분류
This tutorial demonstrates training a 3D convolutional neural network (CNN) for video classification using the UCF101 action recognition dataset. A 3D CNN uses a three-dimensional filter to perform convolutions. The kernel is able to slide in three directions, whereas in a 2D CNN it can slide in two dimensions. The model is based on the work published in A Closer Look at Spatiotemporal Convolutions for Action Recognition by D. Tran et al. (2017). In this tutorial, you will:
입력 파이프라인을 구축합니다.
Keras 함수형 API를 사용하여 잔차 연결이 있는 3D 컨볼루셔널 신경망 모델을 구축합니다.
모델 학습
모델을 평가 및 테스트합니다.
This video classification tutorial is the second part in a series of TensorFlow video tutorials. Here are the other three tutorials:
Load video data: This tutorial explains much of the code used in this document.
MoViNet for streaming action recognition: Get familiar with the MoViNet models that are available on TF Hub.
Transfer learning for video classification with MoViNet: This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.
설정
먼저 ZIP 파일의 내용을 검사하기 위한 remotezip, 진행률 표시줄을 사용하기 위한 tqdm, 비디오 파일을 처리하기 위한 OpenCV, 더 복잡한 텐서 작업을 수행하기 위한 einops, Jupyter 노트북에 데이터를 내장하기 위한 tensorflow_docs 등 일부 필요한 라이브러리를 설치하고 가져옵니다.
Note: Use TensorFlow 2.10 to run this tutorial. Versions above TensorFlow 2.10 may not run successfully.
비디오 데이터 로드 및 전처리
아래 숨겨진 셀은 UCF-101 데이터세트에서 데이터 조각을 다운로드하고 tf.data.Dataset에 로드하는 헬퍼 함수를 정의합니다. 이 코드를 자세히 안내하는 비디오 데이터 로드 튜토리얼에서 특정 전처리 단계에 대해 자세히 알아볼 수 있습니다.
숨겨진 블록 끝에 있는 FrameGenerator 클래스는 여기에서 가장 중요한 유틸리티로, TensorFlow 데이터 파이프라인에 데이터를 공급할 수 있는 반복 가능한 객체를 생성합니다. 특히 이 클래스에는 인코딩된 레이블과 함께 비디오 프레임을 로드하는 Python 생성기가 포함되어 있습니다. 생성기(__call__) 함수는 frames_from_video_file에 의해 생성된 프레임 배열과 프레임 세트와 관련된 레이블의 원-핫 인코딩 벡터를 생성합니다.
훈련, 검증 및 테스트 세트(train_ds, val_ds 및 test_ds)를 만듭니다.
모델 만들기
다음 3D 컨볼루셔널 신경망 모델은 D. Tran 등(2017)의 A Closer Look at Spatiotemporal Convolutions for Action Recognition 논문을 기반으로 합니다. 이 논문은 여러 버전의 3D ResNet을 비교합니다. 표준 ResNet과 같이 치수 (height, width)를 갖는 단일 이미지에서 작동하는 대신 비디오 볼륨 (time, height, width)에서 작동합니다. 이 문제에 대한 가장 확실한 접근 방식은 각 2D 컨볼루션(layers.Conv2D)을 3D 컨볼루션(layers.Conv3D)으로 바꾸는 것입니다.
이 튜토리얼은 잔차 연결이 있는 (2 + 1)D 컨볼루션을 사용합니다. (2 + 1)D 컨볼루션은 공간 및 시간 차원의 분해를 허용하므로 두 개의 개별 단계를 생성합니다. 이 접근 방식의 장점은 컨볼루션을 공간 및 시간 차원으로 분해하면 매개변수가 저장된다는 것입니다.
각 출력 위치에 대해 3D 컨볼루션은 볼륨의 3D 패치에서 모든 벡터를 결합하여 출력 볼륨에 하나의 벡터를 생성합니다.
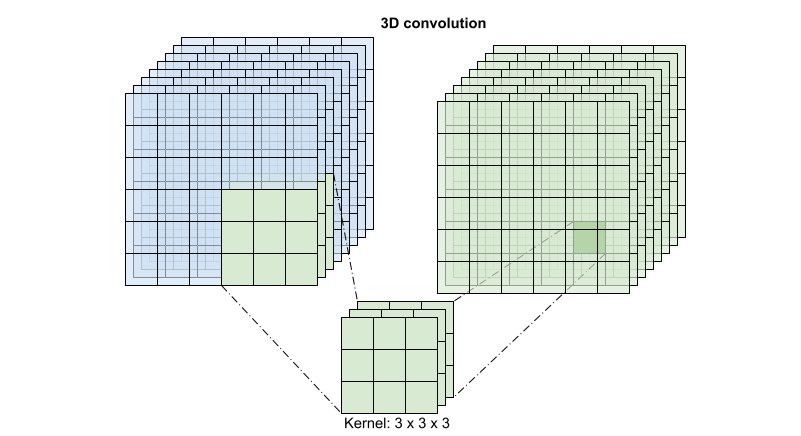
이 작업은 time * height * width * channels를 입력 받고 channels 출력을 생성합니다(입력 및 출력 채널의 수가 같다고 가정합니다. 따라서 커널 크기가 (3 x 3 x 3)인 3D 컨볼루션 레이어에는 27 * channels ** 2개 항목을 가진 가중치-행렬이 필요합니다). 참조 논문에서는 컨볼루션을 분해하는 것이 보다 효과적이고 효율적인 접근 방식임을 발견했습니다. 시간 및 공간 차원을 처리하기 위한 단일 3D 컨볼루션 대신 그들은 공간과 시간 차원을 별도로 처리하는 "(2+1 )D" 컨볼루션을 제안했습니다. 아래 그림은 (2 + 1)D 컨볼루션의 분해된 공간 및 시간 컨볼루션을 보여줍니다.
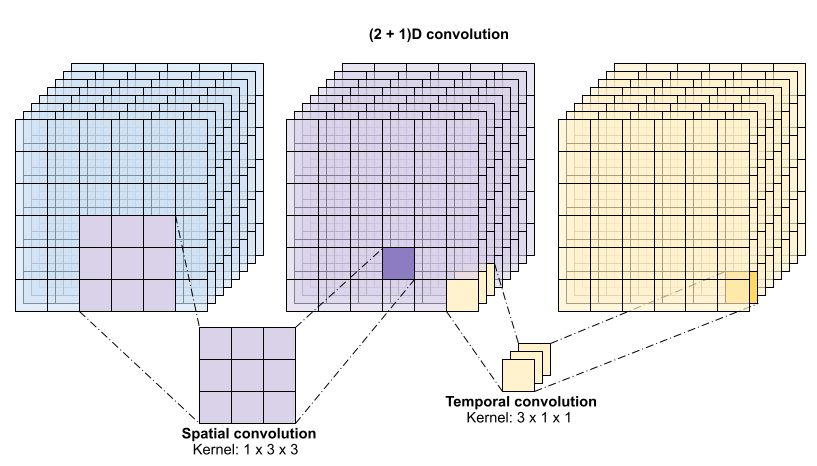
이 접근 방식의 주된 이점은 매개변수의 수를 줄이는 것입니다. (2 + 1)D 컨볼루션에서 공간 컨볼루션은 (1, width, height) 형상의 데이터를 받는 반면 시간 컨볼루션은 (time, 1, 1) 형상의 데이터를 받습니다. 예를 들어, 커널 크기가 (3 x 3 x 3)인 (2 + 1)D 컨볼루션에는 (9 * channels**2) + (3 * channels**2) 크기의 가중치 행렬이 필요합니다. 이는 많아야 전체 3D 컨볼루션의 절반 미만입니다. 이 튜토리얼에서는 resnet의 각 컨볼루션이 (2+1)D 컨볼루션으로 대체되는 (2 + 1)D ResNet18을 구현합니다.
ResNet 모델은 잔차 블록 시퀀스로부터 만들어집니다. 잔차 블록에는 두 개의 분기가 있습니다. 주 분기는 계산을 수행하지만 그래디언트가 흐르기 어렵습니다. 전차 분기는 기본 계산을 우회하고 대부분 주 분기의 출력에 입력을 추가합니다. 그래디언트는 이 분기를 통해 쉽게 흐릅니다. 따라서 손실 함수에서 잔차 블록의 주 분기로 쉽게 이동할 수 있습니다. 그러면 그래디언트 소실 문제를 피할 수 있습니다.
다음 클래스를 사용하여 잔차 블록의 주 분기를 만듭니다. 표준 ResNet 구조와 달리 이는 layers.Conv2D 대신 사용자 정의 Conv2Plus1D 레이어를 사용합니다.
잔차 분기를 주 분기에 추가하려면 크기가 같아야 합니다. 아래의 Project 레이어는 분기에서 채널 수가 변경되는 경우를 다룹니다. 특히, 밀집 연결된 레이어에 정규화가 뒤따르는 시퀀스가 추가됩니다.
add_residual_block을 사용하여 모델 레이어 간에 건너뛰기 연결을 도입합니다.
데이터의 다운샘플링을 수행하려면 비디오 크기를 조정해야 합니다. 특히, 비디오 프레임을 다운샘플링하면 모델이 프레임의 특정 부분을 검사하여 특정 동작에 해당하는 패턴을 감지할 수 있습니다. 다운샘플링을 통해 중요하지 않은 정보를 버릴 수 있습니다. 또한 비디오 크기를 조정하면 차원 축소가 가능하므로 모델을 통한 처리 속도가 빨라집니다.
Keras 함수형 API를 사용하여 잔차 네트워크를 구축합니다.
모델 훈련
이 튜토리얼에서는 tf.keras.optimizers.Adam 옵티마이저와 tf.keras.losses.SparseCategoricalCrossentropy 손실 함수를 선택합니다. 모든 단계에서 모델 성능의 정확도를 보려면 metrics 인수를 사용합니다.
Model.fit 메서드로 50 epoch 동안 모델을 훈련시킵니다.
참고: 이 예제 모델은 이 튜토리얼의 교육 시간을 합리적으로 유지하기 위해 더 적은 데이터 포인트(300개의 훈련 및 100개의 검증 예제)에 대해 훈련되었습니다. 또한 이 예제 모델은 훈련하는 데 1시간 이상 걸릴 수 있습니다.
결과 시각화
훈련 및 검증 세트에 대한 손실 및 정확도 플롯을 생성합니다.
모델 평가하기
Keras Model.evaluate를 사용하여 테스트 데이터세트의 손실 및 정확도를 가져옵니다.
참고: 이 튜토리얼의 예제 모델은 훈련 시간을 합리적으로 유지하기 위해 UCF101 데이터세트의 일부만 사용합니다. 추가 하이퍼파라미터 조정이나 더 많은 훈련 데이터로 정확도와 손실을 개선할 수 있습니다.
모델 성능을 더 시각화하려면 혼동 행렬을 사용합니다. 혼동 행렬을 사용하면 정확도를 넘어 분류 모델의 성능을 평가할 수 있습니다. 이 다중 클래스 분류 문제에 대한 혼동 행렬을 작성하기 위해 테스트 세트의 실제 값과 예측 값을 가져옵니다.
각 클래스의 정밀도와 호출 값은 혼동 행렬을 사용하여 계산할 수도 있습니다.
다음 단계
TensorFlow에서 비디오 데이터 작업에 대해 자세히 알아보려면 다음 튜토리얼을 확인하세요.