
Path: blob/master/site/pt-br/guide/dtensor_overview.ipynb
38637 views
Copyright 2019 The TensorFlow Authors.
Conceitos do DTensor
 Ver fonte no GitHub
Ver fonte no GitHubVisão geral
Este Colab apresenta o DTensor, uma extensão do TensorFlow para fazer computação distribuída síncrona.
O DTensor oferece um modelo global de programação que permite aos desenvolvedores criar aplicações que operem nos Tensores globalmente, gerenciando também a distribuição entre os dispositivos internamente. O DTensor distribui o programa e os tensores de acordo com as diretivas de fragmentação por meio de um procedimento chamado expansão Programa único, vários dados (SPMD, na sigla em inglês).
Ao desacoplar a aplicação das diretivas de fragmentação, o DTensor permite a execução da mesma aplicação em um único dispositivo, vários dispositivos ou até mesmo vários clientes, sem deixar de preservar sua semântica global.
Este guia apresenta conceitos do DTensor para fazer computação distribuída e como o DTensor se integra ao TensowFlow. Para ver uma demonstração do uso do DTensor em treinamento de modelos, confira o tutorial Treinamento distribuído com o DTensor.
Configuração
O DTensor faz parte da versão 2.9.0 do TensorFlow e também está incluído nas compilações noturnas desde 09/04/2022.
Após a instalação, importe tensorflow e tf.experimental.dtensor. Depois, configure o TensorFlow para usar 6 CPUs virtuais.
Embora este exemplo use vCPUs, o DTensor funciona da mesma forma em dispositivos com CPU, GPU ou TPU.
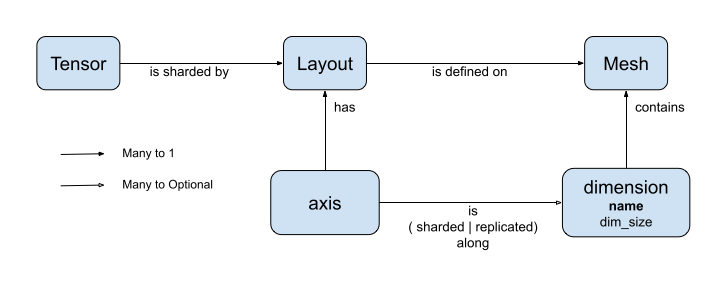
Modelo do DTensor para tensores distribuídos
O DTensor apresenta dois conceitos: dtensor.Mesh e dtensor.Layout, que são abstrações para modelar a fragmentação de tensores em dispositivos com relação topológica.
Meshdefine a lista de dispositivos para computação.Layoutdefine como fragmentar a dimensão do Tensor em umaMesh(malha).
Mesh
Mesh representa uma topologia cartesiana de um conjunto de dispositivos. Cada dimensão do grid cartesiano é chamada de dimensão de malha e referenciada com um nome. Os nomes da dimensão de malha dentro da mesma Mesh precisam ser únicos.
Os nomes das dimensões de malha são referenciados por Layout para descrever o comportamento de fragmentação de um tf.Tensor em cada um de seus eixos. Confira mais detalhes adiante na seção sobre Layout.
Mesh pode ser visto como uma matriz de dispositivos multidimensional.
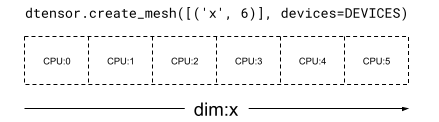
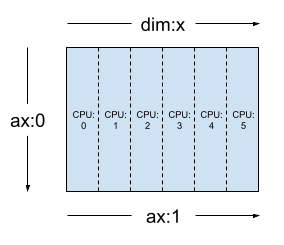
Em uma Mesh unidimensional, todos os dispositivos formam uma lista em uma única dimensão de malha. O exemplo abaixo usa dtensor.create_mesh para criar uma malha de 6 dispositivos com CPU em uma dimensão de malha 'x' com tamanho igual a 6 dispositivos:
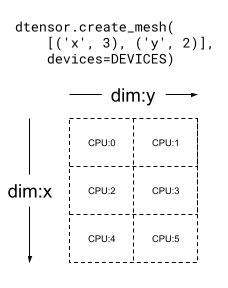
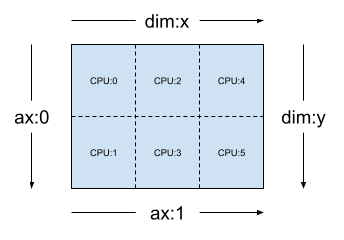
Uma Mesh também pode ser multidimensional. No exemplo abaixo, 6 dispositivos com CPU formam uma malha 3x2, em que a dimensão de malha 'x' tem um tamanho igual a 3 dispositivos, e a dimensão de malha 'y' tem um tamanho igual a 2 dispositivos:
Layout
Layout especifica como um tensor é distribuído ou fragmentando em uma Mesh.
Observação: para evitar confusões entre Mesh e Layout, o termo dimensão é sempre associado a Mesh, e o termo eixo é associado a Tensor e Layout neste guia.
O posto de Layout sempre deve ser igual ao posto do Tensor no qual o Layout é aplicado. Para cada um dos eixos do Tensor, o Layout pode especificar uma dimensão de malha para fragmentar o tensor ou pode especificar o eixo como "não fragmentado". O tensor é replicado em toda dimensão de malha na qual não é fragmentado.
O posto de um Layout e o número de dimensões de umaMesh não precisam ser iguais. Os eixos unsharded (não fragmentados) de um Layout não precisam estar associados a uma dimensão de malha, e dimensões da malha unsharded não precisam estar associadas a um eixo do layout.
Vamos analisar alguns exemplos de Layout para as Meshs criadas na seção anterior.
Em uma malha unidimensional, como [("x", 6)] (mesh_1d na seção anterior), Layout(["unsharded", "unsharded"], mesh_1d) é um layout de um tensor de posto 2 replicado em 6 dispositivos. 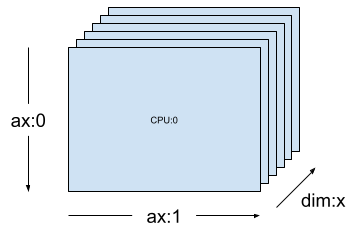
Usando o mesmo tensor e a mesma mesh, o layout Layout(['unsharded', 'x']) deve fragmentar o segundo eixo do tensor em 6 dispositivos.
Dada uma malha bidimensional 3x2, como [("x", 3), ("y", 2)], (mesh_2d da seção anterior), Layout(["y", "x"], mesh_2d) é um layout para um Tensor de posto 2 cujo primeiro eixo é fragmentado na dimensão de malha "y" e cujo segundo eixo é fragmentado na dimensão de malha "x".
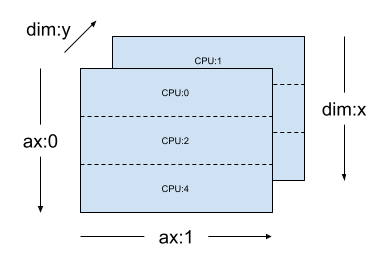
Para a mesma mesh_2d, o layout Layout(["x", dtensor.UNSHARDED], mesh_2d) é um layout de um Tensor com posto 2 que é replicado em "y" e cujo primeiro eixo é fragmentado na dimensão de malha x.
Aplicações com um cliente ou vários clientes
O DTensor oferece suporte a aplicações com um cliente e com vários clientes. O kernel do Python do Colab é um exemplo de uma aplicação DTensor com um cliente, em que há um único processo do Python.
Em uma aplicação DTensor com vários clientes, diversos processos do Python funcionam coletivamente como uma aplicação coesa. O grid cartesiano de uma Meshem uma aplicação DTensor com vários clientes pode abarcar diversos dispositivos, independentemente se estiverem anexados localmente ao cliente atual ou anexados remotamente a outro cliente. O conjunto de todos os dispositivos usados por uma Mesh é chamado de lista global de dispositivos.
A criação de uma Mesh em uma aplicação DTensor com vários clientes é uma operação coletiva, em que a lista global de dispositivos é idêntica para todos os clientes participantes, e a criação da Mesh serve como uma barreira global.
Durante a criação da Mesh, cada cliente fornece sua lista local de dispositivos juntamente com a lista global de dispositivos esperada. O DTensor faz uma validação para verificar se as duas listas estão consistentes. Confira a documentação da API de dtensor.create_mesh e de dtensor.create_distributed_mesh para ver mais informações sobre a criação de uma malha com vários clientes e a lista global de dispositivos.
O caso com um cliente pode ser visto como um caso especial de vários clientes, com apenas 1 cliente. Em uma aplicação com um cliente, a lista global de dispositivos é idêntica à lista local de dispositivos.
DTensor usado como tensor fragmentado
Agora, vamos começar a programar com o DTensor. A função helper dtensor_from_array demonstra a criação de DTensors a partir de algo parecido com um tf.Tensor. A função realiza dois passos:
Replica o tensor em cada dispositivo da malha.
Fragmenta a cópia de acordo com o layout solicitado em seus argumentos.
Anatomia de um DTensor
O DTensor é um objeto tf.Tensor, mas ampliado com a anotação Layout que define seu comportamento de fragmentação. Um DTensor é composto por:
Metadados globais do tensor, incluindo o formato global e o tipo de dados (dtype) do tensor.
Um
Layout, que define aMeshà qual oTensorpertence, além de como oTensoré fragmentado naMesh.Uma lista de tensores componentes, um item por dispositivo local na
Mesh.
Usando dtensor_from_array, você pode criar seu primeiro DTensor, my_first_dtensor, e avaliar o conteúdo.
Layout e fetch_layout
O layout de um DTensor não é um atributo comum de tf.Tensor. Em vez disso, o DTensor conta com uma função, dtensor.fetch_layout, para acessar o layout de um DTensor.
Tensores componentes, pack e unpack
O DTensor é composto por uma lista de tensores componentes. O tensor componente de um dispositivo na Mesh é o objeto Tensor que representa a parte do DTensor global armazenada neste dispositivo.
Um DTensor pode ser dividido em tensores componentes usando dtensor.unpack. Você pode usar dtensor.unpack para avaliar os componentes do DTensor e confirmar se eles estão em todos os dispositivos da Mesh.
Observe que as posições dos tensores componentes na visão global podem se sobrepor. Por exemplo, no caso de um layout totalmente replicado, todos os componentes são réplicas idênticas do tensor global.
Conforme mostrado, my_first_dtensor é um tensor de [0, 1] replicado em todos os 6 dispositivos.
A operação inversa de dtensor.unpack é dtensor.pack. Os tensores componentes podem ser empacotados de volta em um DTensor.
Os componentes precisam ter o mesmo posto e tipo de dados (dtype), que serão o posto e dtype do DTensor retornado. Entretanto, não há um requisito estrito para o posicionamento de dispositivos dos tensores componentes como entrada de dtensor.unpack: a função copiará automaticamente os tensores componentes para os dispositivos correspondentes.
Fragmentação de um DTensor em uma malha
Até o momento, você trabalhou com o my_first_dtensor, um DTensor de posto 1 totalmente replicado em uma Mesh unidimensional.
Agora, crie e avalie DTensors que sejam fragmentados em uma Mesh bidimensional. O próximo exemplo faz isso com uma Mesh 3x2 em 6 dispositivos com CPU, em que o tamanho da dimensão de malha 'x' é 3 dispositivos, e o tamanho da dimensão de malha 'y' é 2 dispositivos.
Tensor de posto 2 totalmente fragmentado em uma malha bidimensional
Crie um DTensor 3x2 de posto 2, fragmentando seu primeiro eixo na dimensão de malha 'x' e seu segundo eixo na dimensão de malha 'y'.
Como o formato do tensor é igual à dimensão de malha em todos os eixos fragmentados, cada dispositivo recebe um único elemento do DTensor.
O posto do tensor componente é sempre o mesmo que o posto do formato global. O DTensor adota essa convenção como uma forma simplificada de preservar as informações para identificar a relação entre um tensor componente e o DTensor global.
Tensor de posto 2 totalmente replicado em uma malha bidimensional
Para fins comparativos, crie um DTensor 3x2 de posto 2 totalmente replicado na mesma malha bidimensional.
Como o DTensor é totalmente replicado, cada dispositivo recebe uma réplica completa do DTensor 3x2.
O posto dos tensores componentes é o mesmo que o posto do formato global. Esse fato é trivial, pois, neste caso, o formato dos tensores componentes é igual ao formato global, de toda forma.
Tensor de posto 2 híbrido em uma malha bidimensional
E quanto a um caso que não seja nem totalmente fragmentado nem totalmente replicado?
O DTensor permite que um Layout seja híbrido, fragmentado em alguns eixos, mas replicado em outros.
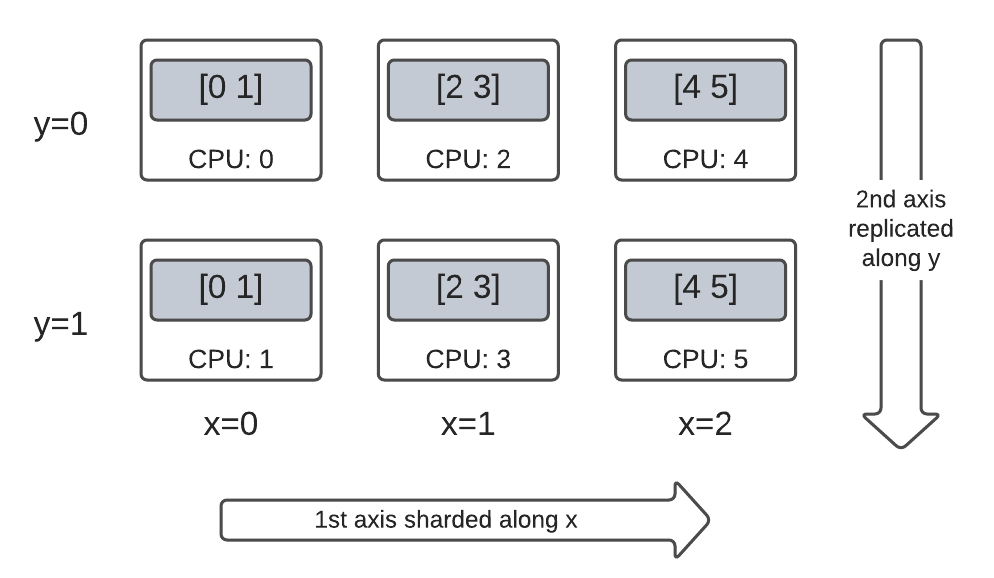
Por exemplo, você pode fragmentar o mesmo DTensor 3x2 de posto 2 da seguinte forma:
O primeiro eixo é fragmentado na dimensão de malha
'x'.O segundo eixo é replicado na dimensão de malha
'y'.
Para fazer esse esquema de fragmentação, você precisa apenas mudar a configuração de fragmentação do segundo eixo de 'y' para dtensor.UNSHARDED a fim de indicar sua intenção de replicar no segundo eixo. O objeto layout ficará assim: Layout(['x', dtensor.UNSHARDED], mesh).
Você pode avaliar os tensores componentes do DTensor criado e verificar se estão fragmentados de acordo com seu esquema. Pode ajudar ilustrar a situação com um gráfico:
Tensor.numpy() e DTensor fragmentado
É importante saber que fazer uma chamada ao método .numpy() em um DTensor aciona um erro. O motivo para isso é proteger contra coleta indesejada de dados em diversos dispositivos computacionais para o dispositivo host com CPU que dá suporte ao retorno da array numpy.
API do TensorFlow no DTensor
O DTensor tem o objetivo de ser uma substituição rápida, sem necessidade de fazer alterações, para o tensor em seu programa. A API do Python do TensorFlow que consome tf.Tensor, com as funções da biblioteca de operações Ops, tf.function, tf.GradientTape, também funciona com o DTensor.
Para conseguir isso, para cada Grafo do TensorFlow, o DTensor gera e executa um grafo SPMD equivalente em um procedimento chamado expansão SPMD. Veja alguns passos essenciais da expansão SPMD do DTensor:
Propagar o
Layoutde fragmentação do DTensor no grafo do TensorFlow.Reescrever as Ops do TensorFlow no DTensor global com Ops do TensorFlow nos tensores componentes, inserindo Ops coletivas e de comunicação quando necessário.
Reduzir as Ops do TensorFlow neutras de backend para Ops do TensorFlow específicas de backend.
O resultado final é que o DTensor é uma substituição rápida, sem necessidade de fazer alterações, para o Tensor.
Observação: o DTensor ainda é uma API experimental e, portanto, você fará experimentos e desafiará os limites de seu modelo de programação.
Existem duas maneiras de acionar a execução do DTensor:
O DTensor como operandos de uma função do Python, por exemplo,
tf.matmul(a, b)passará pelo DTensor sea,bou ambos forem DTensors.Solicitando que o resultado de uma função do Python seja um DTensor, por exemplo,
dtensor.call_with_layout(tf.ones, layout, shape=(3, 2))passará pelo DTensor, pois solicitamos que a saída de tf.ones seja fragmentada de acordo com umlayout.
DTensor como operandos
Diversas funções da API do TensorFlow recebem tf.Tensor como operandos e retornam tf.Tensor como resultados. Para essas funções, você pode expressar a intenção de executar uma função pelo DTensor passando o DTensor como operandos. Esta seção usa tf.matmul(a, b) para exemplificar.
Entrada e saída totalmente replicadas
Neste caso, os DTensors são totalmente replicados. Em cada um dos dispositivos da Mesh,
o tensor componente do operando
aé[[1, 2, 3], [4, 5, 6]](2x3)o tensor componente do operando
bé[[6, 5], [4, 3], [2, 1]](3x2)a computação consiste de um único
MatMulde(2x3, 3x2) -> 2x2,o tensor componente do resultado
cé[[20, 14], [56,41]](2x2)
O número total de operações mul de ponto flutuante é: 6 device * 4 result * 3 mul = 72 (6 dispositivos * 4 resultados * 3 muls = 72).
Fragmentação de operandos no eixo contraído
É possível reduzir a quantidade de computações por dispositivo fragmentando os operandos a e b. Um esquema de fragmentação muito usado para tf.matmul é fragmentar os operandos no eixo da contração, ou seja, fragmentar a no segundo eixo e b no primeiro eixo.
O produto global de matrizes fragmentadas por esse esquema pode ser realizado de forma eficiente por matmuls locais executados simultaneamente, seguidos por uma redução coletiva para agregar os resultados locais. Essa também é a forma canônica de implementar o produto escalar distribuído de matrizes.
O número total de operações mul de ponto flutuante é 6 devices * 4 result * 1 = 24, um fator de redução igual a 3 comparado ao caso totalmente replicado acima (72). O fator de 3 deve-se à fragmentação na dimensão de malha x com um tamanho igual a 3 dispositivos.
A redução do número de operações executadas sequencialmente é o principal mecanismo que o paralelismo de modelo síncrono usa para acelerar o treinamento.
Fragmentação adicional
Você pode fazer uma fragmentação adicional nas entradas, e elas são transportadas de forma adequada para os resultados. Por exemplo, você pode aplicar uma fragmentação adicional do operando a em seu primeiro eixo para a dimensão de malha 'y' . A fragmentação adicional poderá ser transportada para o primeiro eixo do resultado c.
O número total de operações mul de ponto flutuante é 6 devices * 2 result * 1 = 12, um fator de redução igual a 2 comparado ao caso acima (24). O fator de 2 deve-se à fragmentação na dimensão de malha y com um tamanho igual a 2 dispositivos.
DTensor como saída
E quanto às funções do Python que não recebem operandos, mas retornam como resultado um Tensor que pode ser fragmentado? Veja alguns exemplos dessas funções:
tf.ones,tf.zeros,tf.random.stateless_normal
Para essas funções do Python, o DTensor conta com dtensor.call_with_layout que faz uma execução adiantada (eager) do Python com o DTensor e garante que o Tensor retornado seja um DTensor com o Layout solicitado.
Geralmente, a função do Python executada de maneira adiantada (eager) contém somente uma única Op do TensorFlow não trivial.
Para usar uma função do Python que gere diversas Ops do TensorFlow com dtensor.call_with_layout, a função deverá ser convertiva em uma tf.function. Fazer uma chamada a tf.function é uma única Op do TensorFlow. Quando a função tf.function é chamada, o DTensor pode fazer a propagação do layout ao analisar o grafo computacional de tf.function, antes que qualquer tensor intermediário seja materializado.
APIs que geram uma única Op do TensorFlow
Se uma função gerar uma única Op do TensorFlow, você poderá aplicar dtensor.call_with_layout diretamente à função.
APIs que geram diversas Ops do TensorFlow
Se a API gerar diversas Ops do TensorFlow, converta a função em uma única Op usando tf.function. Por exemplo, tf.random.stateleess_normal
É permitido encapsular uma função do Python que gera uma única Op do TensorFlow com tf.function. A única ressalva é arcar com o custo e a complexidade associados ao criar uma tf.function a partir de uma função do Python.
De tf.Variable para dtensor.DVariable
No Tensorflow, tf.Variable é o armazenador de um valor Tensor mutável. No DTensor, a semântica variável correspondente é fornecida por dtensor.DVariable.
O motivo de um novo tipo DVariable ter sido lançado no DTensor é que as DVariables têm um requisito adicional: o layout não pode ter seu valor inicial alterado.
Exceto pelo requisito de não variar o layout, uma DVariable se comporta da mesma forma que uma tf.Variable. Por exemplo, você pode adicionar uma DVariable a um DTensor.
Além disso, você pode atribuir um DTensor a uma DVariable.
Se você tentar alterar o layout de uma DVariable por meio da atribuição de um DTensor com um layout incompatível, será gerado um erro.
Quais são os próximos passos?
Neste Colab, você aprendeu sobre o DTensor, uma extensão do TensorFlow para fazer computação distribuída. Para ver esses conceitos em um tutorial, confira Treinamento distribuído com o DTensor.