
Path: blob/master/site/pt-br/hub/tutorials/movinet.ipynb
39042 views
Copyright 2021 The TensorFlow Hub Authors.
Licensed under the Apache License, Version 2.0 (the "License");
MoViNet para o reconhecimento de ações de streaming
 Ver no GitHub
Ver no GitHubEste tutorial demonstra como usar um modelo de classificação de vídeos pré-treinado para classificar uma atividade (como dançar, nadar, pedalar, etc.) no vídeo fornecido.
A arquitetura do modelo usada neste tutorial é chamada de MoViNet (Mobile Video Networks – Redes de vídeo móveis). As MoViNets são uma família de modelos eficientes de classificação de vídeos treinados com um dataset enorme (Kinetics 600).
Diferentemente dos modelos I3D disponíveis no TF Hub, os modelos MoViNet também têm suporte a inferência quadro a quadro em streaming de vídeo.
Os modelos pré-treinados estão disponíveis no TF Hub. A coleção do TF Hub também inclui modelos quantizados otimizados para o TF Lite.
O código-fonte para esses modelos está disponível no TensorFlow Model Garden, que inclui uma versão mais longa deste tutorial que também aborda a criação e ajustes finos de um modelo MoViNet.
Este tutorial sobre o MoViNet é uma parte de uma série de tutoriais sobre vídeo do TensorFlow. Aqui estão os outros três tutoriais:
Carregue dados de vídeo: este tutorial explica como carregar e pré-processar dados de vídeo em um pipeline de dataset do TensorFlow do zero.
Crie um modelo CNN 3D para a classificação de vídeos: observe que este tutorial usa uma CNN (2+1)D que decompõe os aspectos espaciais e temporais dos dados 3D. Se você estiver usando dados volumétricos, como uma ressonância magnética, considere usar uma CNN 3D em vez de uma CNN (2+1)D.
Aprendizado por transferência para a classificação de vídeos com MoViNet: este tutorial explica como usar um modelo de classificação de vídeos pré-treinado com um dataset diferente, o UCF-101.
Configuração
Para inferência em modelos menores (A0-A2), é suficiente usar CPU para este Colab.
Baixe a lista de rótulos do Kinetics 600 e exiba via print os primeiros rótulos:
Para fornecer um vídeo simples de exemplo para classificação, podemos carregar um pequeno GIF de polichinelos.

Crédito: imagens compartilhadas pelo técnico Bobby Bluford no YouTube, com licença CC-BY.
Baixe o GIF.
Defina uma função para ler um GIF e colocar em um tf.Tensor:
O formato do vídeo é (frames, height, width, colors).
Como usar o modelo
Esta seção explica como usar os modelos do TensorFlow Hub. Se você quiser ver os modelos em ação, prossiga para a próxima seção.
Existem duas versões de cada modelo : base e streaming.
A versão
baserecebe um vídeo como entrada e retorna a média das probabilidades para os quadros.A versão
streamingrecebe um quadro do vídeo e um estado da RNN como entrada e retorna as previsões para esse quadro, além do novo estado da RNN.
Modelo de referência
Essa versão do modelo tem uma assinatura (signature) que recebe um argumento image, que é tf.float32, com formato (batch, frames, height, width, colors). Ela retorna um dicionário contendo uma saída: um tensor tf.float32 de logits com formato (batch, classes).
Para executar essa assinatura no vídeo, primeiro você precisa adicionar a dimensão externa de batch ao vídeo.
Defina uma função get_top_k que encapsule o processamento da saída acima para uso posterior.
Converta os logits em probabilidades e identifique as 5 principais classes para o vídeo. O modelo confirma que provavelmente o vídeo é de jumping jacks (polichinelos).
Modelo streaming
A seção anterior usou um modelo que é executado para um vídeo inteiro. Geralmente, ao processar um vídeo, você não deseja uma única previsão no final, mas sim atualizar as previsões quadro a quadro. As versões stream do modelo permitem fazer isso.
Carregue a versão stream do modelo.
Usar esse modelo é ligeiramente mais complexo do que o modelo base. Você precisa manter o controle do estado interno das RNNs do modelo.
A assinatura init_states recebe o formato (batch, frames, height, width, colors) do vídeo como entrada e retorna um grande dicionário de tensores contendo os estados iniciais das RNNs:
Depois que você tiver o estado inicial das RNNs, pode passar o estado e um quadro do vídeo como entrada (mantendo o formato (batch, frames, height, width, colors) para o quadro do vídeo). O modelo retorna um par (logits, state).
Após observar o primeiro quadro, o modelo não está convencido de que o vídeo é de polichinelos:
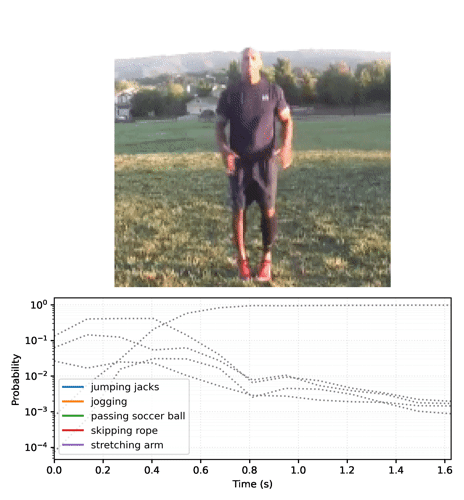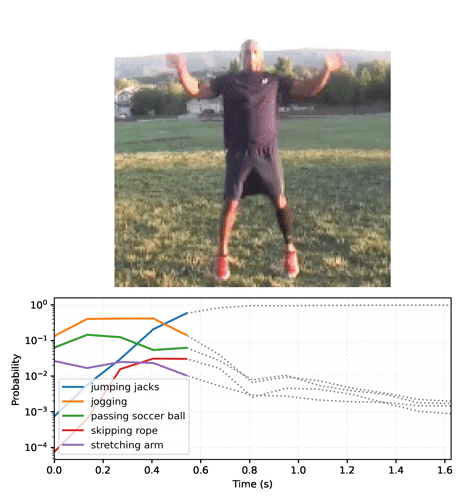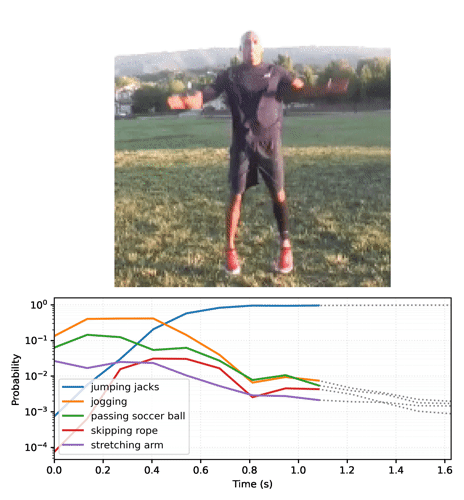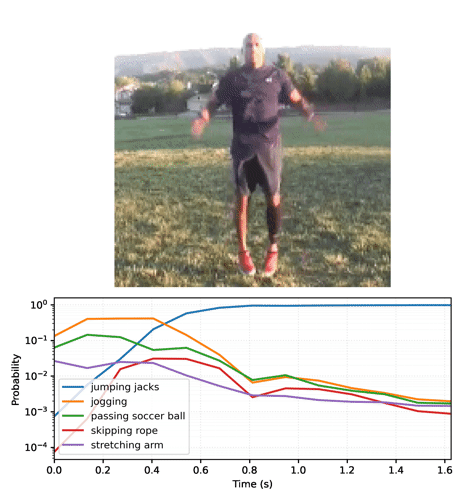
Se você executar o modelo em um loop, passando o estado atualizado a cada quadro, o modelo converge rapidamente para o resultado correto:
Talvez você perceba que a probabilidade final é muito mais alta do que na seção anterior, em que o modelo base foi executado. O modelo base retorna uma média das previsões para os quadros.
Anime as previsões ao longo do tempo
A seção anterior forneceu detalhes de como usar esses modelos. Esta seção se aprofunda para gerar algumas animações de inferência interessantes.
A célula oculta abaixo define funções helper usadas nesta seção.
Comece executando o modelo streaming para os quadros do vídeo e obtendo os logits:
Converta a sequência de probabilidades em um vídeo:
Recursos
Os modelos pré-treinados estão disponíveis no TF Hub. A coleção do TF Hub também inclui modelos quantizados otimizados para o TF Lite.
O código-fonte para esses modelos está disponível no TensorFlow Model Garden, que inclui uma versão mais longa deste tutorial que também aborda a criação e ajustes finos de um modelo MoViNet.
Próximos passos
Para saber mais sobre como trabalhar com dados de vídeo no TensorFlow, confira os tutoriais a seguir: