
Path: blob/master/site/pt-br/hub/tutorials/text_cookbook.md
38477 views
Tutoriais para domínio de texto
Esta página lista um conjunto de guias e ferramentas conhecidos para resolver problemas no domínio de texto com o TensorFlow Hub. É um ponto de partida para qualquer pessoa que deseja resolver problemas típicos de aprendizado de máquina usando componentes pré-treinados em vez de começar do zero.
Classificação
Quando desejamos prever a classe de um exemplo fornecido, como sentimento, toxicidade, categoria de artigo ou qualquer outra característica.

Os tutoriais abaixo resolvem a mesma tarefa sob diferentes perspectivas e usando ferramentas diferentes.
Keras
Classificação de texto com o Keras – exemplo para criar um classificador de sentimentos do IMDB com o Keras e o TensorFlow Datasets.
Estimator
Classificação de texto – exemplo para criar um classificador de sentimentos do IMDB com o Estimator (estimador). Contém várias dicas para melhorias e uma seção de comparação de módulos.
BERT
Previsão de sentimento em classificações de filmes com BERT no TF Hub – mostra como usar um módulo BERT para classificação. Inclui o uso da biblioteca bert para tokenização e pré-processamento.
Kaggle
Classificação do IMDB no Kaggle – mostra como interagir facilmente com uma competição do Kaggle em um Colab, incluindo como baixar os dados e enviar os resultados.
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------- | ----------- Classificação de texto | ![]() | | | | | Classificação de texto com o Keras | |
| | | | | Classificação de texto com o Keras | | ![]() |
| ![]() |
| ![]() | | Previsão de sentimento em classificações de filmes com BERT no TF Hub |
| | Previsão de sentimento em classificações de filmes com BERT no TF Hub | ![]() | | | |
| | | | ![]() | Classificação do IMDB no Kaggle |
| Classificação do IMDB no Kaggle | ![]() | | | | |
| | | | | ![]()
Tarefa em bengali com embeddings FastText
No momento, o TensorFlow Hub não oferece um módulo em cada idioma. O tutorial abaixo mostra como usar o TensorFlow Hub para experimentação rápida e desenvolvimento modular de aprendizado de máquina.
Classificador de artigos em bengali – demonstra como criar um embedding de texto do TensorFlow Hub reutilizável e usá-lo para treinar um classificador do Keras para o dataset Artigos em bengali BARD.
Similaridade semântica
Quando queremos descobrir quais frases estão correlacionadas uma com a outra em uma configuração zero-shot (sem exemplos de treinamento).
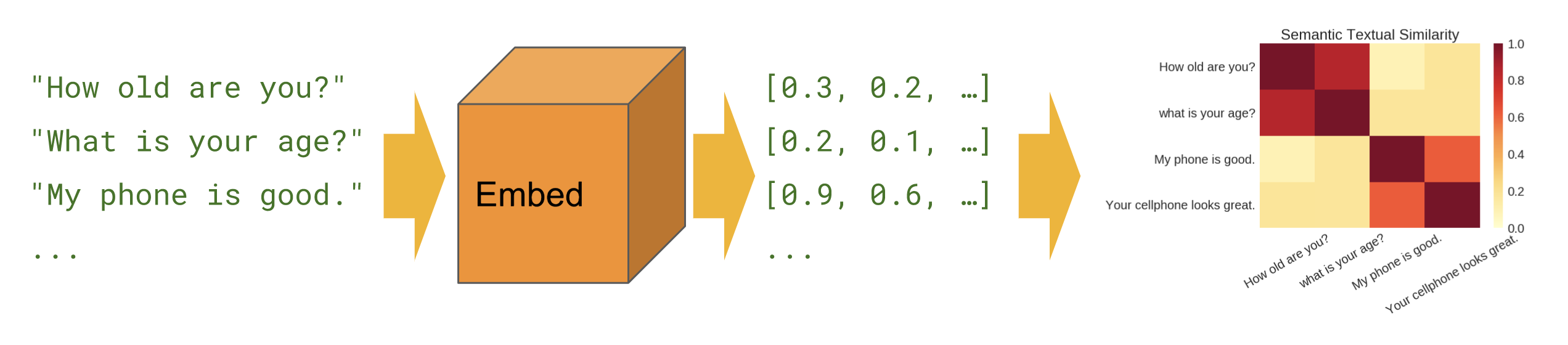
Básico
Similaridade semântica – mostra como usar o módulo de encoder de frases para computar a similaridade semântica.
Interlíngua
Similaridade semântica interlíngua – mostra como usar um dos encoders de frases interlínguas para computar a similaridade semântica entre idiomas.
Busca semântica
Busca semântica – mostra como usar o encoder de frases de perguntas e respostas para indexar um conjunto de documentos para busca com base na similaridade semântica.
Entrada SentencePiece
Similaridade semântica com o encoder lite universal – mostra como usar os módulos de encoder de frases que aceitam IDs de SentencePiece como entrada em vez de texto.
Criação de módulos
Em vez de usar somente módulos em tfhub.dev, existem formas de criar seus próprios módulos, o que pode ser útil para uma melhor modularidade do código-base de aprendizado de máquina e para futuro compartilhamento.
Encapsulamento de embeddings pré-treinados existentes
Exportador de módulos de embedding de texto – ferramenta para encapsular um embedding pré-treinado existente em um módulo. Mostra como incluir operações de pré-processamento de texto no módulo. Isso permite criar um módulo de embedding de frases a partir de embeddings de tokens.
Exportador de módulos de embedding de texto v2 – igual ao acima, mas compatível com o TensorFlow 2 e execução eager.