
Path: blob/master/site/pt-br/tutorials/customization/custom_training_walkthrough.ipynb
38561 views
Copyright 2018 The TensorFlow Authors.
Treinamento personalizado: tutorial
 Ver fonte no GitHub
Ver fonte no GitHubEste tutorial mostra como treinar um modelo de aprendizado de máquina com um loop de treinamento personalizado para categorizar pinguins por espécie. Neste notebook, você usará o TensorFlow para realizar o seguinte:
Importar um dataset
Criar um modelo linear simples
Treinar o modelo
Avaliar a eficácia do modelo
Usar o modelo treinado para fazer previsões
Programação do TensorFlow
Este tutorial demonstra as seguintes tarefas de programação do TensorFlow:
Importar dados com a API TensorFlow Datasets
Criar modelos e camadas com a API Keras
Problema de classificação de pinguins
Imagine que você é um ornitólogo em busca de uma maneira automatizada de categorizar todos os pinguins que encontra. O aprendizado de máquina oferece vários algoritmos para classificar pinguins estatisticamente. Por exemplo, um programa de aprendizado de máquina sofisticado pode classificar pinguins com base em fotografias. O modelo que você criará neste tutorial é um pouco mais simples. Ele classifica pinguins com base no peso, no comprimento das nadadeiras e nos bicos, especialmente nas medidas de comprimento e largura do cúlmen.
Há 18 espécies de pinguins, mas, neste tutorial, você só tentará classificar estas três:
Pinguins-de-barbicha
Pinguins-gentoo
Pinguins-de-adélia
 |
| Figura 1. Pinguins-de-barbicha, pinguins-gentoo e pinguins-de-adélia (obra de arte de @allison_horst, CC BY-SA 2.0). |
Felizmente, uma equipe de pesquisa já criou e compartilhou um dataset de 334 pinguins, com peso, comprimento das nadadeiras, medidas dos bicos e outros dados. Esse dataset também está convenientemente disponível como o TensorFlow Dataset penguins.
Configuração
Instale o pacote tfds-nightly para o dataset dos pinguins. O pacote tfds-nightly é a versão noturna do TensorFlow Datasets (TFDS). Para mais informações sobre o TFDS, confira a Visão geral do TensorFlow Datasets.
Depois, selecione Runtime > Restart Runtime no menu do Colab para reiniciar o runtime.
Não prossiga com o resto deste tutorial sem primeiro reiniciar o runtime.
Importe o TensorFlow e os outros módulos necessários do Python.
Importe o dataset
O TensorFlow Dataset penguins/processed padrão já está limpo, normalizado e pronto para a criação de um modelo. Antes de baixar os dados processados, visualize uma versão simplificada para se familiarizar com os dados da pesquisa original sobre os pinguins.
As linhas numeradas são os registros de dados, um exemplo por linha, em que:
Os primeiros seis campos são características: eles são as características de um exemplo. Aqui, os campos têm números que representam as medidas dos pinguins.
A última coluna é o rótulo: é o valor que você quer prever. Para esse dataset, é o valor inteiro 0, 1 ou 2, que corresponde ao nome de uma espécie de pinguim.
No dataset, o rótulo para a espécie de pinguim é representado como um número para facilitar o trabalho com o modelo que você está criando. Esses números correspondem às seguintes espécies de pinguins:
0: pinguim-de-adélia1: pinguim-de-barbicha2: pinguim-gentoo
Crie uma lista com os nomes das espécies de pinguins nessa ordem. Você usará essa lista para interpretar a saída do modelo de classificação:
Para mais informações sobre características e rótulos, confira a seção de Terminologia de ML do Curso Intensivo de Aprendizado de Máquina.
Baixe o dataset pré-processado
Agora, baixe o dataset de pinguins pré-processado (penguins/processed) com o método tfds.load, que retorna uma lista de objetos tf.data.Dataset. O dataset penguins/processed não tem o próprio dataset de teste, então use a divisão 80:20 para separar o dataset completo em datasets de treinamento e teste. Depois, você usará o dataset de teste para verificar seu modelo.
Observe que essa versão do dataset foi processada ao reduzir os dados a quatro características normalizadas e um rótulo de espécie. Nesse formato, os dados podem ser usados rapidamente para treinar um modelo sem processamento adicional.
Visualize alguns grupos ao fazer a plotagem de algumas características do lote:
Crie um modelo linear simples
Por que um modelo?
Um modelo é uma relação entre características e o rótulo. Para o problema de classificação de pinguins, o modelo define a relação entre a massa corporal, as medidas da nadadeira e do cúlmen e a espécie de pinguim prevista. Alguns modelos simples podem ser descritos com algumas linhas de álgebra, mas modelos de aprendizado de máquina complexos têm um número maior de parâmetros que são difíceis de resumir.
Você consegue determinar a relação entre as quatro características e a espécie de pinguim sem usar aprendizado de máquina? Ou seja, você consegue usar técnicas de programação tradicional (por exemplo, várias declarações condicionais) para criar um modelo? Talvez — se você analisar o dataset por tempo suficiente para determinar as relações entre a massa corporal e as medidas do cúlmen de uma determinada espécie. E isso se torna difícil — talvez impossível — em datasets mais complicados. Uma boa abordagem de aprendizado de máquina determina o modelo para você. Se você alimentar o tipo de modelo de aprendizado de máquina correto com um número suficiente de exemplos representativos, o programa descobre as relações para você.
Selecione o modelo
Em seguida, você precisa selecionar o tipo de modelo para treinar. Há vários tipos de modelos e, para escolher um bom, é preciso experiência. Este tutorial usa uma rede neural para resolver o problema de classificação de pinguins. As redes neurais conseguem encontrar relações complexas entre características e o rótulo. É um grafo altamente estruturado, organizado em uma ou mais camadas ocultas. Cada camada oculta consiste em um ou mais neurônios. Há várias categorias de redes neurais, e este programa usa uma rede neural totalmente conectada ou densa: os neurônios em uma camada recebem conexões de entrada de todos os neurônios na camada anterior. Por exemplo, a Figura 2 ilustra uma rede neural densa que consiste em uma camada de entrada, duas camadas ocultas e uma camada de saída:
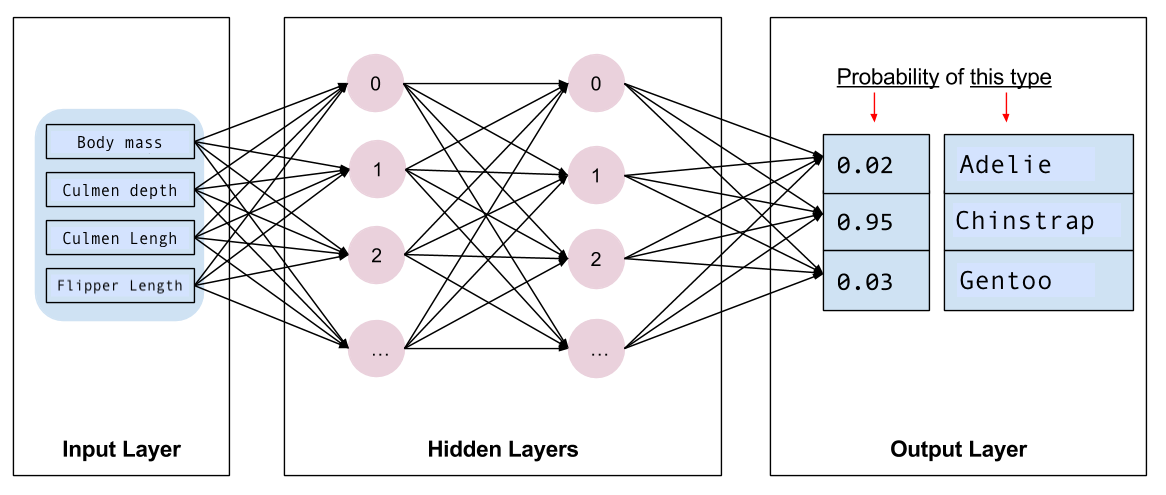 |
| Figura 2. Uma rede neural com características, camadas ocultas e previsões. |
Ao treinar o modelo da Figura 2 e o alimentar com um exemplo não rotulado, são geradas três previsões: a probabilidade que esse pinguim é da espécie específica. Essa previsão é chamada de inferência. Para esse exemplo, a soma das previsões de saída é 1.0. Na Figura 2, essa previsão é detalhada como: 0.02 para pinguins-de-adélia, 0.95 para pinguins-de-barbicha e 0.03 para pinguins-gentoo. Isso significa que o modelo prevê — com 95% de probabilidade — que um exemplo de pinguim não rotulado é um pinguim-de-barbicha.
Crie um modelo usando Keras
A API tf.keras do TensorFlow é a maneira recomendada de criar modelos e camadas. Assim, é fácil criar modelos e realizar testes enquanto o Keras lida com a complexidade de conectar tudo.
O modelo tf.keras.Sequential é uma pilha linear de camadas. O construtor dele considera uma lista de instâncias de camadas. Nesse caso, duas camadas tf.keras.layers.Dense, cada uma com 10 nós, e uma camada de saída com 3 nós, representando suas previsões de rótulos. O parâmetro input_shape da primeira camada corresponde ao número de características do dataset e é obrigatório:
A função activation determina o formato de saída de cada nó na camada. Essas não linearidades são importantes — sem elas, o modelo seria equivalente a uma única camada. Há várias tf.keras.activations, mas a ReLU é comum para camadas ocultas.
O número ideal de camadas ocultas e neurônios depende do problema e do dataset. Como vários aspectos do aprendizado de máquina, escolher o melhor formato de rede neural exige uma mistura de conhecimento e testes. Como regra, o aumento do número de camadas ocultas e neurônios geralmente cria um modelo mais poderoso, que exige mais dados para treinar de maneira eficaz.
Use o modelo
Vamos conferir o que esse modelo faz com um lote de características:
Ao obter o tf.math.argmax das classes, temos o índice de classe previsto. No entanto, o modelo ainda não foi treinado, então as previsões não são boas:
Treine o modelo
O treinamento é o estágio do aprendizado de máquina em que o modelo é otimizado gradualmente ou aprende o dataset. A meta é aprender o suficiente sobre a estrutura do dataset de treinamento para fazer previsões sobre dados desconhecidos. Se você aprender demais sobre o dataset de treinamento, então as previsões só funcionarão para os dados conhecidos e não serão generalizáveis. Esse problema é chamado de overfitting, é como memorizar as respostas em vez de entender como resolver um problema.
O problema de classificação de pinguins é um exemplo de aprendizado de máquina supervisionado: o modelo é treinado a partir de exemplos que contêm rótulos. No aprendizado de máquina não supervisionado, os exemplos não contêm rótulos. Em vez disso, o modelo geralmente encontra padrões entre as características.
Defina as funções de perda e gradiente
Em ambos os estágios de treinamento e avaliação, é preciso calcular a perda do modelo. Isso mede quão distantes as previsões de um modelo estão do rótulo desejado ou, em outras palavras, quão ruim é o desempenho do modelo. Você deve minimizar ou otimizar esse valor.
Seu modelo calculará a perda usando a função tf.keras.losses.SparseCategoricalCrossentropy, que pega as previsões de probabilidade de classe do modelo e o rótulo desejado e retorna a perda média dos exemplos.
Use o contexto tf.GradientTape para calcular os gradientes usados para otimizar seu modelo:
Crie um otimizador
Um otimizador aplica os gradientes computados aos parâmetros do modelo para minimizar a função loss. Pense na função de perda como uma superfície curvada (consulte a Figura 3), e você quer encontrar o ponto mais baixo caminhando por ela. Os gradientes apontam na direção da subida mais íngreme, então você percorrerá o caminho oposto e descerá o morro. Ao calcular iterativamente a perda e o gradiente de cada lote, você ajustará o modelo durante o treinamento. Gradualmente, o modelo encontrará a melhor combinação de pesos e bias para minimizar a perda. Quanto menor for a perda, melhores serão as previsões do modelo.
 |
| Figura 3. Algoritmos de otimização visualizados ao longo do tempo em um espaço 3D. (Fonte: Stanford class CS231n, Licença MIT, Crédito da imagem: Alec Radford) |
O TensorFlow tem vários algoritmos de otimização disponíveis para treinamento, Neste tutorial, você usará o tf.keras.optimizers.SGD, que implementa o algoritmo de método do gradiente estocástico (SGD). O parâmetro learning_rate define o tamanho do passo tomado para cada iteração de descida. Essa taxa é um hiperparâmetro que você ajustará com frequência para alcançar melhores resultados.
Instancie o otimizador com uma taxa de aprendizado de 0.01, um valor escalar que é multiplicado pelo gradiente em cada iteração do treinamento:
Depois, use esse objeto para calcular um único passo de otimização:
Loop de treinamento
Com tudo em seu devido lugar, o modelo está pronto para o treinamento! Um loop de treinamento alimenta o modelo com exemplos do dataset para ajudá-lo a fazer previsões. O bloco de código a seguir configura estas etapas de treinamento:
Itere cada época. Uma época é uma passagem pelo dataset.
Em uma época, itere cada exemplo do
Datasetde treinamento ao pegar as características (x) e o rótulo (y).Usando as características do exemplo, faça uma previsão e a compare com o rótulo. Meça a inexatidão da previsão e use isso para calcular a perda e os gradientes do modelo.
Use um
optimizerpara atualizar os parâmetros do modelo.Acompanhe algumas estatísticas para visualização.
Repita para cada época.
A variável num_epochs é o número de loops na coleção do dataset. No código abaixo, num_epochs está definido como 201, ou seja, esse loop de treinamento será executado 201 vezes. De maneira contraintuitiva, um treinamento mais longo não garante um modelo melhor. num_epochs é um hiperparâmetro que você pode ajustar. A escolha do número correto geralmente requer experiência e testes.
Como opção, você pode usar o método Model.fit(ds_train_batch) built-in do Keras para treinar seu modelo.
Visualize a função de perda ao longo do tempo
Embora seja útil imprimir o progresso de treinamento do modelo, você pode visualizá-lo com o TensorBoard, uma ferramenta de visualização e métricas que acompanha o TensorFlow. Para esse exemplo simples, você criará gráficos básicos usando o módulo matplotlib.
A interpretação desses gráficos exige um pouco de experiência, mas, em geral, a perda deve cair e a exatidão deve aumentar:
Avalie a eficácia do modelo
Agora que o modelo foi treinado, você pode obter algumas estatísticas sobre o desempenho dele.
Avaliar significa determinar a eficácia do modelo em fazer previsões. Para determinar a eficácia do modelo na classificação de pinguins, forneça algumas medidas ao modelo e peça para prever quais espécies de pinguins elas representam. Em seguida, compare as previsões do modelo com o rótulo real. Por exemplo, um modelo que escolheu a espécie correta na metade dos exemplos de entrada tem uma exatidão de 0.5. A Figura 4 mostra um modelo um pouco mais eficaz, que acerta 4 a cada 5 previsões, com 80% de exatidão:
| Características de exemplo | Rótulo | Previsão do modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Um classificador de pinguins com 80% de exatidão. |
Configure o dataset de teste
A avaliação do modelo é parecida com o treinamento dele. A maior diferença é que o exemplo vem de um dataset de teste separado, em vez do dataset de treinamento. Para avaliar de maneira justa a eficácia de um modelo, os exemplos usados para isso precisam ser diferentes dos exemplos usados para treinar o modelo.
O dataset de pinguins não tem um dataset de teste separado. Então, na seção anterior "Baixe o dataset", você dividiu o dataset original em datasets de teste e treinamento. Use o dataset ds_test_batch para a avaliação.
Avalie o modelo com o dataset de teste
Ao contrário da etapa de treinamento, o modelo só avalia uma única época dos dados de teste. O código a seguir itera cada exemplo do dataset de teste e compara a previsão do modelo com o rótulo real. Essa comparação é usada para medir a exatidão do modelo em todo o dataset de teste.
Você também pode usar a função do Keras model.evaluate(ds_test, return_dict=True) para obter informações de exatidão do dataset de teste.
Ao inspecionar o último lote, por exemplo, você pode observar que as previsões do modelo geralmente estão corretas.
Use o modelo treinado para fazer previsões
Você treinou um modelo e "comprovou" que ele é bom — mas não perfeito — em classificar espécies de pinguins. Agora, vamos usar o modelo treinado para fazer algumas previsões de exemplos sem rótulos, ou seja, exemplos com características, mas sem rótulos.
Na vida real, os exemplos não rotulados podem vir de diferentes origens, incluindo apps, arquivos CSV e feeds de dados. Para este tutorial, forneça manualmente três exemplos não rotulados para prever seus rótulos. Lembre-se de que os números dos rótulos são mapeados para uma representação de nomes, conforme o seguinte:
0: pinguim-de-adélia1: pinguim-de-barbicha2: pinguim-gentoo