
Path: blob/master/site/pt-br/tutorials/load_data/video.ipynb
38324 views
Copyright 2022 The TensorFlow Authors.
Carregue dados de vídeo
 Ver fonte no GitHub
Ver fonte no GitHubEste tutorial mostra como carregar e pré-processar dados de vídeos AVI usando o dataset de ações humanas UCF101. Depois de pré-processar os dados, usados para tarefas de vídeo como classificação/reconhecimento, legendagem ou clustering. O dataset original contém vídeos de ações realísticas do YouTube com 101 categorias, como tocar violoncelo, escovar os dentes e maquiar os olhos. Você aprenderá a:
Carregar os dados a partir de um arquivo zip.
Ler sequências de frames dos arquivos de vídeo.
Visualizar os dados dos vídeos.
Empacotar o
tf.data.Datasetgerador de frames.
Este tutorial de carregamento e pré-processamento de vídeos é a primeira parte de uma série de tutoriais do TensorFlow sobre vídeos. Aqui estão os outros três tutoriais:
Crie um modelo CNN 3D para a classificação de vídeos: observe que este tutorial usa uma CNN (2+1)D que decompõe os aspectos espaciais e temporais dos dados 3D. Se você estiver usando dados volumétricos como uma ressonância magnética, considere usar uma CNN 3D em vez de uma CNN (2+1)D.
MoViNet para o reconhecimento de ações de streaming: conheça os modelos MoViNet disponíveis no TF Hub.
Aprendizado por transferência para a classificação de vídeos com MoViNet: este tutorial explica como usar um modelo de classificação de vídeos pré-treinado em um dataset diferente com o dataset UCF-101.
Configuração
Comece instalando e importando algumas bibliotecas necessárias, incluindo: remotezip para inspecionar o conteúdo de um arquivo ZIP, tqdm para usar uma barra de progresso, OpenCV para processar arquivos de vídeo e tensorflow_docs para incorporar dados em um notebook Jupyter.
Baixe um subconjunto do dataset UCF101
O dataset UCF101 contém 101 categorias de ações diferentes em vídeo, usadas principalmente no reconhecimento de ações. Você usará um subconjunto dessas categorias nesta demonstração.
A URL acima contém um arquivo zip com o dataset UCF 101. Crie uma função que usa a biblioteca remotezip para examinar o conteúdo do arquivo zip nessa URL:
Comece com alguns vídeos e um número limitado de classes para treinamento. Depois de executar o bloco de código acima, observe que o nome da classe está incluso no nome de arquivo de cada vídeo.
Defina a função get_class que recupera o nome da classe a partir de um nome de arquivo. Em seguida, crie uma função chamada get_files_per_class que converte a lista de todos os arquivos (files acima) em um dicionário listando os arquivos para cada classe:
Depois de obter a lista de arquivos por classe, você pode escolher o número de classes que quer usar e o número de vídeos desejado por classe para criar seu dataset.
Crie uma nova função chamada select_subset_of_classes que seleciona um subconjunto de classes presentes no dataset e um número específico de arquivos por classe:
Defina as funções helper que dividem os vídeos em datasets de treinamento, validação e teste. Os vídeos são baixados de uma URL com o arquivo zip e colocados nos respectivos subdiretórios.
A seguinte função retorna os dados restantes que não foram colocados em um subconjunto de dados. Assim, você pode colocar os dados restantes no próximo subconjunto de dados especificado.
A função download_ucf_101_subset permite que você baixe um subconjunto do dataset UCF101 e o divida em datasets de treinamento, validação e teste. Você pode especificar o número de classes que gostaria de usar. O argumento splits permite que você passe um dicionário em que os valores-chave são o nome do subconjunto (exemplo: "trem") e o número de vídeos desejado por classe.
Depois de baixar os dados, você terá uma cópia de um subconjunto do dataset UCF101. Execute o código abaixo para imprimir o número total de vídeos entre todos os seus subconjuntos de dados.
Você também pode visualizar o diretório de arquivos de dados agora.
Crie frames a partir de cada arquivo de vídeo
A função frames_from_video_file divide os vídeos em frames, lê um intervalo de n_frames escolhidos aleatoriamente de um arquivo de vídeo e os retorna como um array do NumPy. Para reduzir a sobrecarga computacional e na memória, escolha um número pequeno de frames. Além disso, escolha o mesmo número de frames de cada vídeo, o que facilita o trabalho com lotes de dados.
Visualize os dados de vídeo
A função frames_from_video_file retorna um conjunto de frames como um array do NumPy. Tente usar essa função em um novo vídeo da Wikimedia{:.external}, de Patrick Gillett:
Além de examinar esse vídeo, você também pode mostrar os dados do UCF-101. Para isso, execute o código a seguir:
Em seguida, defina a classe FrameGenerator para criar um objeto iterável que possa alimentar o pipeline de dados do TensorFlow. A função (__call__) gera o array de frames produzido por frames_from_video_file e um vetor de one-hot encoding do rótulo associado ao conjunto de frames.
Teste o objeto FrameGenerator antes de empacotá-lo como um objeto do TensorFlow Dataset. Além disso, para os dados de treinamento, ative o modo de treinamento para que os dados sejam misturados.
Por fim, crie um pipeline de entrada de dados do TensorFlow. Esse pipeline criado a partir do objeto gerador permite que você alimente seu modelo de aprendizado profundo com dados. Nesse pipeline de vídeo, cada elemento é um único conjunto de frames e o rótulo associado a ele.
Confira se os rótulos foram misturados.
Configure o dataset para melhor desempenho
Utilize a pré-busca em buffer para gerar dados a partir do disco sem o bloqueio de I/O. Veja duas funções importantes para usar ao carregar os dados:
Dataset.cachemantém o conjunto de frames na memória após o carregamento fora do disco durante a primeira época. Essa função garante que o dataset não se torne um gargalo ao treinar seu modelo. Se o dataset for muito grande para a memória, você também pode usar esse método para criar um cache no disco eficaz.Dataset.prefetch: sobrepõe o processamento de dados e a execução do modelo durante o treinamento. Confira mais detalhes no guia Melhor desempenho com otf.data.
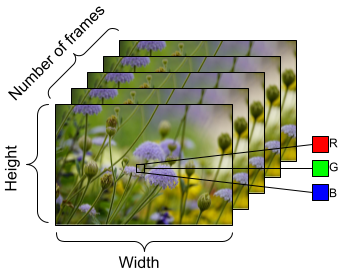
Para preparar os dados que alimentarão o modelo, use os lotes conforme mostrado abaixo. Observe que, ao trabalhar com dados de vídeo, como arquivos AVI, eles devem estar no formato de um objeto pentadimensional [batch_size, number_of_frames, height, width, channels]. Em comparação, uma imagem teria quatro dimensões: [batch_size, height, width, channels]. A imagem abaixo é uma ilustração de como o formato dos dados de vídeo é representado.
Próximos passos
Agora que você criou um Dataset do TensorFlow de frames de vídeos com seus rótulos, você pode usá-lo com um modelo de aprendizado profundo. O seguinte modelo de classificação que usa uma EfficientNet{:.external} pré-treinada realiza o treinamento com alta exatidão em alguns minutos:
Para saber mais sobre como trabalhar com dados de vídeo no TensorFlow, confira os tutoriais a seguir: