
Path: blob/master/site/pt-br/tutorials/understanding/sngp.ipynb
38975 views
Copyright 2021 The TensorFlow Authors.
Aprendizado profundo com SNGP com reconhecimento de incerteza
 Ver no GitHub
Ver no GitHubEm aplicações de inteligência artificial críticas, como tomada de decisão médica e veículos autônomos, ou quando os dados têm ruído inerente (por exemplo, compreensão de língua natural), é importante que um classificador profundo quantifique a incerteza com confiança. O classificador profundo deve conseguir reconhecer suas próprias limitações e quando deve passar o controle para especialistas humanos. Este tutorial mostra como melhorar a capacidade de um classificador profundo de quantificar a incerteza usando uma técnica chamada Processo Gaussiano Neural normalizado espectral (SNGP, na sigla em inglês{.external}).
A ideia principal do SNGP é melhorar o reconhecimento de distância de um classificador profundo por meio de modificações simples da rede. O reconhecimento de distância de um modelo é uma medida de como sua probabilidade preditiva reflete a distância entre o exemplo de teste e os dados de treinamento. É uma propriedade desejável comum aos modelos probabilísticos padrão-ouro (por exemplo, o processo gaussiano{.external} com kernels RBF), mas que falta nos modelos com redes neurais profundas. O SNGP oferece uma maneira simples de incorporar esse comportamento de processo gaussiano a um classificador profundo, mantendo sua exatidão preditiva.
Este tutorial implementa um modelo de SNGP de rede residual profunda baseado em ResNet no dataset two moons do scikit-learn{.external} (duas Luas) e compara sua superfície de incerteza com a de duas outras estratégias de incerteza comuns: dropout de Monte Carlo{.external} e Ensemble profundo{.external}.
Este tutorial ilustra o modelo de SNGP em um dataset bidimensional de brinquedo. Para ver um exemplo de como aplicar o SNGP a uma tarefa real de compreensão de língua natural usando uma base BERT, confira o tutorial SNGP-BERT. Para ver implementações de alta qualidade de um modelo de SNGP (e muitos outros métodos de incerteza) em uma grande variedade de conjuntos referenciais (como CIFAR-100, ImageNet, Jigsaw toxicity detection, etc), confira o referencial Linhas de base de incerteza{.external}.
Sobre o SNGP
O SNGP é uma estratégia simples para melhorar a qualidade de incerteza de um classificador profundo mantendo um nível similar de exatidão e latência. Dada uma rede residual profunda, o SNGP faz duas alterações simples no modelo:
Aplica a normalização espectral às camadas residuais ocultas.
Substitui a camada de saída Dense por uma camada de processo gaussiano.
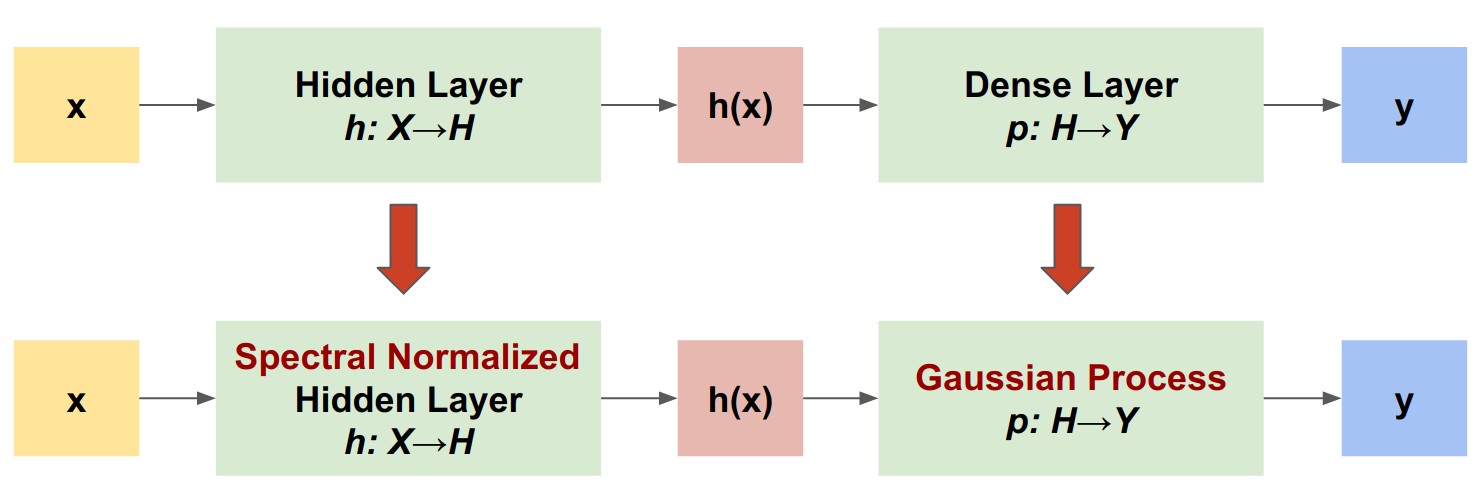
Comparado a outras estratégias de incerteza (como dropout de Monte Carlo e Ensemble profundo), o SNGP tem diversas vantagens:
Funciona com diversas arquiteturas residuais de última geração (por exemplo, (Wide) ResNet, DenseNet ou BERT).
É um método com um único modelo (não depende da média do ensemble). Portanto, o SNGP tem um nível similar de latência de uma única rede determinística e pode ser facilmente dimensionado para datasets grandes, como ImageNet{.external} e Jigsaw Toxic Comments classification{.external}.
Tem um bom desempenho de detecção fora do domínio devido à propriedade de reconhecimento de distância.
As desvantagens deste método são:
A incerteza preditiva do SNGP é computada usando-se o método de aproximação de Laplace{.external}. Portanto, teoricamente, a incerteza posterior do SNGP é diferente da de um processo gaussiano exato.
O treinamento do SNGP requer uma etapa de redefinição da covariância no começo de uma nova época, o que pode adicionar uma pequena complexidade extra a um pipeline de treinamento. Este tutorial mostra uma forma simples de implementar isso usando callbacks do Keras.
Configuração
Defina as macros de visualização
Dataset two moon (duas Luas)
Crie os datasets de treinamento e avaliação a partir do dataset two moon do scikit-learn{.external}.
Avalie o comportamento preditivo do modelo para todo o espaço de entrada bidimensional.
Para avaliar a incerteza do modelo, adicione um dataset fora do domínio (OOD, na sigla em inglês) que pertença a uma terceira classe. O modelo nunca observa esses exemplos OOD durante o treinamento.
Aqui, azul e laranja representam as classes positivas e negativas, enquanto vermelho representa os dados OOD. Espera-se que um modelo que quantifique bem a incerteza tenha confiança quando próximo dos dados de treinamento (ou seja, próximo de 0 ou 1), e tenha incerteza quando distante das regiões dos dados de treinamento (ou seja, próximo de 0,5).
Modelo determinístico
Defina o modelo
Comece pelo modelo determinístico (linha de base): uma rede (ResNet) multicamada com regularização de dropout.
Este tutorial utiliza uma ResNet de seis camadas, com 128 unidades ocultas.
Treine o modelo
Configure os parâmetros de treinamento para usar SparseCategoricalCrossentropy como a função de perda e o otimizador Adam.
Treine o modelo com 100 épocas e tamanho de lote igual a 128.
Visualize a incerteza
Agora, visualize as predições do modelo determinístico. Primeiro plote a probabilidade da classe:
Neste gráfico, amarelo e roxo são as probabilidades preditivas das duas classes. O modelo determinístico teve bom desempenho ao classificar as duas classes desconhecidas, azul e laranja, com um limite de decisão não linear. Entretanto, ele não tem reconhecimento de distância e classificou os exemplos fora do domínio (OOD) vermelhos, nunca observados antes, como a classe laranja com confiança.
Para visualizar a incerteza do modelo, calcule a variância preditiva:
Neste gráfico, amarelo indica incerteza alta, e roxo indica incerteza baixa. A incerteza de uma ResNet determinística depende somente da distância entre os exemplos de teste e o limite de decisão. Isso faz o modelo ter uma confiança alta demais quando fora do domínio de treinamento. A próxima seção mostra como o SNGP se comporta de maneira diferente para este dataset.
Modelo de SNGP
Defina o modelo de SNGP
Agora, vamos implementar o modelo de SNGP. Os dois componentes do SNGP, SpectralNormalization e RandomFeatureGaussianProcess, estão disponíveis nas camadas integradas do modelo do TensorFlow.
Vamos avaliar esses dois componentes com mais detalhes (você também pode ir para a seção modelo de SNGP completo para ver como o SNGP é implementado).
Encapsulador SpectralNormalization
SpectralNormalization{.external} é um encapsulador de camadas do Keras e pode ser aplicado a uma camada Dense existente da seguinte forma:
A normalização espectral normaliza o peso oculto ao levar gradualmente sua norma espectral (ou seja, o autovalor mais alto de ) em direção ao valor alvo norm_multiplier.
Observação: geralmente, é preferível definir norm_multiplier como um valor menor do que 1. Entretanto, na prática, também pode ser definido como um valor mais alto para garantir que a rede profunda tenha potência expressiva suficiente.
Camada do processo gaussiano
RandomFeatureGaussianProcess{.external} implementa uma aproximação baseada em característica aleatória{.external} de um modelo de processo gaussiano que pode ser treinado do começo ao fim com uma rede neural profunda. Em segundo plano, a camada do processo gaussiano implementa uma rede de duas camadas:
Aqui, é a entrada, e e são pesos congelados inicializados aleatoriamente a partir das distribuições gaussiana e uniforme, respectivamente (portanto, são chamadas de "características aleatórias"). é o peso de kernel que pode ser aprendido, similar ao de uma camada Dense.
Os principais parâmetros das camadas do processo gaussiano são:
units: dimensão dos logits de saída.num_inducing: dimensão do peso oculto . O padrão é 1024.normalize_input: define se a normalização da camada deve ser aplicada à entrada .scale_random_features: define se a escala deve ser aplicada à saída oculta.
Observação: para uma rede neural profunda sensível à taxa de aprendizado (por exemplo, ResNet-50 e ResNet-110), geralmente recomenda-se definir normalize_input=True para estabilizar o treinamento e definir scale_random_features=False para evitar que a taxa de aprendizado seja modificada de formas inesperadas ao passar pela camada do processo gaussiano.
gp_cov_momentumcontrola como a covariância do modelo é calculada. Se definido como um valor positivo (por exemplo,0.999), a matriz de covariância é calculada usando-se a atualização da média móvel baseada no momento (similar à normalização de lotes). Se definido como-1, a matriz de covariância é atualizada sem usar o momento.
Observação: o método de avaliação com base no momento pode ser sensível ao tamanho do lote. Portanto, geralmente recomenda-se definir gp_cov_momentum=-1 para calcular o valor exato da covariância. Para que isso funcione corretamente, o estimador da matriz de covariância precisa ser redefinido no começo de cada época para evitar a contabilização dos mesmos dados duas vezes. Para RandomFeatureGaussianProcess, isso pode ser feito realizando uma chamada a reset_covariance_matrix(). A próxima seção mostra uma implementação fácil usando a API integrada do Keras.
Dada uma entrada de lote com formato (batch_size, input_dim), a camada do processo gaussiano retorna um tensor logits (formato (batch_size, num_classes)) para a previsão, além de um tensor covmat (formato (batch_size, batch_size)), que é a matriz de covariância posterior dos logits do lote.
Observação: com esta implementação do modelo de SNGP, os logits preditivos de todas as classes compartilham a mesma matriz de covariância , que descreve a distância entre e os dados de treinamento.
Teoricamente, é possível estender o algoritmo para calcular os diferentes valores de covariância para as diferentes classes (conforme discutido no artigo original sobre SNGP{.external}). Entretanto, é difícil fazer isso para problemas com espaços de saída grandes (como classificação com ImageNet ou modelagem de língua).
Dada a classe base DeepResNet, é fácil implementar o modelo de SNGP por meio da modificação das camadas ocultas e da saída da rede residual. Para fins de compatibilidade com a API model.fit() do Keras, modifique também o método call() do modelo para que gere somente os logits durante o treinamento.
Utilize a mesma arquitetura usada no modelo determinístico:
Adicione esse callback à classe do modelo DeepResNetSNGP.
Treine o modelo
Use tf.keras.model.fit para treinar o modelo.
Visualize a incerteza
Primeiro, calcule as variâncias e os logits preditivos.
Agora, calcule a probabilidade preditiva posterior. O método clássico para calcular a probabilidade preditiva de um modelo probabilístico é usando a amostragem de Monte Carlo:
em que é o tamanho da amostra, e são amostras aleatórias do (sngp_logits posterior do SNGP, sngp_covmat). Entretanto, essa estratégia pode ser lenta demais para aplicações sensíveis à latência, como veículos autônomos ou leilão em tempo real. Em vez disso, você pode aproximar usando o método do campo médio{.external}:
em que é a variância do SNGP, e geralmente é escolhido como ou .
Observação: em vez de fixar , você também pode tratá-lo como um hiperparâmetro para otimizar o desempenho de calibração do modelo. Isso é conhecido como Temperature Scaling{.external} (dimensionamento de temperatura) na literatura sobre incerteza em aprendizado profundo.
Esse método do campo médio é implementado como uma função integrada layers.gaussian_process.mean_field_logits:
Resumo do SNGP
Agora você pode juntar tudo. Todo o procedimento — treinamento, avaliação e cálculo da incerteza — pode ser feito em apenas cinco linhas:
Visualize a probabilidade das classes (à esquerda) e a incerteza preditiva (à direita) do modelo de SNGP.
Lembre-se de que, no gráfico de probabilidades de classes (à esquerda), amarelo e roxo são as probabilidades das classes. Quando próximo do domínio dos dados de treinamento, o SNGP classifica corretamente os exemplos com confiança alta (ou seja, atribuição perto da probabilidade 0 ou 1). Quando distante dos dados de treinamento, o SNGP fica cada vez mais menos confiante, e sua probabilidade preditiva se aproxima de 0,5, enquanto a incerteza do modelo (normalizada) sobe para 1.
Compare com a superfície de incerteza do modelo determinístico:
Conforme mencionado anteriormente, um modelo determinístico não tem reconhecimento de distância. Sua incerteza é definida pela distância entre o exemplo de teste e o limite de decisão. Isso faz o modelo gerar previsões com confiança alta demais para os exemplos fora do domínio (vermelhos).
Comparação com outras estratégias de incerteza
Esta seção compara a incerteza do SNGP com Dropout de Monte Carlo{.external} e Ensemble profundo{.external}.
Os dois métodos são baseados na média de Monte Carlo de diversos passos para frente de modelos determinísticos. Primeiro, defina o tamanho do ensemble .
Dropout de Monte Carlo
Dada uma rede neural treinada com camadas de dropout, o dropout de Monte Carlo calcula a probabilidade preditiva média:
fazendo a média de diversos passos para frente com dropout .
Ensemble profundo
O ensemble profundo é um método de última geração (porém caro) para incerteza em aprendizado profundo. Para treinar um ensemble profundo, primeiro treine os membros do ensemble .
Colete os logits e calcule a probabilidade preditiva média .
Tanto o método de dropout de Monte Carlo quanto o de ensemble profundo melhoram a capacidade de incerteza do modelo ao diminuir a certeza do limite de decisão. Entretanto, ambos herdam a limitação de redes profundas determinísticas: a falta de reconhecimento de distância.
Resumo
Neste tutorial, você:
Implementou o modelo de SNGP em um classificador profundo para melhorar seu reconhecimento de distância.
Treinou o modelo de SNGP do começo ao fim usando a API
Model.fitdo Keras.Visualizou o comportamento da incerteza do SNGP.
Comparou o comportamento da incerteza entre os modelos de SNGP, dropout de Monte Carlo e ensemble profundo.
Recursos e leitura adicional
Confira o tutorial SNGP-BERT para ver um exemplo de como aplicar o SNGP a um modelo BERT para a compreensão de língua natural com reconhecimento de incerteza.
Acesse o repositório do GitHub Linhas de base de incerteza{.external} para ver a implementação do modelo de SNGP (e muitos outros métodos de incerteza) para uma variedade de datasets referenciais (por exemplo, CIFAR, ImageNet, Jigsaw toxicity detection, etc).
Para ter uma compreensão mais profunda do método do SNGP, confira o artigo Estimativa simples do princípio da incerteza com aprendizado profundo determinístico via reconhecimento de distância{.external}.