
Path: blob/master/site/pt-br/tutorials/video/video_classification.ipynb
38974 views
Copyright 2022 The TensorFlow Authors.
 Ver fonte no GitHub
Ver fonte no GitHubClassificação de vídeos com uma rede neural convolucional 3D
Este tutorial demonstra o treinamento de uma rede neural convolucional (CNN) 3D para classificação de vídeo usando o dataset de reconhecimento de ações UCF101. Uma CNN 3D usa um filtro tridimensional para realizar convoluções. O kernel é capaz de deslizar em três direções, enquanto que numa CNN 2D ele pode deslizar em duas dimensões. O modelo é baseado no trabalho publicado em A Closer Look at Spatiotemporal Convolutions for Action Recognition por D. Tran et al. (2017). Neste tutorial, você irá:
Construir um pipeline de entrada
Construir um modelo de rede neural convolucional 3D com conexões residuais usando a API funcional Keras
Treinar o modelo
Avaliar e testar o modelo
Este tutorial de classificação de vídeo é a segunda parte de uma série de tutoriais em vídeo do TensorFlow. Aqui estão os outros três tutoriais:
Carregando dados de vídeo: Este tutorial explica grande parte do código usado neste documento.
MoViNet para o reconhecimento de ações de streaming: conheça os modelos MoViNet disponíveis no TF Hub.
Aprendizado por transferência para a classificação de vídeos com MoViNet: este tutorial explica como usar um modelo de classificação de vídeos pré-treinado em um dataset diferente com o dataset UCF-101.
Configuração
Comece instalando e importando algumas bibliotecas necessárias, incluindo: remotezip para inspecionar o conteúdo de um arquivo ZIP, tqdm para usar uma barra de progresso, OpenCV para processar arquivos de vídeo, einops para realizar operações de tensor mais complexas e tensorflow_docs para incorporar dados em um notebook Jupyter.
Observação: use o TensorFlow 2.10 para executar este tutorial. Versões acima do TensorFlow 2.10 podem não ser executadas com sucesso.
Carregamento e pré-processamento dos dados de vídeo
A célula oculta abaixo define funções auxiliares para baixar uma fatia de dados do dataset UCF-101 e carregá-los num tf.data.Dataset. Você pode aprender mais sobre os passos específicos de pré-processamento no tutorial Carregando dados de vídeo, que apresenta instruções detalhadas sobre esse código.
A classe FrameGenerator no final do bloco oculto é o utilitário mais importante que temos aqui, pois cria um objeto iterável que pode alimentar dados no pipeline de dados do TensorFlow. Especificamente, essa classe contém um gerador Python que carrega os quadros do vídeo juntamente com seu rótulo codificado. A função geradora (__call__) gera a array de quadros produzida por frames_from_video_file e um vetor com codificação one-hot do rótulo associado ao conjunto de quadros.
Crie os datasets de treinamento, validação e teste (train_ds , val_ds e test_ds).
Criação do modelo
O seguinte modelo de rede neural convolucional 3D é baseado no artigo A Closer Look at Spatiotemporal Convolutions for Action Recognition de D. Tran et al. (2017). O artigo compara várias versões de ResNets 3D. Em vez de operar em uma única imagem com dimensões (height, width), como os ResNets padrão, estes operam no volume do vídeo (time, height, width). A abordagem mais óbvia para este problema seria substituir cada convolução 2D (layers.Conv2D) por uma convolução 3D (layers.Conv3D).
Este tutorial usa uma convolução (2 + 1)D com conexões residuais. A convolução (2 + 1)D permite a decomposição das dimensões espacial e temporal, criando assim dois passos distintos. Uma vantagem desta abordagem é que a fatoração das convoluções em dimensões espaciais e temporais economiza parâmetros.
Para cada local de saída, uma convolução 3D combina todos os vetores de um patch 3D do volume para criar um vetor no volume de saída.
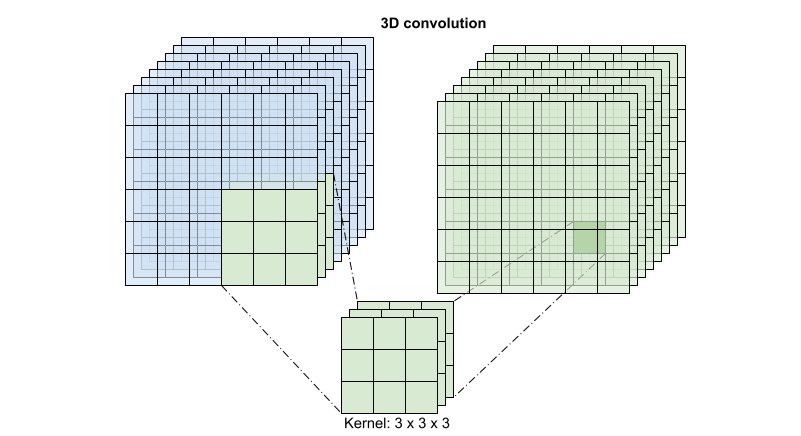
Esta operação leva time * height * width * channels e produz saídas channels (assumindo que o número de canais de entrada e saída são iguais. Portanto, uma camada de convolução 3D com um tamanho de kernel de (3 x 3 x 3) precisaria de uma matriz de pesos com 27 * channels ** 2 entradas. O artigo de referência descobriu que uma abordagem mais eficaz e eficiente era fatorar a convolução. Em vez de uma única convolução 3D para processar as dimensões de tempo e espaço, eles propuseram uma convolução "(2+1 )D" que processa as dimensões de espaço e tempo separadamente. A figura abaixo mostra as convoluções espaciais e temporais fatoradas de uma convolução (2 + 1)D.
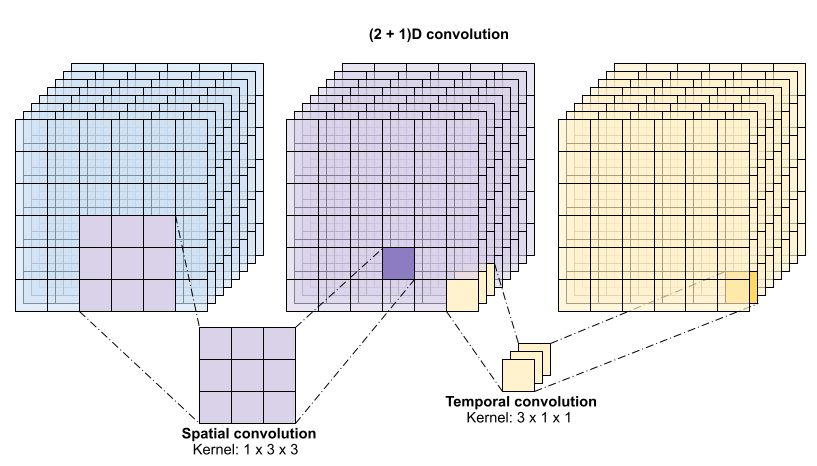
A principal vantagem desta abordagem é que ela reduz o número de parâmetros. Na convolução (2 + 1)D, a convolução espacial recebe dados no formato (1, width, height), enquanto a convolução temporal recebe dados no formato (time, 1, 1). Por exemplo, uma convolução (2 + 1)D com tamanho de kernel (3 x 3 x 3) precisaria de matrizes de peso de tamanho (9 * channels**2) + (3 * channels**2), menos da metade da convolução 3D completa. Este tutorial implementa (2 + 1)D ResNet18, onde cada convolução na resnet é substituída por uma convolução (2+1)D.
Um modelo ResNet é feito a partir de uma sequência de blocos residuais. Um bloco residual possui duas ramificações. O ramo principal realiza o cálculo, mas dificulta o fluxo dos gradientes. A ramificação residual ignora o cálculo principal e geralmente apenas adiciona a entrada à saída da ramificação principal. Os gradientes fluem facilmente através deste ramo. Portanto, um caminho fácil da função de perda para qualquer ramo principal do bloco residual estará presente. Isto evita o problema do sumiço do gradiente.
Crie a ramificação principal do bloco residual com a seguinte classe. Em contraste com a estrutura ResNet padrão, esta usa a camada Conv2Plus1D personalizada em vez de layers.Conv2D.
Para adicionar o ramo residual ao ramo principal ele precisa ter o mesmo tamanho. A camada Project abaixo trata dos casos em que o número de canais é alterado na ramificação. No caso em particular, é adicionada uma sequência de camadas densamente conectadas seguida de normalização.
Use add_residual_block para introduzir uma conexão de salto entre as camadas do modelo.
O redimensionamento do vídeo é necessário para realizar a redução da resolução dos dados. Em particular, a redução da resolução dos quadros de vídeo permite que o modelo examine partes específicas dos quadros para detectar padrões que podem ser específicos de uma determinada ação. Através da redução da resolução, informações não essenciais podem ser descartadas. Além disso, o redimensionamento do vídeo permitirá a redução da dimensionalidade e garantirá, portanto, um processamento mais rápido através do modelo.
Use a API funcional Keras para construir a rede residual.
Treinamento do modelo
Neste tutorial, escolha o otimizador tf.keras.optimizers.Adam e a função de perda tf.keras.losses.SparseCategoricalCrossentropy. Use o argumento metrics para ver a exatidão do desempenho do modelo a cada passo.
Treine o modelo com 50 épocas usando o método Model.fit do Keras:
Observação: Este modelo de exemplo é treinado em menos pontos de dados (300 exemplos de treinamento e 100 exemplos de validação) para manter o tempo de treinamento razoável para este tutorial. Além disso, este modelo de exemplo pode levar mais de uma hora para ser treinado.
Visualize os resultados
Crie gráficos da perda e da exatidão para os conjuntos de treinamento e avaliação:
Avaliação do modelo
Use Model.evaluate do Keras para obter a perda e a precisão do dataset de dados de teste.
Observação: o modelo de exemplo neste tutorial usa um subconjunto do dataset UCF101 para manter o tempo de treinamento razoável. A precisão e a perda podem ser melhoradas com mais ajustes de hiperparâmetros ou mais dados de treinamento.
Para avaliar o desempenho do modelo com mais detalhes, use uma matriz de confusão, que permite avaliar o desempenho do modelo de classificação além da exatidão. Para criar a matriz de confusão para este problema de classificação multiclasse, obtenha os valores reais do dataset de teste e os valores previstos.
Os valores de precisão e recuperação para cada classe também podem ser calculados usando uma matriz de confusão.
Próximos passos
Para saber mais sobre como trabalhar com dados de vídeo no TensorFlow, confira os seguintes tutoriais: