
Path: blob/master/site/zh-cn/addons/tutorials/losses_triplet.ipynb
39395 views
Kernel: Python 3
Copyright 2020 The TensorFlow Authors.
In [ ]:
TensorFlow Addons 损失:TripletSemiHardLoss
 在 GitHub 中查看源代码
在 GitHub 中查看源代码概述
此笔记本将演示如何使用 TensorFlow Addons 中的 TripletSemiHardLoss 函数。
资源:
TripletLoss
正如 FaceNet 论文中首次介绍的那样,TripletLoss 是一种损失函数,可以训练神经网络紧密嵌入相同类别的特征,同时最大程度地提高不同类别的嵌入向量之间的距离。为此,选择一个锚点以及一个负样本和一个正样本。
损失函数被描述为欧氏距离函数:
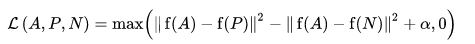
其中,A 是我们的锚点输入,P 是正样本输入,N 是负样本输入,α 是用来指定三元组何时变得过于“容易”并且不再需要调整其权重的间隔。
SemiHard 在线学习
如文中所示,最佳结果来自被称为“Semi-Hard”(一般)的三元组。在这些三元组中,负数比正数离锚点更远,但仍会产生正损失。为了高效地找到这些三元组,我们利用在线学习,并且仅从每个批次的 Semi-Hard 样本中进行训练。
设置
In [ ]:
In [ ]:
In [ ]:
准备数据
In [ ]:
构建模型

In [ ]:
训练和评估
In [ ]:
In [ ]:
In [ ]:
In [ ]:
Embedding Projector
可以在此处加载和可视化向量及元数据文件:https://projector.tensorflow.org/
使用 UMAP 进行可视化时,您可以看到我们嵌入式测试数据的结果: