def get_top_k_streaming_labels(probs, k=5, label_map=KINETICS_600_LABELS):
"""Returns the top-k labels over an entire video sequence.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
k: the number of top predictions to select.
label_map: a list of labels to map logit indices to label strings.
Returns:
a tuple of the top-k probabilities, labels, and logit indices
"""
top_categories_last = tf.argsort(probs, -1, 'DESCENDING')[-1, :1]
categories = tf.argsort(probs, -1, 'DESCENDING')[:, :k]
categories = tf.reshape(categories, [-1])
counts = sorted([
(i.numpy(), tf.reduce_sum(tf.cast(categories == i, tf.int32)).numpy())
for i in tf.unique(categories)[0]
], key=lambda x: x[1], reverse=True)
top_probs_idx = tf.constant([i for i, _ in counts[:k]])
top_probs_idx = tf.concat([top_categories_last, top_probs_idx], 0)
top_probs_idx = tf.unique(top_probs_idx)[0][:k+1]
top_probs = tf.gather(probs, top_probs_idx, axis=-1)
top_probs = tf.transpose(top_probs, perm=(1, 0))
top_labels = tf.gather(label_map, top_probs_idx, axis=0)
top_labels = [label.decode('utf8') for label in top_labels.numpy()]
return top_probs, top_labels, top_probs_idx
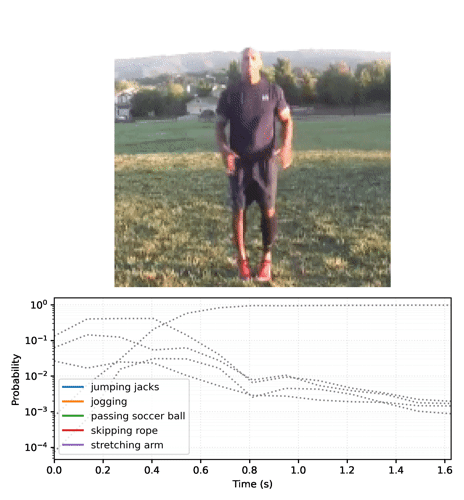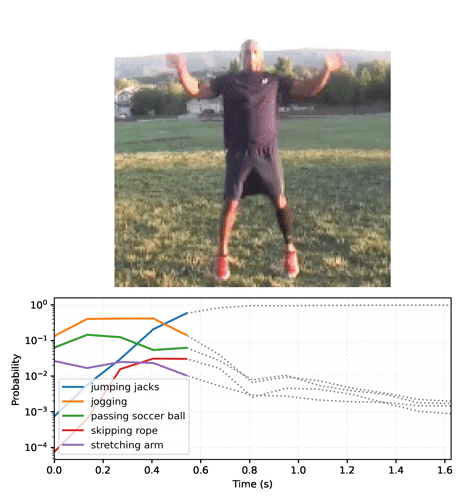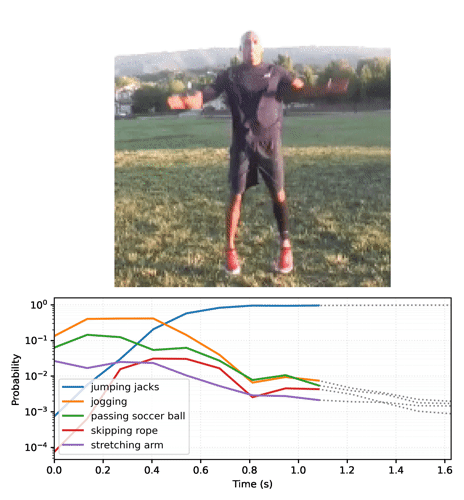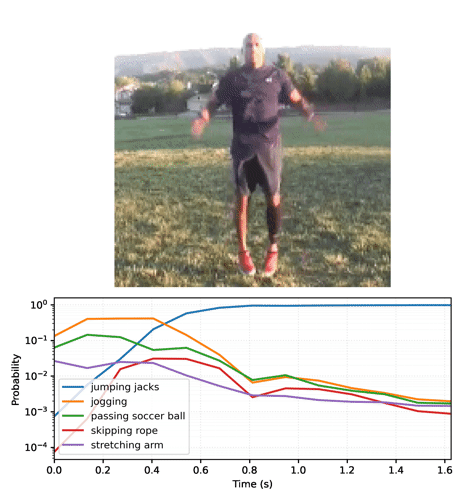
def plot_streaming_top_preds_at_step(
top_probs,
top_labels,
step=None,
image=None,
legend_loc='lower left',
duration_seconds=10,
figure_height=500,
playhead_scale=0.8,
grid_alpha=0.3):
"""Generates a plot of the top video model predictions at a given time step.
Args:
top_probs: a tensor of shape (k, num_frames) representing the top-k
probabilities over all frames.
top_labels: a list of length k that represents the top-k label strings.
step: the current time step in the range [0, num_frames].
image: the image frame to display at the current time step.
legend_loc: the placement location of the legend.
duration_seconds: the total duration of the video.
figure_height: the output figure height.
playhead_scale: scale value for the playhead.
grid_alpha: alpha value for the gridlines.
Returns:
A tuple of the output numpy image, figure, and axes.
"""
num_labels, num_frames = top_probs.shape
if step is None:
step = num_frames
fig = plt.figure(figsize=(6.5, 7), dpi=300)
gs = mpl.gridspec.GridSpec(8, 1)
ax2 = plt.subplot(gs[:-3, :])
ax = plt.subplot(gs[-3:, :])
if image is not None:
ax2.imshow(image, interpolation='nearest')
ax2.axis('off')
preview_line_x = tf.linspace(0., duration_seconds, num_frames)
preview_line_y = top_probs
line_x = preview_line_x[:step+1]
line_y = preview_line_y[:, :step+1]
for i in range(num_labels):
ax.plot(preview_line_x, preview_line_y[i], label=None, linewidth='1.5',
linestyle=':', color='gray')
ax.plot(line_x, line_y[i], label=top_labels[i], linewidth='2.0')
ax.grid(which='major', linestyle=':', linewidth='1.0', alpha=grid_alpha)
ax.grid(which='minor', linestyle=':', linewidth='0.5', alpha=grid_alpha)
min_height = tf.reduce_min(top_probs) * playhead_scale
max_height = tf.reduce_max(top_probs)
ax.vlines(preview_line_x[step], min_height, max_height, colors='red')
ax.scatter(preview_line_x[step], max_height, color='red')
ax.legend(loc=legend_loc)
plt.xlim(0, duration_seconds)
plt.ylabel('Probability')
plt.xlabel('Time (s)')
plt.yscale('log')
fig.tight_layout()
fig.canvas.draw()
data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
plt.close()
figure_width = int(figure_height * data.shape[1] / data.shape[0])
image = PIL.Image.fromarray(data).resize([figure_width, figure_height])
image = np.array(image)
return image
def plot_streaming_top_preds(
probs,
video,
top_k=5,
video_fps=25.,
figure_height=500,
use_progbar=True):
"""Generates a video plot of the top video model predictions.
Args:
probs: probability tensor of shape (num_frames, num_classes) that represents
the probability of each class on each frame.
video: the video to display in the plot.
top_k: the number of top predictions to select.
video_fps: the input video fps.
figure_fps: the output video fps.
figure_height: the height of the output video.
use_progbar: display a progress bar.
Returns:
A numpy array representing the output video.
"""
video_fps = 8.
figure_height = 500
steps = video.shape[0]
duration = steps / video_fps
top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)
images = []
step_generator = tqdm.trange(steps) if use_progbar else range(steps)
for i in step_generator:
image = plot_streaming_top_preds_at_step(
top_probs=top_probs,
top_labels=top_labels,
step=i,
image=video[i],
duration_seconds=duration,
figure_height=figure_height,
)
images.append(image)
return np.array(images)

 在 GitHub 上查看源代码
在 GitHub 上查看源代码