
Path: blob/master/site/zh-cn/tutorials/generative/cyclegan.ipynb
38541 views
Copyright 2019 The TensorFlow Authors.
CycleGAN
 在 GitHub 上查看源代码
在 GitHub 上查看源代码本笔记演示了使用条件 GAN 进行的未配对图像到图像转换,如使用循环一致的对抗网络进行未配对图像到图像转换 中所述,也称之为 CycleGAN。论文提出了一种可以捕捉图像域特征并找出如何将这些特征转换为另一个图像域的方法,而无需任何成对的训练样本。
本笔记假定您熟悉 Pix2Pix,您可以在 Pix2Pix 教程中了解有关它的信息。CycleGAN 的代码与其相似,主要区别在于额外的损失函数,以及非配对训练数据的使用。
CycleGAN 使用循环一致损失来使训练过程无需配对数据。换句话说,它可以从一个域转换到另一个域,而不需要在源域与目标域之间进行一对一映射。
这为完成许多有趣的任务开辟了可能性,例如照片增强、图片着色、风格迁移等。您所需要的只是源数据集和目标数据集(仅仅是图片目录)


设定输入管线
安装 tensorflow_examples 包,以导入生成器和判别器。
导入并重用 Pix2Pix 模型
通过安装的 tensorflow_examples 包导入 Pix2Pix 中的生成器和判别器。
本教程中使用模型体系结构与 pix2pix 中所使用的非常相似。一些区别在于:
Cyclegan 使用 instance normalization(实例归一化)而不是 batch normalization (批归一化)。
CycleGAN 论文使用一种基于
resnet的改进生成器。简单起见,本教程使用的是改进的unet生成器。
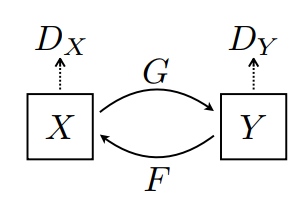
这里训练了两个生成器(G 和 F)以及两个判别器(X 和 Y)。
生成器
G学习将图片X转换为Y。 ParseError: KaTeX parse error: Expected 'EOF', got '&' at position 8: (G: X -&̲gt; Y)生成器
F学习将图片Y转换为X。 ParseError: KaTeX parse error: Expected 'EOF', got '&' at position 8: (F: Y -&̲gt; X)判别器
D_X学习区分图片X与生成的图片X(F(Y))。判别器
D_Y学习区分图片Y与生成的图片Y(G(X))。
损失函数
在 CycleGAN 中,没有可训练的成对数据,因此无法保证输入 x 和 目标 y 数据对在训练期间是有意义的。所以为了强制网络学习正确的映射,作者提出了循环一致损失。
判别器损失和生成器损失和 pix2pix 中所使用的类似。
循环一致意味着结果应接近原始输出。例如,将一句英文译为法文,随后再从法文翻译回英文,最终的结果句应与原始句输入相同。
在循环一致损失中,
图片 通过生成器 传递,该生成器生成图片 。
生成的图片 通过生成器 传递,循环生成图片 。
在 和 之间计算平均绝对误差。
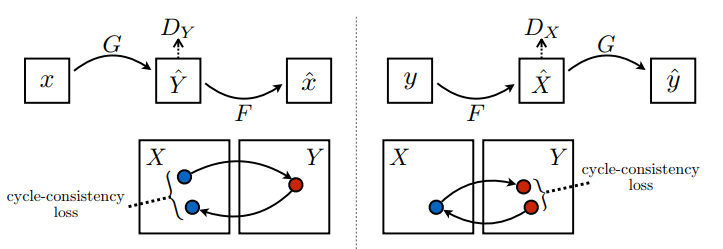
如上所示,生成器 负责将图片 转换为 。一致性损失表明,如果您将图片 馈送给生成器 ,它应当生成真实图片 或接近于 的图片。
如果您在马上运行斑马到马的模型或在斑马上运行马到斑马的模型,那么它不会对图像进行太多修改,因为图像已包含目标类。
为所有生成器和判别器初始化优化器。
Checkpoints
训练
注:此示例模型的训练周期 (10) 少于论文 (200),以保持本教程的训练时间合理。生成的图像质量会低得多。
尽管训练循环看起来很复杂,其实包含四个基本步骤:
获取预测。
计算损失值。
使用反向传播计算损失值。
将梯度应用于优化器。
使用测试数据集进行生成
下一步
本教程展示了如何从 Pix2Pix 教程实现的生成器和判别器开始实现 CycleGAN。 下一步,您可以尝试使用一个来源于 TensorFlow 数据集的不同的数据集。
您也可以训练更多的 epoch 以改进结果,或者可以实现论文中所使用的改进 ResNet 生成器来代替这里使用的 U-Net 生成器。